Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Лихогруд Николай Задание

3
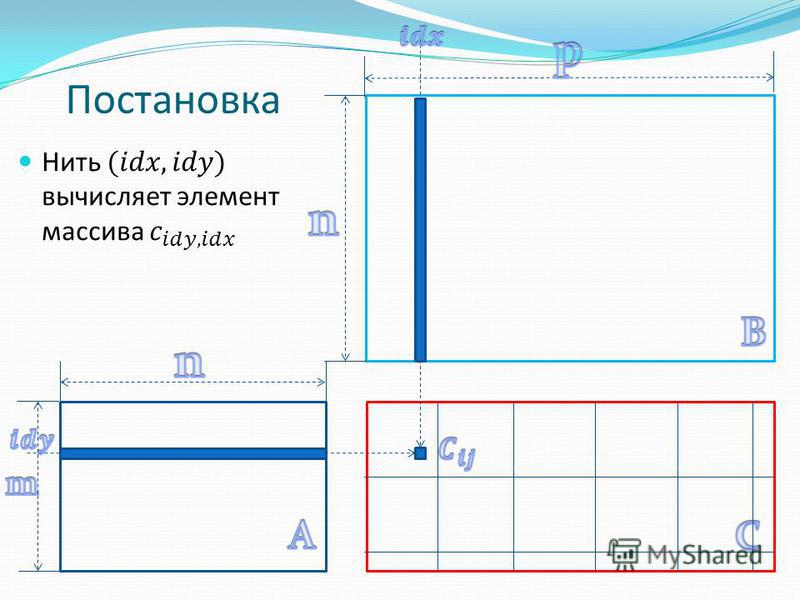
Постановка

5
Грид

6
Ядро __global__ void matmul(A,B,C) { ; if (idx < p && idy < m) { < вычислить скалярное произведение строки idy матрицы A на столбец idx матрицы B >; ; }
 { ; if (idx < p && idy < m) { < вычислить скалярное произведение строки idy матрицы A на столбец idx матрицы B >; ; }")
7
Простаивают Каковы глобальные индексы нити (idx, idy), если индексы нити в блоке - ( threadIdx.x = 22, threadIdx.y = 3 ), индексы блока в гриде - ( blockIdx.x = 3, blockIdx.y = 1 ), размер каждого блока - ( blockDim.x = blockDim.y = 32 ) ? Глобальные индексы ??
, если индексы нити в блоке - ( threadIdx.x = 22, threadIdx.y = 3 ), индексы блока в гриде - ( blockIdx.x = 3, blockIdx.y = 1 ), размер каждого блока - ( blockDim.x = blockDim.y = 32 ) ? Глобальные")
8
Очень вероятно, что вы будете путаться между (i,j) и (x,y) : i – номер строки, соответствует координате по y в терминологии CUDA j – номер столбца, соответствует координате по x Путаница будет оттого что элементу [i,j] в матричной нотации соответствует элемент [y, x] в индексах CUDA (пространственных), но в CUDA первым пишется индекс x Чтобы не путаться, можно глобальные индексы сразу назвать [i,j], а не [idx, idy] Индексы CUDA и матричные
![Очень вероятно, что вы будете путаться между (i,j) и (x,y) : i – номер строки, соответствует координате по y в терминологии CUDA j – номер столбца, соответствует координате по x Путаница будет оттого что элементу [i,j] в матричной нотации соответству](http://images.myshared.ru/10/992851/slide_8.jpg "Очень вероятно, что вы будете путаться между (i,j) и (x,y) : i – номер строки, соответствует координате по y в терминологии CUDA j – номер столбца, соответствует координате по x Путаница будет оттого что элементу [i,j] в матричной нотации соответству")
9
Структура cudaPitchedPtr Определена в CUDA Toolkit: struct cudaPitchedPtr { size_t pitch; // число байтов между началами строк void *ptr; // указатель на память size_t xsize;// логическая ширина матрицы в элементах size_t ysize;// логическая высота матрицы в элементах } cudaPitchedPtr make_cudaPitchedPtr(void *d, size_t p, size_t xsz, size_t ysz) создать такую структуру

