Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Кафедра общественного здоровья и здравоохранения По дисциплине «Доказательная медицина» Тема: Показатели описательной статистики. лекция 3 для студентов 1 курса, обучающихся Зав. кафедрой ОЗиЗ К.м.н. доц. Шульмин А. В. Красноярск, 2011

2
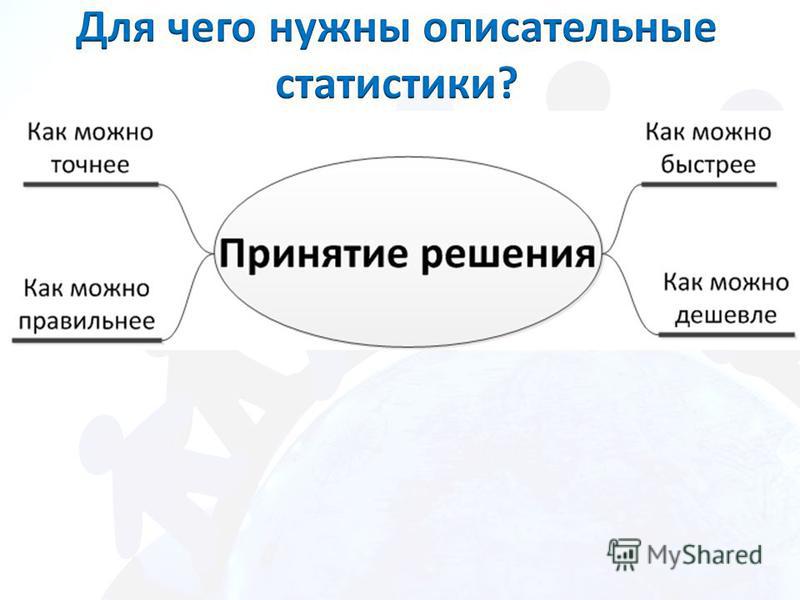
Ознакомление с основными принципами отображения количественных и качественных признаков статистической совокупности.

3
1. Понятие об описательной статистике. 2. Шкалы измерения переменных (качественные и количественные). 3. Относительные величины: виды определение, методы расчета, области применения. 4. Вариационные ряды: определение, структура, виды. 5. Понятие о средних величинах (средняя арифметическая, мода, медиана), их применение в здравоохранении и деятельности врача. 6. Ознакомление с основными видами распределений переменных. 7. Критерии разнообразия признака в совокупности (дисперсия, лимит, амплитуда, среднее квадратичное отклонение, стандартная ошибка коэффициент вариации, перцентили). 8. Понятие о доверительном интервале и доверительной вероятности.
. 3. Относительные величины: виды определение, методы расчета, области применения. 4. Вариационные ряды: определение, структура, виды. 5. Понятие о ср")
5
Анализ информации Анализ в Энциклопедическом словаре: Анализ - (от греч. analysis - разложение) - 1) расчленение (мысленное или реальное) объекта на элементы; анализ неразрывно связан с синтезом(соединением элементов в единое целое). 2) Синоним научного исследования вообще. 3) В формальной логике - уточнение логической формы (структуры)рассуждения.греч. расчленениенеразрывноединое Синонимуточнениеформы
 - 1) расчленение (мысленное или реальное) объекта на элементы; анализ неразрывно связан с синтезом(соединением элементов в единое целое). 2) Синоним научн")
6
Индукция - Логическое умозаключение от частного к общему, от единичного наблюдения к обобщению. Дедукция - Логическое умозаключение, переход от общих положений, законов и т.п. к частному, конкретному выводу.

