Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Лихогруд Николай Часть третья

3
Разделяемая(общая) память Расположена в том же устройстве, что и кеш L1 Совместно используется (разделяется) всеми нитями виртуального блока Если на мультипроцессоре работает несколько блоков – общая память делится между ними поровну У каждого блока своё адресное пространство общей памяти Конфигурации: 16КB общая память, 48KB L1 48КB общая память, 16KB L1 – по умолчанию Device Memory L2 cache Device SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache
 память Расположена в том же устройстве, что и кеш L1 Совместно используется (разделяется) всеми нитями виртуального блока Если на мультипроцессоре работает несколько блоков – общая память делится между ними поровну У каждого блока")
4
Разделяемая(общая) память Device Memory L2 cache Device SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache Возможные обмены между устройствами при обработке обращений в глобальную память Возможные обмены между устройствами при обработке обращений в общую память
 память Device Memory L2 cache Device SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache SM Shared & L1 cache Shared & L1 cache Возможные обмены между устройствами при обработке обращений в глобальную памя")
5
Выделение общей памяти В GPU коде объявляем статический массив или переменную с атрибутом __shared__ #define SIZE 1024 __global__ void kernel() { __shared__ int array[SIZE]; //массив __shared__ float varSharedMem; //переменная … }
![Выделение общей памяти В GPU коде объявляем статический массив или переменную с атрибутом __shared__ #define SIZE 1024 __global__ void kernel() { __shared__ int array[SIZE]; //массив __shared__ float varSharedMem; //переменная … }](http://images.myshared.ru/10/981152/slide_5.jpg "Выделение общей памяти В GPU коде объявляем статический массив или переменную с атрибутом __shared__ #define SIZE 1024 __global__ void kernel() { __shared__ int array[SIZE]; //массив __shared__ float varSharedMem; //переменная … }")
6
Особенности использования Переменные с атрибутом __shared__ с точки зрения программирования: Существуют только на время жизни блока недоступны с хоста или из других блоков Индивидуальны для каждого блока и привязаны к его личному пространству общей памяти каждый блок нитей видит «своё» значение Не могут быть проинициализированы при объявлении

7
__global__ void kernel() { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * sizeof(float); memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } memoryOnDevice[thredIdx.x] = …; …// использование указателя всеми нитями блока } Раздача указателя нитям блока
 { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * sizeof(float); memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } memoryOnDevice")
8
__global__ void kernel() { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * sizeof(float); memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } ?? memoryOnDevice[thredIdx.x] = …; …// использование указателя всеми нитями блока } Раздача указателя нитям блока Нужна синхронизация!
 { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * sizeof(float); memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } ?? memoryOnDev")
9
Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Записывает __sinf от своего индекса в соответствующую ей ячейку массива Читает из массива элемент, записанный соседней нитью
![Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Зап](http://images.myshared.ru/10/981152/slide_9.jpg "Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Зап")
10
Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Варпы выполняются в непредсказуемом порядке Может получиться, что нить ещё не записала элемент, соседняя уже пытается его считать! read-after-write, write-after-read, write-after-write конфликты
![Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Варпы выполняют](http://images.myshared.ru/10/981152/slide_10.jpg "Синхронизация Рассмотрим пример ядра, запускаемого на одномерном линейном гриде: __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Варпы выполняют")
11
Синхронизация Явная синхронизация нитей одного блока void __syncthreads(); При вызове этой функции нить блокируется до момента, когда: все нити в блоке достигнут данную точку результаты всех инициированных к данному моменту операций с глобальной\общей памятью, станут видны всем нитям блока
; При вызове этой функции нить блокируется до момента, когда: все нити в блоке достигнут данную точку результаты всех инициированных к данному моменту операций с глобальной\обще")
12
Синхронизация __syncthreads() можно вызывать в ветвях условного оператора только если результат его условия одинаков во всех нитях блока, иначе выполнение может зависнуть или стать непредсказуемым
 можно вызывать в ветвях условного оператора только если результат его условия одинаков во всех нитях блока, иначе выполнение может зависнуть или стать непредсказуемым")
13
Синхронизация __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); __syncthreads(); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Записывает __sinf от своего индекса в соответствующую ей ячейку массива Ожидает завершения операций в других нитях Читает из массива элемент, записанный соседней нитью
![Синхронизация __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); __syncthreads(); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Записывает __sinf от своего индекса в соответствующую](http://images.myshared.ru/10/981152/slide_13.jpg "Синхронизация __global__ void kernel() { __shared__ int shmem[BLOCK_SIZE]; shmem[threadIdx.x] = __sinf(threadIdx.x); __syncthreads(); int a = shmem[(threadIdx.x + 1 )% BLOCK_SIZE]; … } Каждая нить Записывает __sinf от своего индекса в соответствующую")
14
__global__ void kernel() { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * 64; memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } __syncthreads(); …// использование указателя всеми нитями блока } Раздача указателя нитям блока Нужна синхронизация!
 { __shared__ int *memoryOnDevice; if (threadIdx.x == 0) { // выделяет память только первая нить size_t size = blockDim.x * 64; memoryOnDevice = (int *)malloc(size); memset(memoryOnDevice, 0, size); } __syncthreads(); …// испо")
15
Бывают ситуации, когда нужный размер общей памяти не известен на этапе компиляции Зависит от размер задачи, блока и т.д. В этом случае выделить память как статическую переменную невозможно Можно указать требуемый размер общей памяти при запуске ядра Динамическая общая память