10
Вместе с матрицей часто передают её размеры Следует обернуть все матрицы в cudaPitchedPtr С обернутыми матрицами легче будет сделать следующую часть Матрицы плотные, расположены по строкам Число байтов между началами строк (pitch) = * Для матрицы с элементами типа T из m строк и n столбцов: cudaPitchedPtr C = make_cudaPitchedPtr(malloc(n * m * sizeof(T)), n * sizeof(T), n, m); Обертка матриц матриц
 = * Для матрицы с э")
11
get_elem Обращение к элементам матрицы, заданной при помощи cudaPitchedPtr : Type a = ((Type *)((char*)matrix.ptr + Row * matrix.pitch)) [Column]; Удобно определить макрос: #define get_elem(array, Row, Column) \ (((Type*)((char*)array.ptr + (Row) * array.pitch))[(Column)]) Type a = get_elem(array, 2, 10);
![get_elem Обращение к элементам матрицы, заданной при помощи cudaPitchedPtr : Type a = ((Type *)((char*)matrix.ptr + Row * matrix.pitch)) [Column]; Удобно определить макрос: #define get_elem(array, Row, Column) \ (((Type*)((char*)array.ptr + (Row) * a](http://images.myshared.ru/10/992851/slide_11.jpg "get_elem Обращение к элементам матрицы, заданной при помощи cudaPitchedPtr : Type a = ((Type *)((char*)matrix.ptr + Row * matrix.pitch)) [Column]; Удобно определить макрос: #define get_elem(array, Row, Column) \ (((Type*)((char*)array.ptr + (Row) * a")
12
Матрицы прямоугольные, размеры передаются через параметры запуска Тип элементов float, инициализация матриц случайными числами по формуле rand() / RAND_MAX Обернуть ВСЕ матрицы в cudaPitchedPtr, обращаться через get_elem Реализовать возможность проверки правильности результата (по необязательному последнему флагу в параметрах запуска) Вычисление эталонного произведения матриц на хосте и сравнение с результатом CUDA Требование к программе
 / RAND_MAX Обернуть ВСЕ матрицы в cudaPitchedPtr, обращаться через get_elem Реализовать возможность прове")
14
Добавляем padding (набивку) На хосте заменяем cudaMalloc на cudaMallocPitch cudaMemcpy на cudaMemcpy2D На устройстве обращаемся к элементам матриц с учетом их pitch Именно для этого обернули матрицы в cudaPitchedPtr – чтобы не плодить лишних переменных и хранить pitch вместе с указателями
 На хосте заменяем cudaMalloc на cudaMallocPitch cudaMemcpy на cudaMemcpy2D На устройстве обращаемся к элементам матриц с учетом их pitch Именно для этого обернули матрицы в cudaPitchedPtr – чтобы не плодить лишних переменн")
15
cudaMallocPitch & cudaPitchedPtr Выделение памяти под матрицу с элементами типа Type и логическими размерами (в элементах) width x height : cudaPitchedPtr matrix = make_cudaPitchedPtr(0,0, width, height); cudaMallocPitch(&matrix.ptr, &matrix.pitch, width * sizeof( Type ), height); Если Type==int32_t, a width==1000, то будет выделено 4096* height байтов и в matrix.pitch запишется 4096
 width x height : cudaPitchedPtr matrix = make_cudaPitchedPtr(0,0, width, height); cudaMallocPitch(&matrix.ptr, &matrix.pitch, w")
16
cudaMemcpy2D & cudaPitchedPtr Пример пересылки c хоста на GPU: cudaPitchedPtr aHost, aDev; …// выделение памяти под матрицу на GPU и на хосте cudaMemcpy2D( aDev.ptr, aDev.pitch, aHost.ptr, aHost.pitch, aHost.pitch, aHost.ysize, cudaMemcpyHostToDevice); aHost – матрица на хосте, сплошная (без набивки), значит её фактическая ширина(pitch) равна обычной ширине в байтах aDev – матрица на устройстве, память под неё выделена на при помощи cudaMallocPitch, как было описано выше

17
Правильная работа с памятью Каждая нить рассчитывает один элемент матрицы-результата Желательно, чтобы обращения в память нитей одного варпа попадали в промежуток памяти размером 128 байт адрес начала этого промежутка делится на 128 ( выровнен по 128) В этом случае обращения варпа в память будут выполнены за одну транзакцию к кешу L1

18
Нужно ли транспонировать матрицу B? Нужно ли транспонировать матрицу A? При вычислении скалярного произведения нить пробегает столбец матрицы B и строку матрицы A Правильная работа с памятью

19
Пусть ширина каждого блока кратна размеру вар пате. все нити одного варпа лежат в одной строке блока и вычисляют соседние элементы в строке результата Нужно ли транспонировать матрицу B? Нужно ли транспонировать матрицу A?