7
Абсолютные величины – могут быть простыми (имеют именованные единицы измерения сантиметры, дни, случаи заболевания и т. п.) и сложными (выражаются произведениями единиц различной размерности человеко-часы, потерянные годы жизни и т. п.).
 и сложными (выражаются произведениями единиц различной размерности человеко-часы, потерянные годы жизни и т. п.).")
8
Учетные признаки Качественные Количественные Альтернативная (номинальная) шкала (пол) Шкала рангов (порядковая) (стадии болезни) Интервальные (шкала Цельсия) Относительные шкалы (наличие нулевой точки)
 шкала (пол) Шкала рангов (порядковая) (стадии болезни) Интервальные (шкала Цельсия) Относительные шкалы (наличие нулевой точки)")
10
Описательная статистика 1. Меры центральной тенденции 1. Среднее значение (математическое ожидание) 2. Мода 3. Медиана 2. Меры разброса 1. Дисперсия (среднее квадратичное отклонение) 2. Стандартное отклонение 3. Среднее отклонение 4. Квантильные оценки (квартили, децили, процентили) 5.Максимум, минимум и размах выборки
 2. Мода 3. Медиана 2. Меры разброса 1. Дисперсия (среднее квадратичное отклонение) 2. Стандартное отклонение 3. Среднее отклонение 4. Квантильные оцен")
11
Вариационный ряд (frequency table)- ранжированный ряд распределения по величине какого-либо признака. Этот признак носит название варьирующего, а его отдельные числовые значения называются вариантами и обозначаются через V. Число, показывающее, сколько раз данная варианта встречается в вариационном ряду, называется частотой и обозначается через "р"
- ранжированный ряд распределения по величине какого-либо признака. Этот признак носит название варьирующего, а его отдельные числовые значения называются вариантами и обозначаются через V. Число, показывающее, сколь")
12
Высота (V или Х) Частота (Р) Рост студентов
 Частота (Р) Рост студентов")
13
Сжатие (свертка, редукция) статистических данных Статистика – любая функция от вероятностных переменных, порождающих статистические данные. Простейший пример - выборочное среднее: Оно порождается вероятностной переменной: 13
 статистических данных Статистика – любая функция от вероятностных переменных, порождающих статистические данные. Простейший пример - выборочное среднее: Оно порождается вероятностной переменной: 13")
