Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Модели адаптивного прогнозирования Экспоненциальное сглаживание

2
Экспоненциальное сглаживание очень популярный метод прогнозирования очень многих временных рядов.

3
Простое экспоненциальное сглаживание Простая и прагматически ясная модель временного ряда имеет следующий вид: x t =b+ε t где b – константа, ε t – случайная ошибка.

4
Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения b состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред-предпоследним и т.д.

5
Простое экспоненциальное сглаживание именно так и устроено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не те, что попали в определенное окно.

6
Точная формула простого экспоненциального сглаживания имеет вид:

7
Когда эта формула применяется рекурсивно, то каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра α.
 вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра α.")
8
Если α = 1, то предыдущие наблюдения полностью игнорируются. Если α = 0, то игнорируются текущие наблюдения. Значения α между 0, 1 дают промежуточные результаты. Эмпирические исследования показали, что весьма часто простое экспоненциальное сглаживание дает достаточно точный прогноз.

9
Обсудим различные теоретические и эмпирические аргументы в пользу выбора определенного параметра сглаживания. Очевидно, из формулы, приведенной выше, следует, что α должно попадать в интервал между 0 (нулем) и 1.
 и 1.")
10
На практике обычно рекомендуется брать α меньше 0,3. Однако α больше 0,3 часто дает лучший прогноз. Вывод: лучше оценивать оптимально α по данным, чем просто гадать или использовать искусственные рекомендации.

11
На практике параметр сглаживания часто ищется с поиском на сетке. Возможные значения параметра разбиваются сеткой с определенным шагом. Например, рассматривается сетка значений от α = 0,1 до α = 0,9, с шагом 0,1.

12
Затем выбирается α, для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
 остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.")
13
Выявление и анализ тенденции временного ряда часто производится с помощью его выравнивания или сглаживания. Экспоненциальное сглаживание один из простейших и распространенных приемов выравнивания ряда. Экспоненциальное сглаживание можно представить как фильтр, на вход которого последовательно поступают члены исходного ряда, а на выходе формируются текущие значения экспоненциальной средней

14
Пусть X={x 1, x 2,…,x T } - временной ряд. Экспоненциальное сглаживание ряда осуществляется по рекуррентной формуле: S t =αx t +(1 – α)S t-1 Чем меньше α, тем в большей степени фильтруются, подавляются колебания исходного ряда и шума.
S t-1 Чем меньше α, тем в большей степени фильтруются, подавляются колебания исходного ряда и шума.")
15
Если последовательно использовать это рекуррентное соотношение, то экспоненциальную среднюю S t можно выразить через значения временного ряда X.

16
Если к моменту начала сглаживания существуют более ранние данные, то в качестве начального значения S 0 можно использовать арифметическую среднюю всех имеющихся данных или какой-то их части. После появления работ Р. Брауна экспоненциальное сглаживание часто используется для решения задачи краткосрочного прогнозирования временных рядов.

17
Пусть задан временной ряд: y 1, y 2,…,y t Необходимо решить задачу прогнозирования временного ряда, т.е. найти где D- горизонт прогнозирования.

18
Такую, чтобы выполнялось соотношение Для того, чтобы учитывать устаревание данных, введем невозрастающую последовательность весов w 0, w 1,…,w T, w i 0

19
Временной ряд это множество наблюдений, получаемых последовательно во времени. Если время изменяется дискретно, временной ряд называется дискретным. Мы будем рассматривать только дискретные временные ряды, в которых наблюдения делаются через фиксированный интервал времени, принимаемый за единицу счета. Переход от момента одного наблюдения к моменту следующего наблюдения будем называть шагом.

20
Обозначим член временного ряда, наблюденный в момент t, через x t.

21
Компоненты временного ряда ξ t и ε t ненаблюдаемых. Они являются теоретическими величинами. Их выделение и составляет предмет анализа временного ряда в задаче прогнозирования. Оценку будущих членов ряда обычно делают по прогнозной модели. Прогнозная модель - это модель, аппроксимирующая тренд. Прогнозы это оценки будущих уровней ряда, а последовательность прогнозов для различных периодов упреждения τ = 1, 2,.... k составляет оценку тренда.