20
Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 0
![Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 0](http://images.myshared.ru/10/992851/slide_20.jpg "Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 0")
21
Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 0
![Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 0](http://images.myshared.ru/10/992851/slide_21.jpg "Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 0")
22
Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 1
![Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 1](http://images.myshared.ru/10/992851/slide_22.jpg "Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 1")
23
Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 1
![Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 1](http://images.myshared.ru/10/992851/slide_23.jpg "Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 1")
24
Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 2
![Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 2](http://images.myshared.ru/10/992851/slide_24.jpg "Матрицы 10*10, варп 8 нитей a.ptr[idy * a.xsize + k] k = 2")
25
Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 2
![Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 2](http://images.myshared.ru/10/992851/slide_25.jpg "Матрицы 10*10, варп 8 нитей b.ptr[k * b.xsize + idx] k = 2")
26
Матрицы 10*10, варп 8 нитей c.ptr[idy * c.xsize + idx] = tmp
![Матрицы 10*10, варп 8 нитей c.ptr[idy * c.xsize + idx] = tmp](http://images.myshared.ru/10/992851/slide_26.jpg "Матрицы 10*10, варп 8 нитей c.ptr[idy * c.xsize + idx] = tmp")
27
Если ширина блока кратна размеру варпа, то все нити варпа обращаются к одному элементу матрицы А и соседним элементам в строке матрицы B Транспонировать не нужно Нужно ли транспонировать матрицу B? Нужно ли транспонировать матрицу A?

28
Что если ширина блока не кратна размеру варпа? т.е. нити одного варпа лежат не в одной строке блока Нужно ли транспонировать матрицу B? Нужно ли транспонировать матрицу A?

29
Матрицы 10*10, варп 8 нитей, блок 6x2 a.ptr[idy * a.xsize + k] k = 0
![Матрицы 10*10, варп 8 нитей, блок 6x2 a.ptr[idy * a.xsize + k] k = 0](http://images.myshared.ru/10/992851/slide_29.jpg "Матрицы 10*10, варп 8 нитей, блок 6x2 a.ptr[idy * a.xsize + k] k = 0")
30
Матрицы 10*10, варп 8 нитей, блок 6x2 b.ptr[k * b.xsize + idx] k = 0
![Матрицы 10*10, варп 8 нитей, блок 6x2 b.ptr[k * b.xsize + idx] k = 0](http://images.myshared.ru/10/992851/slide_30.jpg "Матрицы 10*10, варп 8 нитей, блок 6x2 b.ptr[k * b.xsize + idx] k = 0")
31
Если ширина блока не кратна размеру варпа, то все нити варпа обращаются к соседним элементам столбца матрицы А и соседним элементам в строке матрицы B Нужно транспонировать матрицу А Нужно ли транспонировать матрицу B? Нужно ли транспонировать матрицу A?

32
Программа должна запускать ядра на устройствах с cudaDeviceProp::major == 2 Память под все матрицы выделять через cudaMallocPitch Выводить время работы ядер Время работы считать через события Реализовать возможность задания высоты блока гряда Требования к программе

33
Таким образом, параметры программы: M, N, K - размеры матриц Высота блоков 16 или 32? Проверять результат? На выходе: Время работы ядра без набивки Время работы ядра с набивкой Требования к программе

34
Результаты тестов

36
Идея Пусть нужно перемножить две «полоски» шириной 32 элемента Пусть размер блока 32 х 32 Делаем два массива в общей памяти с размерами 32 х 32 (наш управляемый кеш) В первый копируем блок матрицы А, во второй – В (закешировали) Вычисляем блок матрицы C используя данные из общей памяти
 В первый копируем блок матрицы А, во второй – В (закешировали) Вычисляем блок матриц")
37
Идея Вычисляем блок матрицы C используя данные из общей памяти В итоге за время работы блока к каждому элементу в глобальной памяти мы обратимся всего один раз Без общей памяти – 32 раза

38
Идея Теперь пусть нужно перемножить матрицы произвольного размера Разрежем их на «полоски» Матрица C есть сумма матриц, получаемых при перемножении соответствующих полосок