15
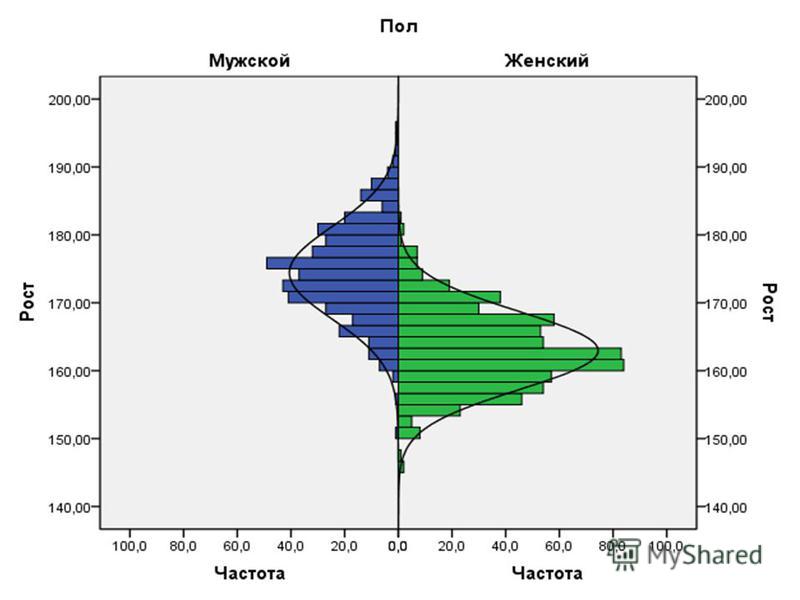
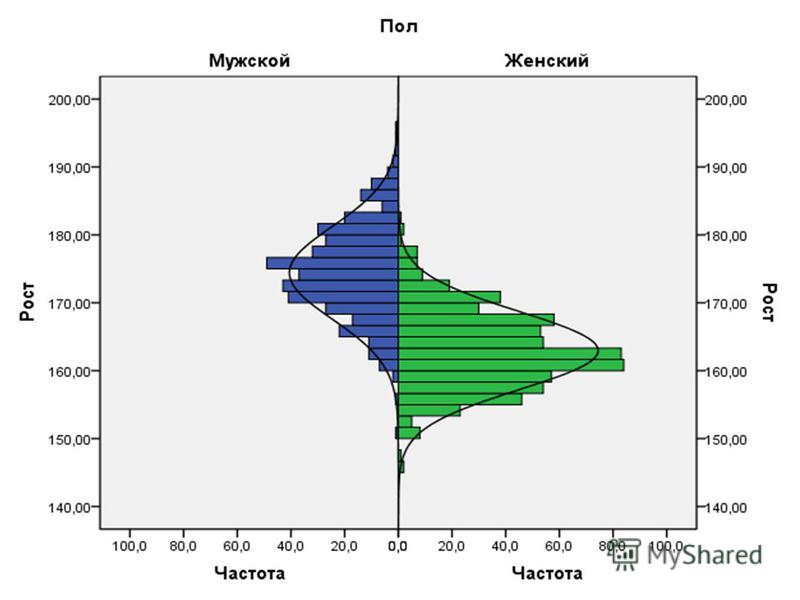
Распределение выборочных средних (sampling distribution of the means) Следствие: некоторая величина отклоняется от среднего под воздействием слабых, независимых друг от друга факторов, Поэтому оно так широко распространено в природе! если некоторая величина отклоняется от среднего под воздействием слабых, независимых друг от друга факторов, она имеет нормальное распределение. Поэтому оно так широко распространено в природе! Пример про высоту деревьев в лесу
 Следствие: некоторая величина отклоняется от среднего под воздействием слабых, независимых друг от друга факторов, Поэтому оно так широко распространено в природе! если некоторая в")
16
Кривая нормального распределения Нормальное (гауссово, симметричное, колоколообразное) распределение – описывает совместное воздействие на изучаемое явление небольшого числа случайно сочетающихся факторов (по сравнению с общей суммой факторов), число которых не ограничено велико. Встречается в природе наиболее часто, за что и получило название «нормального».Характеризует распределение непрерывных случайных величин. Р Х х – значения случайной величины; р – вероятность появления данного значения в совокупности.
 распределение – описывает совместное воздействие на изучаемое явление небольшого числа случайно сочетающихся факторов (по сравнению с общей суммой факторов), число")
18
Критерии нормальности Критерий Шапиро-Уилка (W-test, Shapiro-Wilk test) Разработан в 1965 году, является до сих пор самым мощным тестом на нормальность. Основа – оценка линейности регрессионной кривой на вероятностных графиках. Модификация – критерий Шапиро- Франциа (Shapiro-Francia test)
 Разработан в 1965 году, является до сих пор самым мощным тестом на нормальность. Основа – оценка линейности регрессионной кривой на вероятностных графиках. Модификация – критерий")
19
Определение нормальности распределения 1. По числам Вестергарда при нормальном распределении в пределах: х ± 0.3 σ находится 25 % всех единиц наблюдения; х ± 0.7 σ находится 50 % всех единиц наблюдения; х ± l,l σ находится 75 % всех единиц наблюдения; х ± 3,0 σ находится 99 % всех единиц наблюдения.

