Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Hadoop Лекция 3. Алгоритм MapReduce

2
План История создания MapReduce Основы MapReduce Примеры использования MapReduce Особенности применения MapReduce в Hadoop Недостатки MapReduce

3
История создания MapReduce – программная модель предназначенная для параллельной обработки больших объемов данных за счет разделения задачи на независимые части MapReduce придумали в Google: Jeffrey Dean, Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters Цель: упрощение индексации Web для поисковой системы

4
MapReduce в Google Основная идея – разделить код, отвечающий за разные цели: Вычисления и обработку данных Масштабирование, распараллеливание и обработку отказов Результаты: Более простой и понятный прикладной код. Для одной из фаз индексации код сократился с 3800 строк C++ до 700 Быстрое внесение изменений в систему индексации (дни или недели вместо месяцев) Простое масштабирование путем добавлением новых узлов без изменения прикладной программы

5
Реализации MapReduce Google – закрытая реализация на C++ Apache Hadoop – открытая реализация на Java Erlang NoSQL: MongoDB CouchB

6
Основы MapReduce Функциональное программирование: Обработка списков Входные данные не изменяются Описывается, ЧТО нужно сделать с данными, а не КАК это делать MapReduce автоматически обеспечивает параллельную обработку на тысячах узлов Очень сложно, если данные меняются произвольным образом

7
Функция Map Ставит в соответствии списку другой список Пример функции Map: toUpper(str) Исходный список не меняется, создается новый!
 Исходный список не меняется, создается новый!")
8
Функция Reduce Ставит в соответствие списку одно значение Пример функции Reduce: + Входной список также не меняется

9
MapReduce В MapReduce к входному списку применяются последовательно функции Map и Reduce Списки состоят из пар: ключ-значение Отличия Map и Reduce от их версий в функциональных языках: Map может генерировать для каждого элемента входного списка несколько элементов выходного Reduce может генерировать несколько итоговых значений

10
Списки ключ-значение Пример данных РТС 1 : Ключ – код компании, выпустившей акции Значение – данные о ценах акций 1

11
Ключи и Reduce Обработка элементов списка с разными ключами функциями Reduce выполняется отдельно Для каждого ключа генерируется отдельное итоговое значение

12
Пример: WordCount Подсчет количества слов во входных файлах Входные данные: file1: Hello World Bye World file2: Hello Hadoop Goodbye Hadoop Ожидаемые результаты: Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2

13
Функция Map для WordCount Алгоритм: map (filename, file-contents): for each word in file-contents: emit (word, 1) Результат: file 1: Hello 1 World 1 Bye 1 World 1 file2: Hello 1 Hadoop 1 Goodbye 1 Hadoop 1
: for each word in file-contents: emit (word, 1) Результат: file 1: Hello 1 World 1 Bye 1 World 1 file2: Hello 1 Hadoop 1 Goodbye 1 Hadoop 1")
14
Функция Reduce для WordCount Алгоритм: reduce (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) Результат: Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2
: sum = 0 for each value in values: sum = sum + value emit (word, sum) Результат: Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2")
15
Поток данных в MapReduce

16
Входные файлы загружаются в HDFS и распределяются по всем узлам На каждом узле запускаются процессы Map и обрабатывают входные файлы Любой процесс Map может обрабатывать любой файл Процессы Map генерируют промежуточные списки пар ключ-значение

17
Поток данных MapReduce Пары ключ-значение передаются по сети для обработки Reduce Все значения с одинаковым ключом передаются одному процессу Reduce Выходные данные в виде файлов записываются в HDFS

18
Поток данных в MapReduce Управление потоком данных MapReduce производится автоматически Программист не может менять поток данных Отдельные компоненты задачи не обмениваются данными между собой В противном случае невозможно автоматическое восстановление после сбоя В случае сбоя узла процессы Map и Reduce автоматически перезапускаются на другом узле

