Скачать презентацию
1
Экономика отказоустойчивости и резервирование инфраструктуры Александр Демидов «1С-Битрикс»

2
О чем будем говорить Кому нужна отказоустойчивость Несколько кейсов с расчетами «в деньгах» Очевидные (и не очень) потери от простоев Точки отказа в инфраструктуре Защищает ли SLA провайдера Выбор инфраструтуры Решаем сами задачи резервирования
 потери от простоев Точки отказа в инфраструктуре Защищает ли SLA провайдера Выбор инфраструтуры Решаем сами задачи резервирования")
4
Два заблуждения 1. Мы «маленькие», нам думать про отказоустойчивость ни к чему, и так забот хватает. 2. Мы «большие», у нас серверов, у нас с отказоустойчивостью точно все хорошо.

6
Страшилки? О резервировании и отказоустойчивости, как правило, начинают задумываться, только столкнувшись на практике с реальными потерями и начав их считать

7
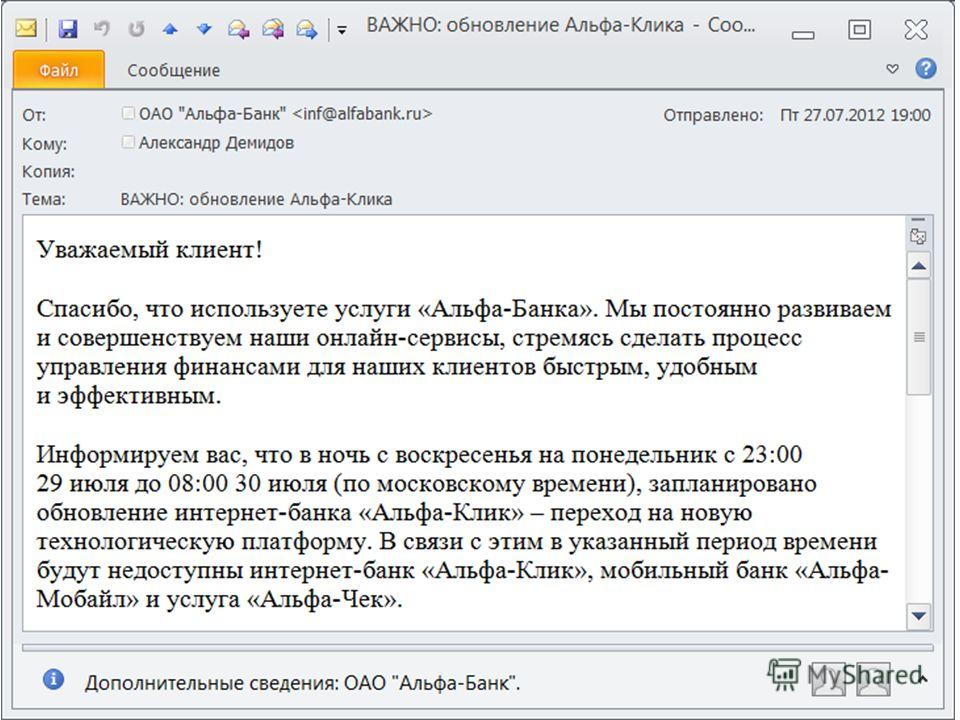
«Одноклассники» 4-6 апреля млрд. просмотров в сутки до сбоя 1.6 млрд. – в среднем в неделю сбоя 1.9 млрд. – после сбоя "Испорченный файл был выложен через централизованную систему управления серверами. В итоге это повлекло за собой необходимость перезапуска большой части наших серверов и переустановку операционной системы", заявила пресс-секретарь "Одноклассников" Мария Лапук