20
Асимметрия Эксцесс

21
Три ОСНОВНЫЕ ХАРАКТЕРИСТИКИ, которыми можно почти полностью описать большинство распределений 1.«Середина» распределения; 2.«Ширина» распределения; 3. Форма распределения Как описать частотное распределение переменной? Речь идёт не только о количественных данных, но и о качественных

22
«Середина» распределения «Середина» Мода (mode) Медиана (median) Среднее значение (mean) Разница понятий parameter и statistic Все они могут служить оценками популяционного среднего. Среднее в выборке – наиболее эффективная и несмещённая оценка.
 Медиана (median) Среднее значение (mean) Разница понятий parameter и statistic Все они могут служить оценками популяционного среднего. Среднее в выборке – наиболее эффективная и несмещённая оценка.")
23
Частотное распределение переменной (frequency distribution) «Середина» распределения Среднее значение – сумма всех значений переменной, делённая на количество значений *«balancing point» method Среднее для выборки Среднее для популяции
 «Середина» распределения Среднее значение – сумма всех значений переменной, делённая на количество значений *«balancing point» method Среднее для выборки Среднее для популяции")
24
Частотное распределение переменной (frequency distribution) «Середина» распределения Медиана (median)– значение, которое делит распределение пополам ( его площадь в т.ч.): половина значений больше медианы, половина – не больше. 1,01,54,15,79,5 6,0 7,17,910,411,0 Медиана Имеет смысл не только для количественных переменных, но и для ранговых! (не для качественных). 3,2
 «Середина» распределения Медиана (median)– значение, которое делит распределение пополам ( его площадь в т.ч.): половина значений больше медианы, половина – не больше. 1,01,54,15,79,5 6,0 7,")
26
Частотное распределение переменной (frequency distribution) «Ширина» распределения = Разброс* Размах (range) Стандартное отклонение (standard deviation) Дисперсия (variance) * Это лишь основные параметры разброса Размах (range) – разность между максимальным и минимальным значениями = X n – X 1 Хорош тем, что легко считается и имеет «биологический смысл». Плох тем, что зависит лишь от 2-х точек из распределения. Недооценивает истинный размах в популяции. Если в статье приводится размах, следует привести ещё какую-нибудь характеристику разброса.
 «Ширина» распределения = Разброс* Размах (range) Стандартное отклонение (standard deviation) Дисперсия (variance) * Это лишь основные параметры разброса Размах (range) – разность между макси")
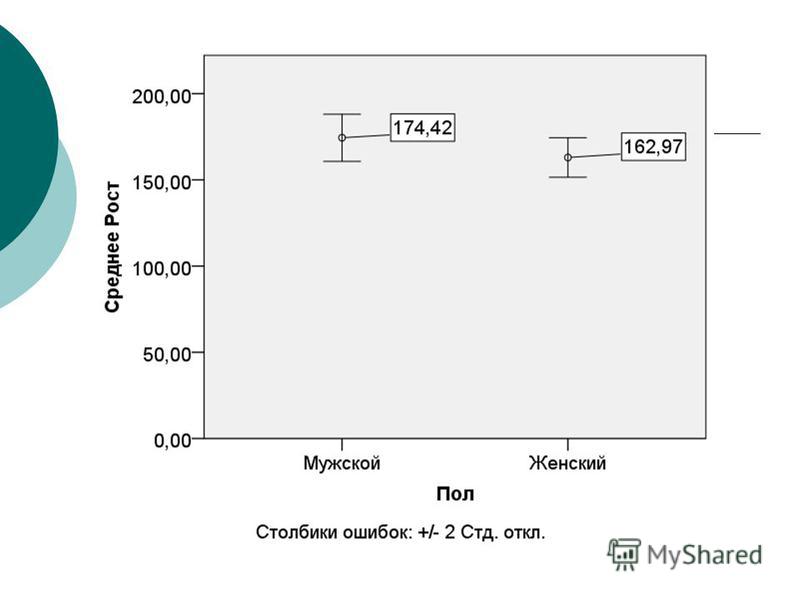
27
Основные характеристики нормального распределения Среднее арифметическое значение (М) Стандартное (среднеквадратическое) отклонение (σ) Количество наблюдение (n)
 Стандартное (среднеквадратическое) отклонение (σ) Количество наблюдение (n)")
28
68.3 % всех вариант отклоняются от своей средней не более, чем на σ 95.4% вариант находятся в пределах X ± 2σ 99.7% вариант находятся в пределах X ± 3σ. Отклонение параметра от его средней арифметической в пределах σ расценивается как норма, субнормальным считается отклонение в пределах ± 2σ и патологическим - сверх этого предела, т.е. > ± 2σ" (рис. ) Правило «трех сигм» ( SD – стандартное отклонение)

29
На тощак 3,3 -5,5 ммоль/л После еды 3,3 – 7,8 ммоль/л. Критическая точка 11,0 ммоль/л Критическая точка 6,1 ммоль/л 4, 4±0,55 ммоль/л 5,55±1,125 ммоль/л