22
При построении прогнозной модели выдвигается гипотеза о динамике величины ξ t, т.е. о характере тренда. Однако в связи с тем, что уверенность в гипотезе всегда относительна, рассматриваемые нами модели наделяются адаптивными свойствами, способностью к корректировке исходной гипотезы или даже к замене ее другой, более адекватно (с точки зрения точности прогнозов) отражающей поведение, реального ряда. Простейшая адаптивная модель основывается на вычислении так называемой экспоненциальной средней.

23
После появления работ Р. Брауна экспоненциальная средняя часто используется для краткосрочного прогнозирования. В этом случае предполагается, что ряд генерируется моделью x t = a 1,t + ε t где a 1,t варьирующий во времени средний уровень ряда; ε t случайные отклонения.

24
Прогнозная модель имеет вид где х τ (t) прогноз, сделанный в момент t на τ единиц времени (шагов) вперед; a 1,t оценка прогнозируемой величины. Средством оценки единственного параметра модели служит экспоненциальная средняя Таким образом, все свойства экспоненциальной средней распространяются на прогнозную модель.
 прогноз, сделанный в момент t на τ единиц времени (шагов) вперед; a 1,t оценка прогнозируемой величины. Средством оценки единственного параметра модели служит экспоненциальная средняя Таким образом, все свойств")
25
В частности, если S t-1 рассматривать как прогноз на 1 шаг вперед, то в выражении величина (x t S t-1 ) есть погрешность этого прогноза, а новый прогноз S t получается в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и состоит существо адаптации.
 есть погрешность этого прогноза, а новый прогноз S t получается в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и сост")
26
При краткосрочном прогнозировании желательно как можно быстрее отразить изменения a 1,t и в то же время как можно лучше очистить ряд от случайных колебаний.

27
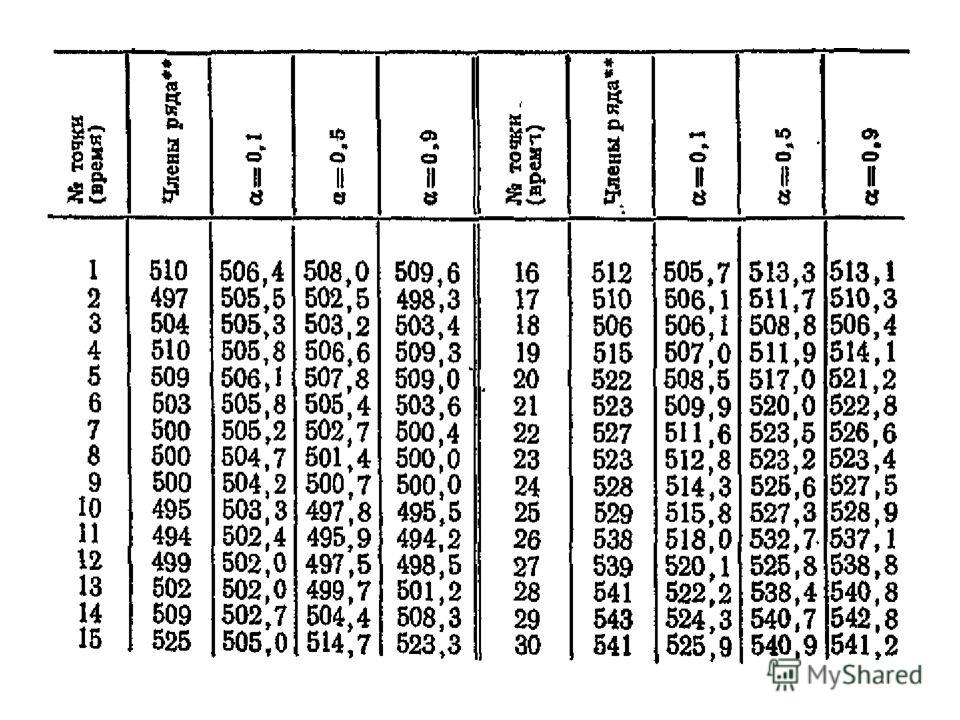
Таким образом, с одной стороны, следует увеличивать вес более свежих наблюдений, что может быть достигнуто повышением α, с другой стороны, для сглаживания случайных отклонений величину α нужно уменьшить. Как видим, эти два требования находятся в противоречии. Поиск компромиссного значения α составляет задачу оптимизации модели. Для уяснения процедуры расчета экспоненциальной средней и ее свойств рассмотрим числовой пример сглаживания ряда курса акций фирмы (см. табл. 1.1).