16
В GPU коде объявляем указатель для доступа к общей памяти: __global__ void kernel() { extern __shared__ int array[]; … } В третьем параметре конфигурации запуска указываем сколько общей памяти нужно выделить каждому блоку kernel >>(params) Динамическая общая память
![В GPU коде объявляем указатель для доступа к общей памяти: __global__ void kernel() { extern __shared__ int array[]; … } В третьем параметре конфигурации запуска указываем сколько общей памяти нужно выделить каждому блоку kernel >>(params) Динамическ](http://images.myshared.ru/10/981152/slide_16.jpg "В GPU коде объявляем указатель для доступа к общей памяти: __global__ void kernel() { extern __shared__ int array[]; … } В третьем параметре конфигурации запуска указываем сколько общей памяти нужно выделить каждому блоку kernel >>(params) Динамическ")
17
Все переменные extern __shared__ type var[] указывают на одно и то же начало динамической общей памяти, выделенной блоку Ядру может быть одновременно выделена статическая, и динамическая память. Если суммарный объем динамической и статической памяти превышает 48 кб на блок – произойдет ошибка запуска
![Все переменные extern __shared__ type var[] указывают на одно и то же начало динамической общей памяти, выделенной блоку Ядру может быть одновременно выделена статическая, и динамическая память. Если суммарный объем динамической и статической памяти](http://images.myshared.ru/10/981152/slide_17.jpg "Все переменные extern __shared__ type var[] указывают на одно и то же начало динамической общей памяти, выделенной блоку Ядру может быть одновременно выделена статическая, и динамическая память. Если суммарный объем динамической и статической памяти")
18
Стратегия использования Общая память по смыслу является кешем, управляемым пользователем Имеет низкую латентность - расположена на том же оборудовании, что и кеш L1, скорость загрузки сопоставима с регистрами Приложение явно выделяет и использует общую память Пользовать сам выбирает что, как и когда в ней хранить Шаблон доступа может быть произвольным, в отличие от L1

19
Стратегия использования Типичная стратегия использования: Нити блока коллективно 1. Загружают данные из глобальной памяти в общую Каждая нить делает часть этой загрузки 2. Синхронизуются Чтобы никакая нить не начинала чтение данных, загружаемых другой нитью, до завершения их загрузки 3. Используют загруженные данные для вычисления результаты Если нити что-то пишут в общую память, то также может потребоваться синхронизация 4. Записывают результаты обратно в глобальную память