31
Частотное распределение переменной (frequency distribution) «Середина» распределения Мода, медиана и среднее СОВПАДАЮТ для симметричного унимодального распределения К появлению перекоса чувствительнее всего среднее значение ЗАРПЛА ТА, $ ЧАСТ ОТА /32/3
 «Середина» распределения Мода, медиана и среднее СОВПАДАЮТ для симметричного унимодального распределения К появлению перекоса чувствительнее всего среднее значение ЗАРПЛА ТА, $ ЧАСТ ОТА 2000")
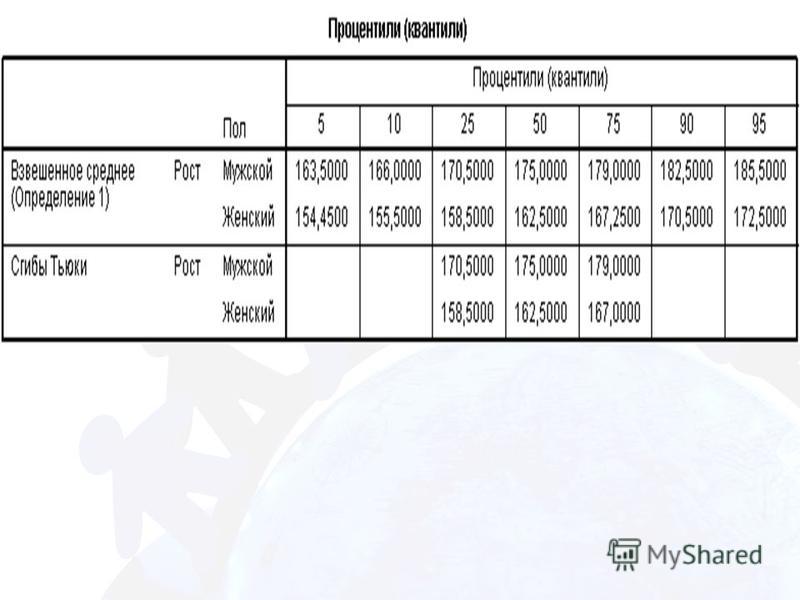
32
Название квантилей Число частей, на которые разбивается ряд Медиана 2 Терциль 3 Квартиль 4 Дециль 10 Процентиль 100 Вариационный ряд можно разбивать на отдельные (по возможности равные) части, которые называются квантилями (quantile). Наиболее часто употребляемые квантили:
 части, которые называются квантилями (quantile). Наиболее часто")
34
Ящичная диаграмма

37
Основные характеристики нормального распределения Среднее арифметическое значение (М) Стандартное (среднеквадратическое) отклонение (σ) Количество наблюдение (n)
 Стандартное (среднеквадратическое) отклонение (σ) Количество наблюдение (n)")
38
Распределение выборочных средних (sampling distribution of the means) Три основные концепции в анализе данных: 1. Что такое РАСПРЕДЕЛЕНИЕ переменной и как его описывать 2. Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ и как оно связано с распределением переменной 3. Что такое СТАТИСТИКА КРИТЕРИЯ выборка популяция
 Три основные концепции в анализе данных: 1. Что такое РАСПРЕДЕЛЕНИЕ переменной и как его описывать 2. Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ и как оно связано с распределением")
39
Распределение выборочных средних (sampling distribution of the means) Ещё раз центральный статистический вопрос: что мы можем сказать обо всей ПОПУЛЯЦИИ, если всё, что у нас есть, это лишь ВЫБОРКА из неё? На 1-м курсе института 25 групп по 22 студента. Средняя масса студента – μ=50 кг, σ = 4 кг. Посчитаем средние массы для каждой группы! Форма распределений маленьких выборок не обязательна должна удовлетворять критериям нормального распределения. …..
 Ещё раз центральный статистический вопрос: что мы можем сказать обо всей ПОПУЛЯЦИИ, если всё, что у нас есть, это лишь ВЫБОРКА из неё? На 1-м курсе института 25 групп по 22 студент")
40
Распределение выборочных средних (sampling distribution of the means) Мы посчитали средние массы студентов в КАЖДОЙ группе, и теперь построим распределение из этих СРЕДНИХ значений! Оно будет намного УЖЕ распределения всех студентов 1-го курса, и УЖЕ, чем каждое из распределений из отдельных групп Это и будет распределение выборочных средних (sampling distribution of the means) Пример про бутылки с кока-колой
 Мы посчитали средние массы студентов в КАЖДОЙ группе, и теперь построим распределение из этих СРЕДНИХ значений! 50 5 55604540 50 1.2 Оно будет намного УЖЕ распределения всех студен")
41
Распределение выборочных средних (sampling distribution of the means) s Распределение выборочных средних Выборка (группа) Популяция (1-й курс) среднее стандартное отклонение >> Стандартная ошибка среднего (Standard error = SE)
 s Распределение выборочных средних Выборка (группа) Популяция (1-й курс) среднее стандартное отклонение >> Стандартная ошибка среднего (Standard error = SE)")
42
Распределение выборочных средних (sampling distribution of the means) ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА Определяет форму, среднее и разброс в распределении выборочных средних Форма: с увеличение размера выборок (групп) распределение выборочных средних приближается к нормальному распределению (независимо от формы распределения популяции). Среднее: среднее значение в распределении средних равно среднему значению в популяции, т.е., Разброс: распределение выборочных средних Уже распределения популяции на, где n – объём выборки, т.е. Пример с монеткой
 ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА Определяет форму, среднее и разброс в распределении выборочных средних Форма: с увеличение размера выборок (групп) распределение выборочных средних п")
43
Распределение выборочных средних (sampling distribution of the means) У нас есть только одна выборка. Из неё мы получили среднее значение Насколько оно близко среднему значению в популяции ( μ )? Мы знаем, что для нормального распределения есть z-оценка, значениям которой соответствуют определённые площади распределения. Но мы также знаем, что выборочные средние образуют нормальное распределение!! Это значит, что, зная среднее в популяции, мы можем предсказать (с … вероятностью) интервал, в который попадёт выборочное среднее. Решим обратную задачу. Пусть нам известно μ, найдём
 У нас есть только одна выборка. Из неё мы получили среднее значение Насколько оно близко среднему значению в популяции ( μ )? Мы знаем, что для нормального распределения есть z-оце")
44
Распределение выборочных средних (sampling distribution of the means) Z - оценка Z - оценка Вопрос: какая часть ОСОБЕЙ имеет массу больше 55 кг? Другой вопрос: какая часть ВЫБОРОК имеет СРЕДНЮЮ массу больше 55 кг?
 0 5 12-2Z - оценка 0 1.2 Z - оценка Вопрос: какая часть ОСОБЕЙ имеет массу больше 55 кг? Другой вопрос: какая часть ВЫБОРОК имеет СРЕДНЮЮ массу больше 55 кг?")
45
Оценка параметров популяции на основе свойств выборки Пусть мы изначально знаем среднюю массу студентов 1-го курса и стандартное отклонение в популяции. Как оценить среднюю массу в одной из групп? Построим распределение выборочных средних! Вспомним, что оно – нормальное, а его среднее значение соответствует среднему в популяции μ Зная стандартное отклонение в нем (=SE!!) можем рассчитать интервал, в который попадёт 95% (99%) всех средних масс в группах:

