Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
1 Систематика Флинна (Flynn) –Классификация по способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных: SISD (Single Instruction, Single Data) SIMD (Single Instruction, Multiple Data) MISD (Multiple Instruction, Single Data) MIMD (Multiple Instruction, Multiple Data) Классификация вычислительных систем Практически все виды параллельных систем, несмотря на их существенную разнородность, относятся к одной группе MIMD
 –Классификация по способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных: SISD (Single Instruction, Single Data) SIMD (Single Instruction, Multiple Data) MISD (Multiple Instructio")
2
Классификация Флинна 1N 1 SISD Single Instruction stream Single Data stream SIMD Single Instruction stream Multiple Data stream N MISD Multiple Instruction stream Single Data stream MIMD Multiple Instruction stream Multiple Data stream данные команды

3
Классификация Флинна SISD

4
4

5
5

6
SIMD

7
*Examples: Cray 1, NEC SX-2 Fujitsu VP, Hitachi S820

8
World's Fastest Vector Supercomputer - DigInfo видео

9
* Examples: Connection Machine CM-2 Maspar MP-1, MP-2

10
MISD

11
11

12
12

13
MIMD

15
15 Детализация систематики Флинна… –Дальнейшее разделение типов многопроцессорных систем основывается на используемых способах организации оперативной памяти, –Позволяет различать два важных типа многопроцессорных систем: multiprocessors (мультипроцессоры или системы с общей разделяемой памятью), multicomputers (мультикомпьютеры или системы с распределенной памятью). Классификация вычислительных систем

16
16 Классификация вычислительных систем

17
17 Мультипроцессоры с использованием единой общей памяти (shared memory)… –Обеспечивается однородный доступ к памяти (uniform memory access or UMA), –Являются основой для построения: векторных параллельных процессоров (parallel vector processor or PVP). Примеры: Cray T90, симметричных мультипроцессоров (symmetric multiprocessor or SMP). Примеры: IBM eServer, Sun StarFire, HP Superdome, SGI Origin. Классификация вычислительных систем
… –Обеспечивается однородный доступ к памяти (uniform memory access or UMA), –Являются основой для построения: векторных параллельных процессоров (parallel vector processor or PV")
18
Seymour Cray - Supercomputers legend видео

19
19 Мультипроцессоры с использованием единой общей памяти… Согласованность кэшей

20
20

21
Семантика памяти 21

22
Секвенциальная состоятельность 22

23
Процессорная состоятельность 23

24
Слабая состоятельность 24

25
Свободная состоятельность 25

26
26

27
Согласованность кэшей 27

28
Протокол MESI 28

29
29

30
30

31
31 Мультипроцессоры с использованием физически распределенной памяти… Классификация вычислительных систем

32
32 Мультипроцессоры с использованием физически распределенной памяти (distributed shared memory or DSM): –Неоднородный доступ к памяти (non-uniform memory access or NUMA), –Среди систем такого типа выделяют: cache-only memory architecture or COMA (системы KSR-1 и DDM), cache-coherent NUMA or CC-NUMA (системы SGI Origin 2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000), non-cache coherent NUMA or NCC-NUMA (система Cray T3E). Классификация вычислительных систем
: –Неоднородный доступ к памяти (non-uniform memory access or NUMA), –Среди систем такого типа выделяют: cache-only memory architecture or COMA (си")
33
NUMA 33

34
34

35
CC-NUMA 35

36
36

37
COMA 37

38
Массивно-параллельные компьютерыМассивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды, например, сетью - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, а если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию. Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам.T3Eсети компьютеров