29
Определим S 0 как Дальнейшие вычисления при α = 0,1 выглядят следующим образом: Результаты вычислений при α=0,1, α=0,5, α=0,9 приведены в таблице.

30
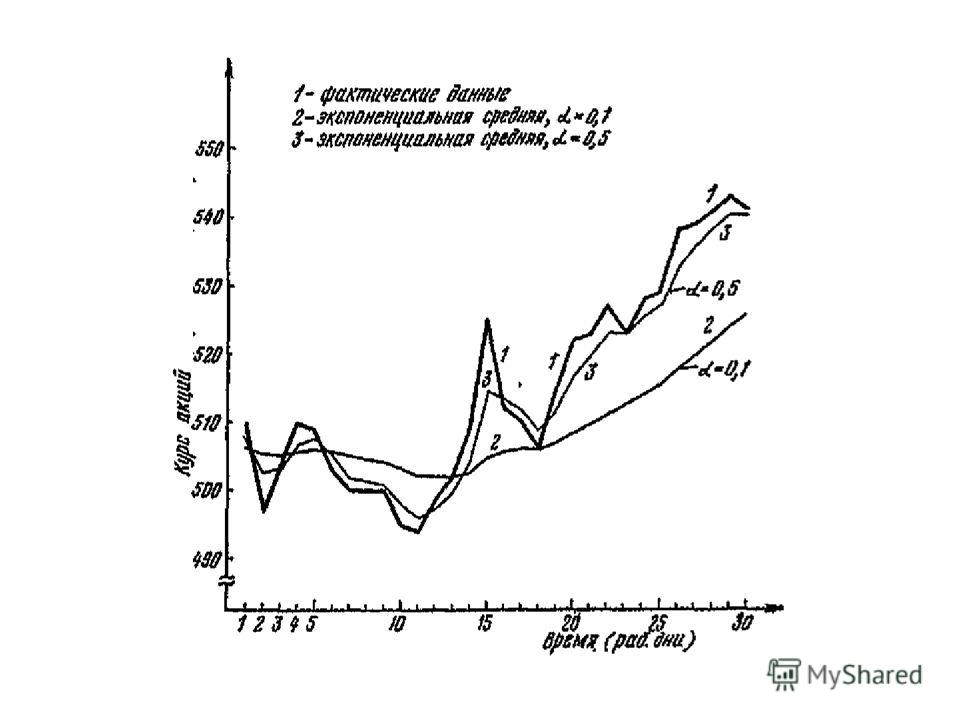
На рисунке приведен график динамики временного ряда и экспоненциальных средних при α=0,1, α=0,5. На графике наглядно показано влияние параметра α на подвижность экспоненциальной средней.

32
Экспоненциальное сглаживание является простейшим вариантом самообучающейся модели. Вычисления просты и выполняются итеративно. Они требуют даже меньше арифметических операций, чем скользящая средняя, а массив прошлой информации уменьшен до одного значения S t-1. Такую модель будем называть адаптивной экспо ненциального типа, а величину α параметром адаптации.

33
НАЧАЛЬНЫЕ УСЛОВИЯ ЭКСПОНЕНЦИАЛЬНОГО СГЛАЖИВАНИЯ Экспоненциальное выравнивание всегда требует предыдущего значения экспоненциальной средней. Когда процесс только начинается, должна быть некоторая величина S 0, которая может быть использована в качестве значения, предшествующего S 1.

34
Если есть прошлые данные к моменту начала выравнивания, то в качестве начального значения S 0 можно использовать арифметическую среднюю всех имеющихся точек или какой-то их части. Когда для такого оценивания S 0 нет данных, требуется предсказание начального уровня ряда.