46
Оценка параметров популяции на основе свойств выборки 95% доверительный интервал (95% confidence interval): интервал значений переменной, который с вероятностью 95% содержит нужный параметр. Т.е., расстояние от среднего значения в популяции до выборочного среднего для 95% выборок не больше 1.96 SE Вернёмся к исходной задаче: Как оценить среднюю массу в популяции, если нам известно среднее в выборке?? Расстояние от среднего в выборке до (неизвестного) среднего в популяции с вероятностью 95% не больше 1.96 SE cv – critical value, критическое значение статистики (в данном случае, Z)
: интервал значений переменной, который с вероятностью 95% содержит нужный параметр. Т.е., расстояние от среднего значения в популяции до выборо")
47
Оценка параметров популяции на основе свойств выборки Вопрос: где расположено μ? Ответ: я точно не знаю, но наиболее вероятно – в пределах ± 2-х стандартных ошибок среднего (SE) Чем больше уровень достоверности – 99%, 99,9%... (= доверительный уровень) тем ШИРЕ будет интервал Вопрос: где расположено μ? Ответ: я совершенно уверен, что оно лежит в пределах... от до В примере нам было известно σ, но на практике оно обычно неизвестно!
 Чем больше уровень достоверности – 99%, 99,9%... (= доверительный уровен")
48
Оценка параметров популяции на основе свойств выборки Мы не знаем стандартное отклонение в популяции, и оцениваем его через стандартное отклонение в выборке – поэтому, доверительный интервал должен быть ШИРЕ, чем при известном σ. Насколько шире? Это будет зависеть от РАЗМЕРА ВЫБОРКИ (от числа степеней свободы df = n-1) df Пояснить про число степеней свободы

51
Доверительные интервалы для долей Доверительный интервал (confidence interval) для доли – это диапазон значений, в пределах которого с заданной вероятностью (обычно 95%) находится истинная популяционная доля. Для достаточно больших выборок распределение выборочных долей можно считать нормальным. Тогда: Доверительный интервал для доли: ДИ=p±zs p
 для доли – это диапазон значений, в пределах которого с заданной вероятностью (обычно 95%) находится истинная популяционная доля. Для достаточно больших выборок распределе")
52
Доверительные интервалы для долей Доверительные интервалы для долей, рассчитанные выше, являются лишь приблизительными. Точные доверительные интервалы рассчитываются, исходя из биномиального распределения. Вручную их можно определить по специальным номограммам, а на практике – в компьютерных статистических пакетах. Доверительные интервалы должны в обязательном порядке указываться для всех переменных при описании данных.