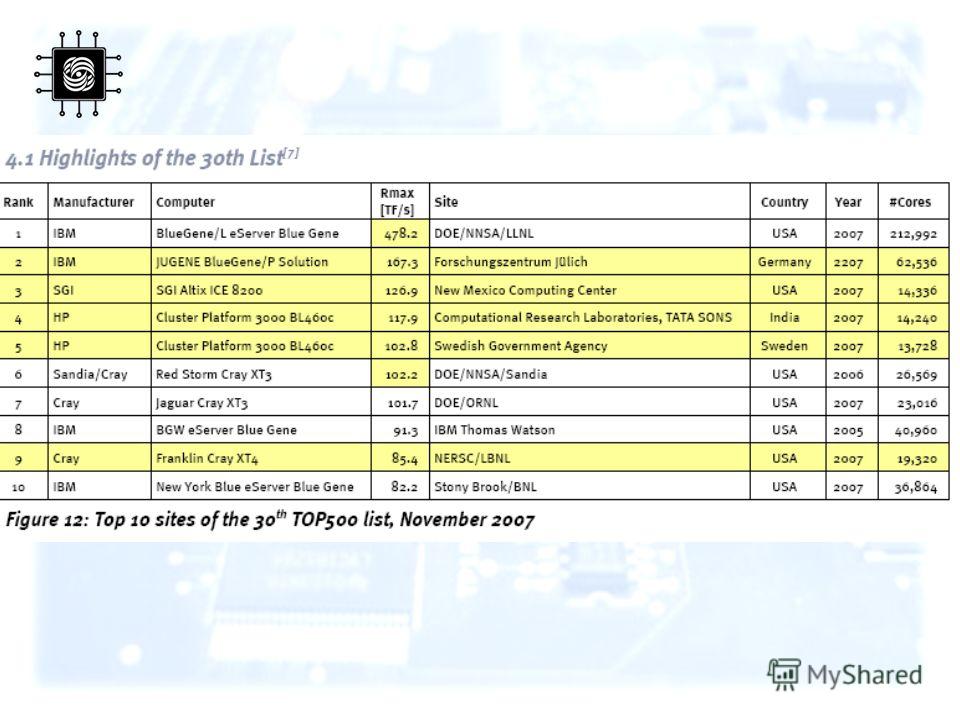
39
39 Первый вариант системы представлен в 2004 г. и сразу занял 1 позицию в списке Top500 Расширенный вариант суперкомпьютера (ноябрь 2007 г.) по прежнему на 1 месте в перечне наиболее быстродействующих вычислительных систем: двухядерных 32-битных процессоров PowerPC GHz, пиковая производительность около 600 TFlops, производительность на тесте LINPACK – 478 TFlops Суперкомпьютеры. Система BlueGene
 по прежнему на 1 месте в перечне наиболее быстродействующих вычислительных систем: 212992 двухядерных 32-битн")
40
Суперкомпьютер IBM BlueGene/L в Lawrence Livermore National Laboratory достиг на тесте Linpack производительности Tflop/s.IBM BlueGene/L Суперчемпион компьютерного мира пока что проходит окончательную отладку на заводе фирмы IBM в штате Миннесота, однако вскоре его установят в Ливерморской лаборатории. Сейчас Blue Gene/L оснащен процессорами, но со временем их число вырастет в четыре раза. Расчеты показывают, что после такой модернизации компьютер сможет достичь быстродействия 360 терафлопс. Это означает, что рубеж в 1 петафлопс может быть перейден уже в ближайшие годы.IBM Блок-схема чипа Blue Gene/L, содержащая два ядра PowerPC 440чипа

41
Каждый чип Blue Gene/P состоит из четырёх процессорных ядер PowerPC 450 с тактовой частотой 850 МГц. Чип, 2 или 4 ГБ оперативной памяти и сетевые интерфейсы образуют вычислительный узел суперкомпьютера. 32 вычислительных узла объединяются в карту (Compute Node card), к которой можно подсоединить от 0 до 2 узлов ввода-вывода. Системная стойка вмещает в себя 32 таких карты.PowerPC 450 Конфигурация Blue Gene/P с пиковой производительностью 1 петафлопс представляет собой 72 системные стойки, содержащие 294,912 процессорных ядер, объединённых в высокоскоростную оптическую сеть. Конфигурация Blue Gene/P может быть расширена до 216 стоек с общим числом процессорных ядер 884,736, чтобы достигнуть пиковую производительность в 3 петафлопса. В стандартной конфигурации системная стойка Blue Gene/P содержит 4,096 процессорных ядер. [2] [2]

42
IBM Blue Gene Видео

43
43 Мультикомпьютеры … –Не обеспечивают общий доступ ко всей имеющейся в системах памяти (no-remote memory access or NORMA), –Каждый процессор системы может использовать только свою локальную память Классификация вычислительных систем
, –Каждый процессор системы может использовать только свою локальную память Классификация вычислительных систем")
44
44

45
45 Преимущества: –Могут быть образованы на базе уже существующих у потребителей отдельных компьютеров, либо же сконструированы из типовых компьютерных элементов; –Повышение вычислительной мощности отдельных процессоров позволяет строить кластеры из сравнительно небольшого количества отдельных компьютеров (lowly parallel processing), –Для параллельного выполнения в алгоритмах достаточно выделять только крупные независимые части расчетов (coarse granularity). Кластеры

46
46 Недостатки: –Организация взаимодействия вычислительных узлов кластера при помощи передачи сообщений обычно приводит к значительным временным задержкам –Дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ (низкая интенсивность потоков передачи данных) Кластеры