8
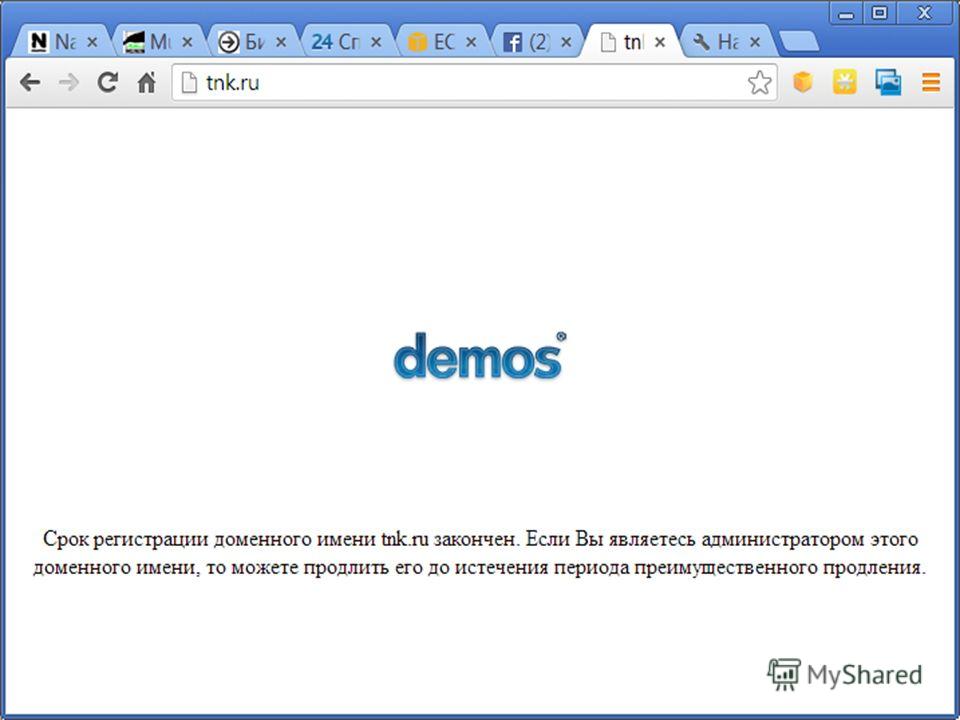
18 февраля 2013 Оборот за 2012 год - $379 млн. До суток простоя – более $1 млн.

10
Посчитаем стоимость «новой ИТ-системы» Оборот за 2012 год - $132 млн. (Digital Guru) 7 суток простоя – около $2.5 млн. А что с поиском?
 7 суток простоя – около $2.5 млн. А что с поиском?")
13
Потери и риски Прямые потери заказов «Выпадание» из поиска Финансовые потери во время рекламных компаний – вы платите за «холостые» клики Стоимость контекстной рекламы Даже если сайт доступен, но работает медленно, его позиции в результатах поиска будут ниже (учет поведенческих факторов) Репутационные риски

14
Интернет-каналы DNS Серверы Диски Датацентры Отказы инфраструктуры

15
Спасет ли SLA провайдера? Ни один SLA не покроет вашу упущенную выгоду (прибыль), только расходы на хостинг Наиболее часто встречается гарантия 99.9% доступности в SLA Это – около 9 часов простоя в год Небольшие слоты (до 5 минут) никто не считает Ребут сервера, скорее всего, не попадает под SLA. А если это база данных, она может стартовать несколько часов после аварийного завершения.
, только расходы на хостинг Наиболее часто встречается гарантия 99.9% доступности в SLA Это – около 9 часов простоя в год Небольшие слоты (до 5 минут) никто не считает Ре")
16
Web 1 Elastic Load Balancing Web N … CloudWatch + AutoScaling Web 1 Web 2 Web N … CloudWatch + AutoScaling «Хитрости» SLA S3 control cache: memcached mysqld master-master replication mysqld control cache: memcached Web 2 $25 / месяц $5000 / месяц

17
Эксплуатация: выбор инфраструктуры Риски: Взять слишком много и переплатить (не можем заранее спрогнозировать потребление ресурсов) Взять слишком мало и «просесть» по производительности Безопасность (если в штате нет толкового системного администратора) Надежность (как резервировать доступность на уровне датацентра?) Сетевая доступность
 Взять слишком мало и «просесть» по производительности Безопасность (если в штате нет толкового системного администрато")
18
Виртуальный (shared) хостинг Самый простой вариант Хороший хостинг снимает практически всю головную боль (бэкапы, резервирование и т.п.) Мало настроек Мало ресурсов Мало «путей отступления» Это – всегда «общежитие».
 хостинг Самый простой вариант Хороший хостинг снимает практически всю головную боль (бэкапы, резервирование и т.п.) Мало настроек Мало ресурсов Мало «путей отступления» Это – всегда «общежитие».")
19
Архитектура веб-кластера в одном ДЦ Apache PHP «1C-Битрикс: Управление сайтом» - кластерная редакция Балансировщик nginx (upstream module) nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер приложений 2 Сервер MySQL Master Сервер MySQL Slave MySQL (Innodb/XtraDB) DNS серверы Secondary PHP
 nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакци")
20
Резервируем сервер web-приложений Apache PHP «1C-Битрикс: Управление сайтом» - кластерная редакция Балансировщик nginx (upstream module) nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер приложений 2 Сервер MySQL Master Сервер MySQL Slave MySQL (Innodb/XtraDB) DNS серверы Secondary PHP upstream backend { server app1.example.com max_fails=3 fail_timeout=30s; server app2.example.com max_fails=3 fail_timeout=30s; } … proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
 nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция")
21
Резервируем базу данных