20
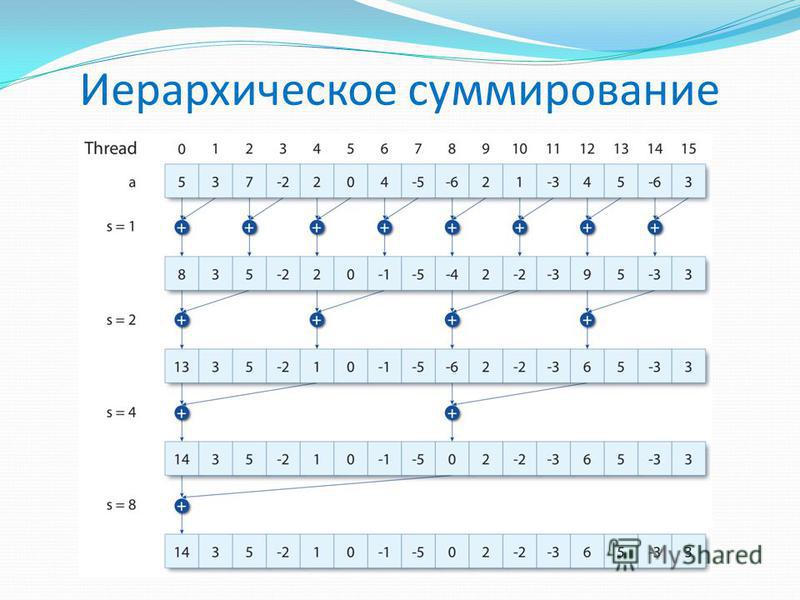
Редукция Блоку нитей сопоставляем часть массива Каждый блок нитей суммирует элементы из своей части массива Блок нитей Копирует данные в общую память Иерахически суммирует данные в общей памяти Сохраняет результат в глобальной памяти

21
Иерархическое суммирование

23
Ядро суммирования __global__ void reduce (int *inData, int *outData) { __shared__ int data [BLOCK_SIZE]; int tid = threadIdx.x; int i = blockIdx.x * blockDim.x + threadIdx.x data [tid] = inData [i]; __syncthreads (); for ( int s = 1; s < blockDim.x; s *= 2) { if (tid % (2*s) == 0) { data [tid] += data [tid + s]; } __syncthreads (); } if (tid == 0) { outData [blockIdx.x] = data [0]; }
![Ядро суммирования __global__ void reduce (int *inData, int *outData) { __shared__ int data [BLOCK_SIZE]; int tid = threadIdx.x; int i = blockIdx.x * blockDim.x + threadIdx.x data [tid] = inData [i]; __syncthreads (); for ( int s = 1; s < blockDim.x;](http://images.myshared.ru/10/981152/slide_23.jpg "Ядро суммирования __global__ void reduce (int *inData, int *outData) { __shared__ int data [BLOCK_SIZE]; int tid = threadIdx.x; int i = blockIdx.x * blockDim.x + threadIdx.x data [tid] = inData [i]; __syncthreads (); for ( int s = 1; s < blockDim.x;")
25
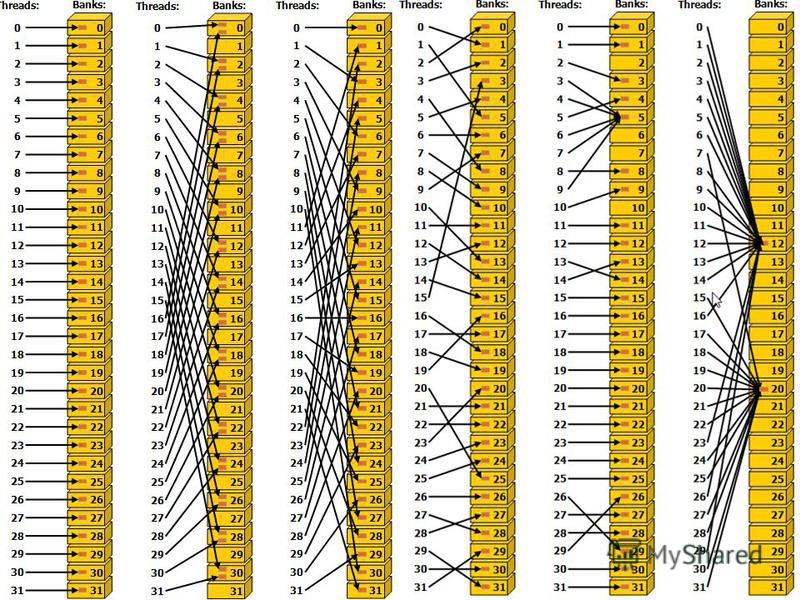
Банки общей памяти Для увеличения полосы пропускания устройство, на котором расположена общая память, разделено на подмодули («банки») n – число банков m – сколько последовательных байтов может отдать каждый банк за цикл Адресное пространство общей памяти разделено на n непересекающихся подмножеств, расположенных в разных банках Банки работают независимо друг-от-друга и могут вместе выдать максимум n*m байтов за один цикл
 n – число банков m – сколько последовательных байтов может отдать каждый банк за цикл Адресное пространство общей п")
26
Банки общей памяти на Fermi 32 банка, каждый банк может выдать за 2 такта ядер одно 32- битное слово (4 последовательных байта) Последовательные 32-битные слова располагаются в последовательных банках Номер банка для слова по адресу addr: (addr / 4) % 32 За два такта ядер общая память может отдать 128 байт
 Последовательные 32-битные слова располагаются в последовательных банках Номер банка для слова по адресу addr: (addr / 4)")
27
… … Банк 0Банк … Банк Банк 0Банк 1Банк 2Банк 3… 04812… … … ……………