47
47

48
Кластер Beowulf 48

49
Кластер Beowulf 49

50
Кластер Beowulf видео

51
Кластер Avalon 51 В 1998 году в Лос-аламосской национальной лаборатории астрофизик Michael Warren и другие ученые из группы теоретической астрофизики построили суперкомпьютер Avalon, который представляет из себя Linux- кластер на базе процессоров DEC Alpha/533MHz. Avalon первоначально состоял из 68 процессоров, затем был расширен до 140. В каждом узле установлено 256MB оперативной памяти, EIDE-жесткий диск на 3.2GB, сетевой адаптер от Kingston (общая стоимость узла - $1700). Узлы соединены с помощью 4-х 36-портовых коммутаторов Fast Ethernet и расположенного "в центре" 12-портового коммутатора Gigabit Ethernet от 3Com. Michael WarrenAvalonKingstonFast EthernetGigabit Ethernet3Com Общая стоимость Avalon - $313 тыс., а его производительность по LINPACK (47.7 GFLOPS) позволила ему занять 114 место в 12-й редакции списка Top500 (рядом с 152-процессорной системой IBM SP2). 70-процессорная конфигурация Avalon по многим тестам показала такую же производительность, как 64-процессорная система SGI Origin2000/195MHz стоимость которой превышает $1 млн. Top500Origin2000

52
Кластер Ломоносов видео

54
Top 10 Fastest Supercomputers in the World 54

55
Top 10 Fastest Supercomputers видео

56
56 Систематика Флинна (Flynn) –Классификация по способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных: SISD (Single Instruction, Single Data) SIMD (Single Instruction, Multiple Data) MISD (Multiple Instruction, Single Data) MIMD (Multiple Instruction, Multiple Data) Классификация вычислительных систем Практически все виды параллельных систем, несмотря на их существенную разнородность, относятся к одной группе MIMD
 –Классификация по способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных: SISD (Single Instruction, Single Data) SIMD (Single Instruction, Multiple Data) MISD (Multiple Instructi")
57
Дополнения Ванга и Бриггса к классификации Флинна Класс SISD разбивается на два подкласса: архитектуры с единственным функциональным устройством, например, PDP-11; архитектуры, имеющие в своем составе несколько функциональных устройств - CDC 6600, CRAY-1, FPS AP-120B, CDC Cyber 205, FACOM VP-200.

58
Дополнения Ванга и Бриггса к классификации Флинна В класс SIMD также вводится два подкласса: архитектуры с пословно-последовательной обработкой информации - ILLIAC IV, PEPE, BSP; архитектуры с разрядно-последовательной обработкой - STARAN, ICL DAP.

59
Дополнения Ванга и Бриггса к классификации Флинна В классе MIMD авторы различают вычислительные системы со слабой связью между процессорами, к которым они относят все системы с распределенной памятью, например, Cosmic Cube, и вычислительные системы с сильной связью (системы с общей памятью), куда попадают такие компьютеры, как C.mmp, BBN Butterfly, CRAY Y- MP, Denelcor HEP.

60
Классификация Хокни

61
Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса: MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя; MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.

62
Классификация Хокни Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина. Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
. В этом случае общение самих процессоров реализуется с помощью очень")
63
Классификация Хокни При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm *, CEDAR) и, наконец, сети, изменяющие свою конфигурацию. Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов - просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
, регулярные решетки разной раз")
64
Классификация Скилликорнa, 1989 DP - Data ProcessorIP - Instruction Processor DM - Data MemoryIM - Instruction Memory

65
Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент: процессор команд (IP - Instruction Processor) - функциональное устройство, работающее, как интерпретатор команд; в системе, вообще говоря, может отсутствовать; процессор данных (DP - Data Processor) - функциональное устройство, работающее как преобразователь данных, в соответствии с арифметическими операциями; иерархия памяти (IM - Instruction Memory, DM - Data Memory) - запоминающее устройство, в котором хранятся данные и команды, пересылаемые между процессорами; переключатель - абстрактное устройство, обеспечивающее связь между процессорами и памятью. Классификация Скилликорнa, 1989
 - функциональное устройство, работающее, как интерпретатор команд; в системе, вообще го")
66
Функции процессора команд во многом схожи с функциями устройств управления последовательных машин и, согласно Д.Скилликорну, сводятся к следующим: на основе своего состояния и полученной от DP информации IP определяет адрес команды, которая будет выполняться следующей; осуществляет доступ к IM для выборки команды; получает и декодирует выбранную команду; сообщает DP команду, которую надо выполнить; определяет адреса операндов и посылает их в DP; получает от DP информацию о результате выполнения команды. Классификация Скилликорнa, 1989

67
Функции процессора данных делают его во многом похожим на арифметическое устройство традиционных процессоров: DP получает от IP команду, которую надо выполнить; получает от IP адреса операндов; выбирает операнды из DM; выполняет команду; запоминает результат в DM; возвращает в IP информацию о состоянии после выполнения команды. Классификация Скилликорнa, 1989