22
Отказал/отстал MySQL Slave Apache PHP «1C-Битрикс: Управление сайтом» - кластерная редакция Балансировщик nginx (upstream module) nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер приложений 2 Сервер MySQL Master Сервер MySQL Slave MySQL (Innodb/XtraDB) DNS серверы Secondary PHP
 nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер")
23
Резервируем кэш

24
Резервируем файлы и каналы

25
«Узкие» места

26
Балансировщик (клиентские запросы по HTTP) Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Не зарезервирована «точка входа»
 Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Не зарезервирована «точка входа»")
27
Веб-сервер База данных MySQL MASTER «1С-Битрикс: Веб-кластер» База данных MySQL SLAVE 1 База данных MySQL SLAVE N База данных MySQL SLAVE … SQL-балансировщик 1С-Битрикс Высокие требования к сети, связность серверов друг с другом

28
Балансировщик (клиентские запросы по HTTP) Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Ручные операции для восстановления masterа MySQL
 Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Ручные операции для восстановления masterа MySQL")
29
Балансировщик (клиентские запросы по HTTP) Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Аварии на уровне целого датацентра или интернет-канала
 Веб-сервер 1 memcached 1 Веб-сервер 2 memcached 1 MySQL master MySQL slave Аварии на уровне целого датацентра или интернет-канала")
30
Отказоустойчивая архитектура приложения Учимся выдерживать отказ MASTER-БД: Локальный мастер-мастер с переключением IP-адреса (скрипт или Pacemaker) Локальный мастер + DRBD c переключением Гео веб-кластер (active-passive) в другом ДЦ
 Локальный мастер + DRBD c переключением Гео веб-кластер (active-passive) в другом ДЦ")
31
Отказал MySQL Master Apache PHP «1C-Битрикс: Управление сайтом» - кластерная редакция Балансировщик nginx (upstream module) nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер приложений 2 Сервер MySQL Master Сервер MySQL Slave MySQL (Innodb/XtraDB) DNS серверы Secondary PHP
 nginx (upstream module) Сервер приложений 1 Apache Primary «1C-Битрикс: Управление сайтом» - кластерная редакция Сервер прилож")
32
Особенности настройки MySQL: auto_increment_increment auto_increment_offset Базы в разных датацентрах синхронны, при этом независимы друг от друга: потеря связности между датацентрами может составлять часы, данные синхронизируются после восстановления. Необходимо группировать пользователей для работы в одном датацентре за счет управления балансировщиком. Если сессии храним в базе, то не реплицируем их между серверами из- за большого траффика и возможных «локов»: SET sql_log_bin = 0 … или … replicate-wild-ignore-table = %.b_sec_session% Используем master-master репликацию в MySQL

33
Load Balancing Web 1 Load Balancing Web N … CloudWatch + AutoScaling Web 1 Web 2 Web N … CloudWatch + AutoScaling Резервирование на уровне ДЦ control cache: memcached mysqld master-master replication mysqld control cache: memcached Web 2 Чтобы избежать «холостой» работы половины ресурсов, каждый ДЦ обслуживает свою группу клиентов

34
Резюме Ваш сайт должен быть максимально доступен – в разумных пределах Резервируйте критичные узлы – исходя из необходимости и экономики Доступность проекта зависит не только от инфраструктуры, но и от кода, внешних сервисов и т.п. Важно не только запустить проект, но и грамотно его эксплуатировать – иметь систему мониторинга Имейте резервные копии и умейте быстро из них восстанавливаться

35
Спасибо за внимание! Вопросы? Александр Демидов













 322-95-87 info@lenvendo.ru.")