28
Обращения в общую память Обращение выполняется одновременно всеми нитями варпа (SIMT) Банки работаю параллельно Если варпу нитей нужно получить 32 4-байтных слова, расположенных в разных банках, то такой запрос будет выполнен одновременно всеми банками Каждый банк выдаст соответствующее слово Пропускная способность = 32 х пропускная способность банка Поддерживается рассылка (broadcast): Если часть нитей (или все) обращаются к одному и тому же 4-х байтному слову, то нужное слово будет считано из банка и роздано соответствующим нитям (broadcast) без накладных расходов
 Банки работаю параллельно Если варпу нитей нужно получить 32 4-байтных слова, расположенных в разных банках, то такой запрос будет выполнен одновременно всеми банка")
29
Банк конфликты Если хотя бы два нужных варпу слова расположены в одном банке, то такая ситуация называется «банк конфликтом» и обращение в глобальную память будет «сериализованно»: Такое обращение аппаратно разбивается на серию обращений, не содержащих банк конфликтов Если число обращений, на которое разбит исходный запрос, равно n, то такая ситуация называется банк-конфликтом порядка n Пропускная способность при этом падает в n раз

30
Банки общей памяти на Kepler 32 банка, каждый банк может выдать за 1 такт ядер 8 байтов На Kepler частота ядер в 2 раза меньше, чем на Fermi Два режима разбиения общей памяти на банки: Последовательные 32-битные слова располагаются в последовательных банкаx: (addr / 4) % 32 Последовательные 64-битные слова располагаются в последовательных банках: (addr / 8) % 32 За два такта ядер общая память может отдать 256 байт

31
Банк 0Банк 1Банк 2Банк 3… … … … …………… Последовательные 32- битные слова в последовательных банкаx … … Банк 0Банк … Банк

32
Банк 0Банк 1Банк 2Банк 3… … … … …………… Последовательные 64- битные слова в последовательных банкаx … … Банк 0Банк … Банк

33
Банк 0Банк 1Банк 2Банк 3… … … … …………… Банк 0Банк 1Банк 2Банк 3… … … … …………… Могут быть отданы банком 0 за один такт* *Каждая ячейка соответствует 4-м последовательным байтам Последовательные 32-битные слова в последовательных банкаx Последовательные 64-битные слова в последовательных банкаx