35
Предсказание может быть сделано исходя из априорных знаний о процессе или на основе его аналогии с другими процессами. После k шагов вес, придаваемый начальному значению, равен (1 α) k. Если есть уверенность в справедливости начального значения S 0, то можно коэффициент α взять малым.
 k. Если есть уверенность в справедливости начального значения S")
36
Если такой уверенности нет, то параметру α следует дать большое значение, с таким расчетом, чтобы влияние начального значения быстро уменьшилось. Однако большое значение α, может явиться причиной большой дисперсии колебаний S t. Если требуется подавление этих колебаний, то после достаточного удаления от начального момента времени величину α можно убавить.

37
Рассмотрим роль параметра α в начальный период сглаживания в случае, когда нет уверенности в справедливости выбора начальной величины S 0.

38
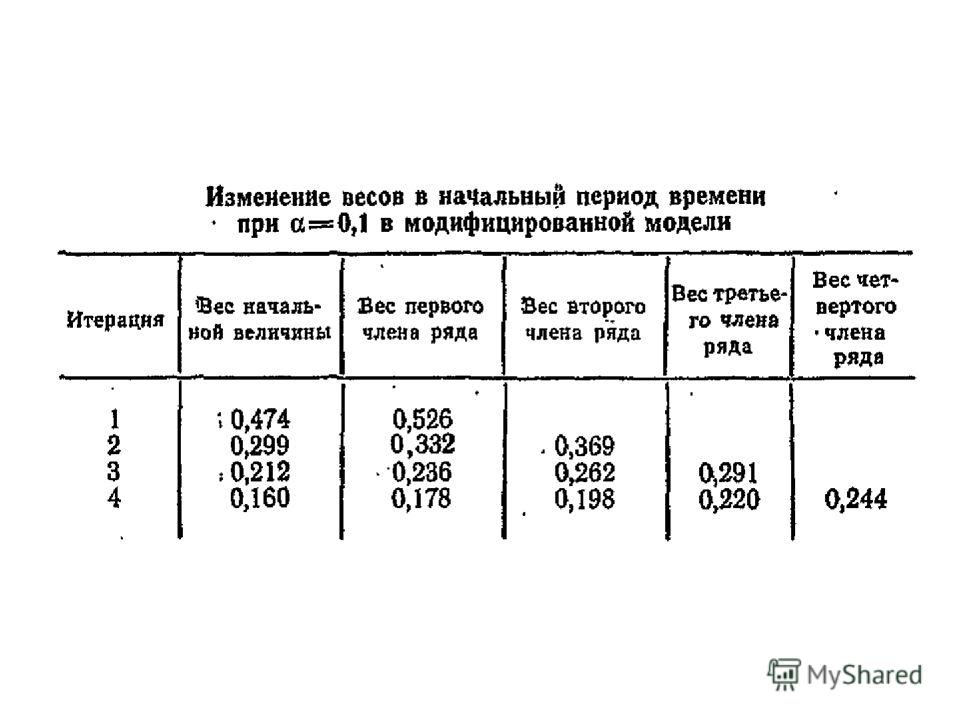
Как видно из таблицы, приведенной на следующем слайде, составленной для значения α = 0,1 начальная величина S 0 в течение длительного времени имеет чрезмерный вес, Даже после 20 итераций вес S 0 равен 0,122, что означает, что ему дается все еще больший вес, чем любому другому члену ряда. Таким образом, в этом случае получение прогнозов по экспоненциальной средней, построенной на малом отрезке ряда (выборке), чревато большими ошибками. Для того чтобы элиминировать приданный начальной величине.

40
Р. Вейд предложил следующую модификацию метода экспоненциального сглаживания Для исходного момента времени запишем: где S 0 – начальная оценка уровня ряда. Так как теперь α + α(1 – α)1, то следует использовать данное выражение в качестве множителя.
1, то следует использовать данное выражение в качестве множителя.")
41
Таким образом для момента времени t=1 получаем Или для произвольного момента времени t

42
Из анализа таблицы, приведенной на следующем слайде, можно сделать вывод о том, что сущность рассматриваемой модификации Вейда заключается в том, чтобы убрать избыточный вес начального значения S 0 и распределить его пропорционально по всем членам ряда. В этом случае получаемые прогнозы основываются в большей степени на фактических данных, а не на предварительной оценке S 0.