19
Эффективность MapReduce MapReduce эффективен при: Большом объеме входных данных (от десятков гигабайт и больше) Большом количестве узлов (от десятков узлов и больше) При небольших задачах слишком велики накладные расходы Hadoop не обладает оптимальной производительностью Специализированные решения работают быстрее
 Большом количестве узлов (от десятков узлов и больше) При небольших задачах слишком велики накладные расходы Hadoop не обладает оптимально")
20
Распределенный grep Задача: поиск подстроки в текстовых файлах Функция Map: читает строки файла и сравнивает с шаблоном. При совпадении генерирует пару: Ключ: имя файла Значение: проверяемая строка Функция Reduce: копирует входные данные

21
Обращения к URL Задача: посчитать количество обращений к URL Функция Map: читает журналы обращений к Web-серверу и выдает пары: Ключ: URL Значение: 1 Функция Reduce: суммирует количество одинаковых URL и выдает пары: Ключ: URL Значение: общее количество обращений

22
Инвертированный индекс Задача: составить список документов, в котором встречается заданное слово Функция Map: читает документы и для каждого слова генерирует пары: Ключ: слово Значение: идентификатор документа Функция Reduce объединяет данные для каждого слова и выдает пары: Ключ: слово Значение: список идентификаторов документов

23
Изменения цен акций Задача: найти максимальное дневное изменение цен акций за указанный период Функция Map: читает данные о стоимости акций и генерирует пары: Ключ: код эмитента Значение: изменение цены акции за день Функция Reduce: ищет максимум среди изменений за день для каждого эмитента

24
MapReduce в Hadoop Hadoop – бесплатная реализация MapReduce с открытыми исходными кодами Язык программирования – Java Есть возможность писать функции Map и Reduce на других языках с использованием Streaming Операционные система: Linux и Windows (официально), любой Unix с Java

25
Запуск задач в Hadoop

26
Job – задача MapReduce Task – часть Job, выполняющая Map или Reduce Job Tracker – сервер в кластере Hadoop, отвечающий за запуск задач распределения задачи на части Task Tracker – координаторы Task

27
Структура программы в Hadoop public class WordCount { //Класс для функции Map public static class Map extends MapReduceBase implements Mapper {… //Класс для функции Reduce public static class Reduce extends MapReduceBase implements Reducer {… //Функция main запускает задачу Hadoop public static void main(String[] args) throws Exception {… }