53
Доверительные интервалы для долей Пример: Исследователь указывает, что он исследовал 10 больных до и после лечения. Затем в таблице мы увидим, что до лечения боли в животе были у 70%, а после лечения – лишь у 20%. Данные выглядят очень убедительно - различия составляют 50%!. Теперь укажем доверительные интервалы: - До лечения - 70% (35% - 93%), после лечения - 20% (25% - 56%). Доверительные интервалы даже перекрываются! Поэтому проверим значимость различий: различия действительно значимы (p=0.02). Применение доверительных интервалов показывает, какой диапазон значений может принимать показатель в популяции, а не в конкретной выборке.

54
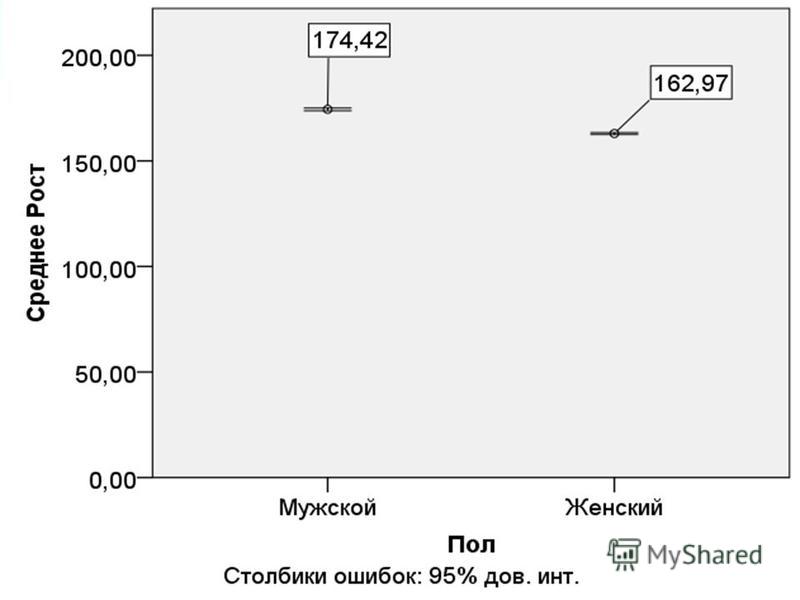
Доверительные интервалы для долей График без доверительных интервалов – дает представление только о выборке, изученной исследователем.

55
Доверительные интервалы для долей Тот же график, но уже с границами доверительных интервалов – диапазон, который могут принимать истинные значения в популяции.

56
Заголовок слайда р - величина показателя изучаемого признака; q - (100-p); t - доверительный коэффициент, показывающий какова вероятность того, что размеры показателя не будут выходить за границы предельной ошибки (обычно берется t = 2, что обеспечивает 95% вероятность безошибочного прогноза); предельная ошибка показателя.
; t - доверительный коэффициент, показывающий какова вероятность того, что размеры показателя не будут выходить за границы предельной ошибки (обычно берется t = 2, что обеспеч")
57
57 σ показатель вариабельности признака (среднеквадратическое отклонение), который можно получить из предыдущих исследований либо на основании пробных (пилотажных) исследований.
, который можно получить из предыдущих исследований либо на основании пробных (пилотажных) исследований.")
58
Выводы: Таким образом мы рассмотрели: понятие об описательной статистике, шкалы измерения переменных, относительные величины, вариационные ряды, понятие о средних величинах, критерии разнообразия признака в совокупности, понятие о доверительном интервале и доверительной вероятности.

59
Рекомендованная литература по теме занятия: - обязательная; Павлушков И.В. Основы высшей математики и математической статистики: Учебник для мед. вузов - дополнительная; 1. А. Петри, К. Сэбин Наглядная медицинская статистика. – М.: ГЭОТАР- Медиа, – С Зайцев В. М., Лифляндский В. Г., Маринкин В. И. Прикладная медицинская статистика: Учебное пособие. - СПб.: Фолиант, – С

60
Благодарю за внимание

Еще похожие презентации в нашем архиве:







. Мода, медиана, среднее 2.Меры вариации.")

