34
Банк конфликты на Kepler Последовательные 32-битные слова располагаются в последовательных банкаx: Банк-конфликта между двумя нитями нет, если запрашиваются байты 32- битных слов из разных банков, либо запрашиваемые слова находятся в 32- битных словах с адресами i и i + 128, 256*n

35
Установка режима общей памяти cudaError_t cudaDeviceSetSharedMemConfig ( cudaSharedMemConfig config ) Глобально для всех запусков ядер cudaSharedMemBankSizeDefault - последовательные 32-битные слова в последовательных банкаx cudaSharedMemBankSizeFourByte - последовательные 32-битные слова в последовательных банкаx cudaSharedMemBankSizeEightByte - последовательные 64-битные слова в последовательных банка x cudaError_t cudaFuncSetSharedMemConfig ( const void* func, cudaSharedMemConfig config ) Для запусков конкретного ядра
 Глобально для всех запусков ядер cudaSharedMemBankSizeDefault - последовательные 32-битные слова в последовательных банкаx cudaSharedMemBankSizeFour")
36
Зачем устанавливать режим extern __shared__ double arr[]; double res = sin(arr[thredIdx.x * 3]); Нить 0 обращается к байту со смещением 0, нить 16 – 384 cudaSharedMemBankSizeFourByte Оба обращения попадают в один банк, банк-конфликт второго порядка cudaSharedMemBankSizeEightByte Обращения попадают в банки 0 и 16, банк-конфликта нет
![Зачем устанавливать режим extern __shared__ double arr[]; double res = sin(arr[thredIdx.x * 3]); Нить 0 обращается к байту со смещением 0, нить 16 – 384 cudaSharedMemBankSizeFourByte Оба обращения попадают в один банк, банк-конфликт второго порядка c](http://images.myshared.ru/10/981152/slide_36.jpg "Зачем устанавливать режим extern __shared__ double arr[]; double res = sin(arr[thredIdx.x * 3]); Нить 0 обращается к байту со смещением 0, нить 16 – 384 cudaSharedMemBankSizeFourByte Оба обращения попадают в один банк, банк-конфликт второго порядка c")
38
Банк конфликты второго порядка

39
Примеры банк-конфликтов extern __shared__ float char[]; float data = shared[BaseIndex + s * threadIx.x];// конфликты зависят от s Нити threadIx.x и (threadIx.x + n) обращаются к элементам из одного и того же банка когда s*n делится на 32 (число банков). S = 1 : shared[BaseIndex + threadIx.x] // нет конфликта S = 2 : shared[BaseIndex + 2*threadIx.x] // конфликт 2-го порядка Например, между нитями threadIx.x=0 и (threadIx.x = 16) – попадают в один варп!
![Примеры банк-конфликтов extern __shared__ float char[]; float data = shared[BaseIndex + s * threadIx.x];// конфликты зависят от s Нити threadIx.x и (threadIx.x + n) обращаются к элементам из одного и того же банка когда s*n делится на 32 (число банко](http://images.myshared.ru/10/981152/slide_39.jpg "Примеры банк-конфликтов extern __shared__ float char[]; float data = shared[BaseIndex + s * threadIx.x];// конфликты зависят от s Нити threadIx.x и (threadIx.x + n) обращаются к элементам из одного и того же банка когда s*n делится на 32 (число банко")
40
Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0;
![Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0;](http://images.myshared.ru/10/981152/slide_40.jpg "Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0;")
41
Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка
![Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка](http://images.myshared.ru/10/981152/slide_41.jpg "Распространенная проблема Пусть в общей памяти выделена плоская плотная матрица шириной, кратной 32, и соседние нити варпа обращаются к соседним элементам столбца __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка")
42
Распространенная проблема __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка Решение: набивка __shared__ int matrix[32][32 + 1] matrix[thredIdx.x][4] = 0; //нет конфликта
![Распространенная проблема __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка Решение: набивка __shared__ int matrix[32][32 + 1] matrix[thredIdx.x][4] = 0; //нет конфликта](http://images.myshared.ru/10/981152/slide_42.jpg "Распространенная проблема __shared__ int matrix[32][32] matrix[thredIdx.x][4] = 0; Банк конфликт 32-го порядка Решение: набивка __shared__ int matrix[32][32 + 1] matrix[thredIdx.x][4] = 0; //нет конфликта")
43
Распространенная проблема Пусть банков 10, матрица 10 х 10