39
Идея Матрица C есть сумма матриц, получаемых при перемножении соответствующих полосок Так же делаем 2 массива по 32 х 32 в общей памяти, кэшируем блоки полосок Число этапов – (A.width - 1) / Накапливаем результат
 / 32 + 1 Накапливаем результат")
40
Матрицы произвольного размера Чтобы не возиться с выходом за границы матриц, следует явно дополнить матрицы нулями до размеров, кратных 32 new_width = ((width - 1)/32 + 1) new_height = ((height - 1)/32 + 1)
/32 + 1) new_height = ((height - 1)/32 + 1)")
41
В интернете легко можно найти примеры реализации перемножения матриц с общей памятью, поэтому проведем некоторые оптимизации: Высота блока – 16 нитей Каждая нить вычисляет два элемента: a[i,j] и a[i+16, j] Получается ускорение 1.5x, по сравнению с обычным вариантом По аналогии можно сделать ядра, где каждая нить считает > 2 элементов, которые будут еще эффективнее Оптимизация
![В интернете легко можно найти примеры реализации перемножения матриц с общей памятью, поэтому проведем некоторые оптимизации: Высота блока – 16 нитей Каждая нить вычисляет два элемента: a[i,j] и a[i+16, j] Получается ускорение 1.5x, по сравнению с об](http://images.myshared.ru/10/992851/slide_41.jpg "В интернете легко можно найти примеры реализации перемножения матриц с общей памятью, поэтому проведем некоторые оптимизации: Высота блока – 16 нитей Каждая нить вычисляет два элемента: a[i,j] и a[i+16, j] Получается ускорение 1.5x, по сравнению с об")
42
Общую память выделять динамически Дополнить матрицы нулями до размеров, кратных 32 Для наглядности ускорения добавить в графики из прошлой части: График скорости работы варианта с общей памятью при блоке 32x32, нить вычисляет один элемент График скорости работы варианта с общей памятью при блоке 32x16, нить вычисляет два элемента Требования к программе

43
end

Еще похожие презентации в нашем архиве:



![Лихогруд Николай n.lihogrud@gmail.com Задание. Свертка с квадратным ядром tmp = 0; for(ik=-r..r) for(jk=-r..r) tmp += matrix[i+ik][j+jk]*filter[ik+r][jk+r];](/thumbs/10/976459/big_thumb.jpg "Лихогруд Николай n.lihogrud@gmail.com Задание. Свертка с квадратным ядром tmp = 0; for(ik=-r..r) for(jk=-r..r) tmp += matrix[i+ik][j+jk]*filter[ik+r][jk+r];")





 имеет имя, по которому к ней можно обращаться размер заранее известен.")


![Массивы и строки Лекция 5. Одномерные массивы. Объявление. Общая форма объявления: тип имя_переменной[размер]; Пример: double balance[100]; balance[3]](/thumbs/6/646924/big_thumb.jpg "Массивы и строки Лекция 5. Одномерные массивы. Объявление. Общая форма объявления: тип имя_переменной[размер]; Пример: double balance[100]; balance[3]")



 имеют общее имя(имя массива) и тип (тип элементов.")


![Лекция 9 Функции. Массивы-параметры функции Передача массива в функцию Пример: void array_enter(int a[], int size) { int i; for (i = 0; i < size; i++)](/thumbs/6/756450/big_thumb.jpg "Лекция 9 Функции. Массивы-параметры функции Передача массива в функцию Пример: void array_enter(int a[], int size) { int i; for (i = 0; i < size; i++)")


![АЛГОРИТМЫ НА МАТРИЦАХ. МАССИВЫ В ПРОГРАММЕ ОПИСАНИЕ ОБРАЩЕНИЕ К ЭЛЕМЕНТУ МАССИВА тип имя[размер_1]…[размер_N] СИ имя[индекс_1]…[индекс_N] СИ индекс_i.](/thumbs/6/548895/big_thumb.jpg "АЛГОРИТМЫ НА МАТРИЦАХ. МАССИВЫ В ПРОГРАММЕ ОПИСАНИЕ ОБРАЩЕНИЕ К ЭЛЕМЕНТУ МАССИВА тип имя[размер_1]…[размер_N] СИ имя[индекс_1]…[индекс_N] СИ индекс_i.")