28
WordCount Map в Hadoop public static class Map extends MapReduceBase implements Mapper { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); }
; private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector output,")
29
WordCount Reduce в Hadoop public static class Reduce extends MapReduceBase implements Reducer { public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); }
 throws IOException { int sum = 0; while (values.hasNext()) { sum")
30
Запуск задачи в Hadoop public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); }
![Запуск задачи в Hadoop public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName(](http://images.myshared.ru/6/687301/slide_30.jpg "Запуск задачи в Hadoop public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName(")
31
Комбайнер Что означает строка: conf.setCombinerClass(Reduce.class); Комбайнер – позволяет объединять элементы с одинаковыми значениями ключа после работы Map до передачи Reduce Пример: Map: (,,, ) Combiner: (,, ) Комбайнер позволяет уменьшить объем передаваемых по сети данных Можно использовать Reducer, если функция коммуникативна и ассоциативна
; Комбайнер – позволяет объединять элементы с одинаковыми значениями ключа после работы Map до передачи Reduce Пример: Map: (,,, ) Combiner: (,, ) Комбайнер позволяет уменьшить объем п")
32
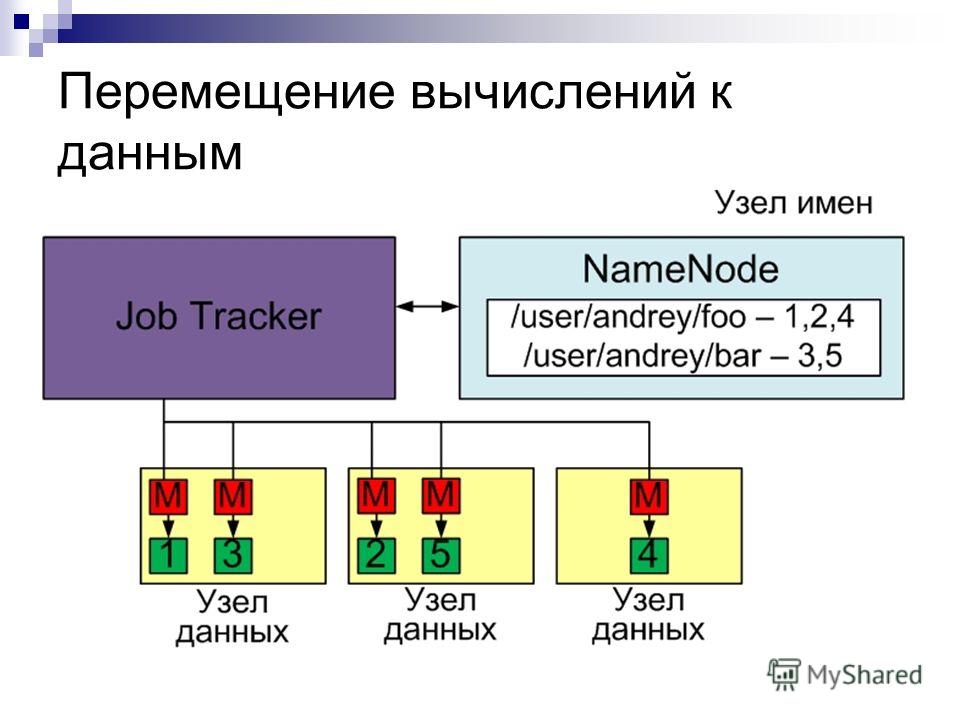
Распределение данных MapReduce автоматически распределяет входные данные между процессами Map Каждый процесс Map обрабатывает один или несколько входных файлов Если файл большой, то он делится на части и обрабатывается разными процессами Map По умолчанию размер одной порции файла 64МБ Hadoop старается запустить задачу Map на том узле, где лежат входные данные Перемещение вычислений к данным

34
Вспомним архитектуру HDFS В MapReduce входные данные не изменяются, а создаются новые В HDFS файлы записываются только один раз (WORM) В MapReduce данные по задачам Map распределяются порциями по 64МБ Размер блока HDFS 64 МБ. Данные для одной задачи считываются за одну операцию MapReduce читает большой объем входных данных последовательно, а затем последовательно записывает большой объем выходных данных HDFS оптимизирована для потоковых операций
 В MapReduce данные по задачам Map распределяются порциями по 64МБ Размер блока HDFS 64 МБ. Данные для одной задачи")
35
Недостатки MapReduce Слишком низкоуровневая технология Есть: HBase, Hive, Pig, Mahout и др. Неэффективен в маленьких кластерах с небольшим объемом данных Накладные расходы велики Задержки в одном процессе Map или Reduce ведут к задержке всей задачи

36
Задержки в MapReduce Пока не завершились все процессы Map, Reduce не может быть запущен Причины: неравномерная нагрузка

37
Задержки в MapReduce

38
Итоги MapReduce – программная модель предназначенная для параллельной обработки больших объемов данных за счет разделения задачи на независимые части Функции Map и Reduce – аналогия с функциональным программированием Технология «Перемещение вычислений к данным» Недостатки MapReduce – низкоуровневая технология, эффективность только в больших конфигурациях, задержки

39
Дополнительные материалы MapReduce: Simplified Data Processing on Large Clusters MapReduce Tutorial A Study of Skew in MapReduce Applications

40
Вопросы?

Еще похожие презентации в нашем архиве:

 для параллельной обработки больших объемов данных (терабайты)")


avs@imm.uran.ru Гольдштейн.")



,")
 Прописать CLASSPATH (путь к.")


 Курс «С#. Программирование на языке высокого уровня» Павловская Т.А.")