44
В целях сокращения трудоемкости вычислений на определенном шаге необходимо будет вернуться к обычной процедуре экспоненциального сглаживания. Это возможно в том случае, когда величина приблизится к 1. На основе эмпирического анализа Вейд рекомендовал осуществлять такой переход при сумме коэффициентов равной 0,995.

45
При заданном значении α можно заранее определить на каком шаге возможна подобная трансформация.

46
Выбор постоянной сглаживания Опыт показывает, что наибольшая точность прогнозирования может быть достигнута при любых допустимых значениях α. Однако, как правило, если в результате испытаний обнаружено, что наилучшее значение константы α близко к 1, следует проверить законность выбора модели данного типа.

47
Часто к большим значениям α приводит наличие в исследуемом ряде ярко выраженных тенденций или сезонных колебаний. В этом случае для получения эффективных прогнозов требуется другая модель.

48
Наилучшее значение α в общем случае должно зависеть от срока прогнозирования х. Для конъюнктурных прогнозов в большей мере должна учитываться свежая информация. При увеличении периода упреждения х более поздняя информация, отражающая последнюю конъюнктуру, должна, по-видимому, иметь несколько меньший вес, чем в случае малых х. Для того чтобы сгладить конъюнктурные колебания, следует в большей мере учитывать информацию за прошлые периоды времени.

49
Для проведения подобного анализа вводят понятие среднего возраста данных. Возраст текущего наблюдения равен 0, возраст предыдущего наблюдения равен 1 и т. д. Средний возраст это сумма взвешенных возрастов данных, использованных для под счета сглаженной величины. Причем возраст имеют те же веса, что и соответствующая информация.

50
При экспоненциальном выравнивании вес, даваемый точке с возрастом k равен αβ k, где β=1 α и средний возраст информации равен: Таким образом, чем меньше α, тем больше средний возраст информации. Для конъюнктурных прогнозов значение α надо брать большим, а для более долгосрочных – малым.

51
Теоретический анализ проблемы выбора постоянной сглаживания при применении простейшей модели экспоненциального сглаживания для прогнозирования стационарного процесса при прогнозировании на 1 шаг вперед, показал, что оптимальное значение параметра сглаживания в этом случае будет определяться соотношением

52
где ρ 1 – коэффициент авторкорреляции при лаге 1.

53
Модель Хольта Эмпирический анализ модели простого экспоненциального сглаживания позволяет сделать вывод о том, что с ее помощью нельзя осуществлять прогноз для данных, имеющих ярко выраженную тенденцию, то есть тренд. Модель Хольта предполагает модификацию алгоритма для случая линейного тренда.

54
В этом случае предполагается, что прогноз может быть получен в виде выражения где - текущие оценки коэффициентов адаптивных полиномов первой степени.

55
Согласно модели Хольта коэффициенты полинома первой степени определяются выражениями вида где α 1, α 2 – параметры экспоненциального сглаживания (α 1 > 0; α 2

56
Для того чтобы получить прогноз по модели Хольта, нужно провести некоторую подготовительную работу, а именно – рассчитать значения начальные значения коэффициентов адаптивных полиномов первой степени a 1,0 и a 2,0 при t=0 по имеющемуся ряду данных. После этого по какому-либо критерию подбираются постоянные сглаживания α 1, α 2 в результате чего исследователь получает линейную модель, на каждом шаге адаптирующуюся к фактическим данным.

57
Недостатком модели Хольта является невозможность учета сезонности. Модель Хольта-Уинтерса является развитием модели Хольта, в ней появляется сезонная составляющая, в результате чего получается система уравнений с тремя постоянными сглаживания

58
Модель с линейным трендом и учетом сезонности может быть записана в виде

59
где 0< α 1, α 2, α 3

Еще похожие презентации в нашем архиве:


 -симплексные(простые) -статистические.")






 Храброва М.О.")





=0 На практике это не всегда справедливо. Причины: 1. В моделях временных.")