44
Транспонирование матрицы __global__ void simpleTranspose(ElemType *inputMatrix, ElemType *outputMatrix, int width, int height) { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; if ( i < height && j < width) { outputMatrix[j * (height) + i] = inputMatrix[ i * (width) + j]; } Нити варпа записывают элементы столбца 32 транзации на одну запись
 { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; if ( i < height && j < widt")
45
Транспонирование через общую память Считать плитку матрицы в общую память Записать в результат транспонированную плитку Нити варпа читают столбец плитки в общей памяти и пишут строку в транспонированной матрице Нити варпа читают строку плитки из исходной матрицы

46
__global__ void shmemTranspose( ElemType *inputMatrix, ElemType *outputMatrix, int width, int height) { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; __shared__ ElemType shmem[32][32]; if ( i < height && j < width) { shmem[threadIdx.y][threadIdx.x] = inputMatrix[i * (width) + j]; } __syncthreads(); if ( i < width && j < height) { outputMatrix[i * (height) + j] = shmem[threadIdx.x][threadIdx.y]; } Транспонирование через общую память Банк-конфликт 32-го порядка
![__global__ void shmemTranspose( ElemType *inputMatrix, ElemType *outputMatrix, int width, int height) { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; __shared__ ElemType shmem[32][32]; if ( i < height &](http://images.myshared.ru/10/981152/slide_46.jpg "__global__ void shmemTranspose( ElemType *inputMatrix, ElemType *outputMatrix, int width, int height) { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; __shared__ ElemType shmem[32][32]; if ( i < height &")
47
Транспонирование через общую память __global__ void correctShmemTranspose( ElemType *inputMatrix, ElemType *outputMatrix, int width, int height) { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; __shared__ ElemType shmem[32][32 + 1]; if ( i < height && j < width) { shmem[threadIdx.y][threadIdx.x] = inputMatrix[i * (width) + j]; } __syncthreads(); if ( i < width && j < height) { outputMatrix[i * (height) + j] = shmem[threadIdx.x][threadIdx.y]; } Избавились от банк-конфилкта
 { int i = threadIdx.y + blockIdx.y * blockDim.y; int j = threadIdx.x + blockIdx.x * blockDim.x; __shared_")
48
Тесты Ядро DoubleFloat Простое ms41.040ms С общей памятью ms32.840ms С общей памятью без банк-конфликтов ms ms Kepler K20c, матрица 16384x16384 элемента

49
Выводы Общую память можно использовать как управляемый кеш для реиспользования данных Как в редукции Доступ в общую память может быть произвольным, в отличие от кеша L1 Можно применять пространственные преобразования к данным, используя общую память как буфер (транспонирование - поворот и отражение) Банк-конфликты высокого порядка могут сильно ухудшить пропускную способность общей памяти Доступный объем общей памяти ограничен Влияет на occupancy

50
The end

Еще похожие презентации в нашем архиве:









 организации памяти заключается в использовании на одном компьютере нескольких.")






![Лихогруд Николай n.lihogrud@gmail.com Задание. Свертка с квадратным ядром tmp = 0; for(ik=-r..r) for(jk=-r..r) tmp += matrix[i+ik][j+jk]*filter[ik+r][jk+r];](/thumbs/10/976459/big_thumb.jpg "Лихогруд Николай n.lihogrud@gmail.com Задание. Свертка с квадратным ядром tmp = 0; for(ik=-r..r) for(jk=-r..r) tmp += matrix[i+ik][j+jk]*filter[ik+r][jk+r];")
 имеют общее имя(имя массива) и тип (тип элементов.")