68
В терминах таким образом определенных основных частей компьютера структуру традиционной фон- неймановской архитектуры можно представить в следующем виде:

69
Для описания параллельных вычислительных систем автор зафиксировал четыре типа переключателей, без какой-либо явной связи с типом устройств, которые они соединяют: переключатель такого типа связывает пару функциональных устройств; n-n - переключатель связывает i-е устройство из одного множества устройств с i-м устройством из другого множества, т.е. фиксирует попарную связь; 1-n - переключатель соединяет одно выделенное устройство со всеми функциональными устройствами из некоторого набора; n×n - каждое функциональное устройство одного множества может быть связано с любым устройством другого множества, и наоборот.

70
Примеров подобных переключателей можно привести очень много. Так, все матричные процессоры имеют переключатель типа 1-n для связи единственного процессора команд со всеми процессорами данных. В компьютерах семейства Connection Machine каждый процессор данных имеет свою локальную память, следовательно, связь будет описываться как n-n. В тоже время, каждый процессор команд может связаться с любым другим процессором, поэтому данная связь будет описана как n × n.

71
Классификация Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на основе восьми характеристик: 1.количество процессоров команд (IP); 2.число запоминающих устройств (модулей памяти) команд (IM); 3.тип переключателя между IP и IM; 4.количество процессоров данных (DP); 5.число запоминающих устройств (модулей памяти) данных (DM); 6.тип переключателя между DP и DM; 7.тип переключателя между IP и DP; 8.тип переключателя между DP и DP.
; 2.число запоминающих устройств (модулей памяти) команд (IM); 3.тип переключателя между IP и IM;")
72
Рассмотрим упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик его можно описать: (1, 1, 1-1, n, n, n-n, 1-n, n×n), а условное изображение архитектуры приведено на следующем рисунке: IPIM IP-IM DPDM DP-DM IP-DP DP-DP
, а условное изображение архитектуры приведено на следующем рисунке: IPIM IP-IM DPDM DP-DM IP-DP DP-DP")
73
Для сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы состоят из множества процессоров, соединенных с модулями памяти с помощью динамического переключателя. Задержка при доступе любого процессора к любому модулю памяти примерно одинакова. Связь и синхронизация между процессорами осуществляется через общие (разделяемые) переменные. Описание таких машин в рамках данной классификации выглядит так: (n, n, n-n, n, n, n×n, n-n, нет), а саму архитектуру можно изобразить так, как на следующем рисунке: IPIMDPDM IP-DP IP-IMDP-DMDP-DP
 ситуация иная. Такие системы состоят из множества процессоров, соединенных с модулями памяти с помощью динамического переключателя. Задержка при доступе любого процессора к любому модулю п")
74
Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только тремя возможными вариантами значений: 0, 1 и n (т.е. больше одного), можно получить 28 классов архитектур. В классах 1-5 находятся компьютеры типа dataflow и reduction, не имеющие процессоров команд в обычном понимании этого слова. Класс 6 это классическая фон-неймановская последовательная машина. Все разновидности матричных процессоров содержатся в классах Классы 11 и 12 отвечают компьютерам типа MISD классификации Флинна и на настоящий момент, по мнению автора, пусты. Классы с 13-го по 28-й занимают всесозможные варианты мультипроцессоров, причем в классах находятся машины с достаточно привычной архитектурой, в то время, как архитектура классов пока выглядит экзотично.
, можно получить 28 классов архитектур. В классах 1-5 находятся")
75
На втором уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом уровне, добавляя возможность конвейерной обработки в процессорах команд и данных. В конце данного описания имеет смысл привести сформули- рованные автором три цели, которым должна служить хорошо построенная классификация: облегчать понимание того, что достигнуто на сегодняшний день в области архитектур вычислительных систем, и какие архитектуры имеют лучшие перспективы в будущем; подсказывать новые пути организации архитектур - речь идет о тех классах, которые в настоящее время по разным причинам пусты; показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности.

76
Классификация Дункана Из класса параллельных машин должны быть исключены те, в которых параллелизм заложен лишь на самом низком уровне, включая: конвейеризацию на этапе подготовки и выполнения команды (instruction pipelining), т.е. частичное перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение команды и сохранение результата; наличие в архитектуре нескольких функциональных устройств, работающих независимо, в частности, возможность параллельного выполнения логических и арифметических операций; наличие отдельных процессоров ввода/вывода, работающих независимо и параллельно с основными процессорами.
, т.е. частичное перекрыт")
77
Классификация Дункана Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи потоков команд и данных. Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна, но, тем не менее, относятся к параллельным архитектурам (например, векторно-конвейерные). параллельная архитектура - это такой способ организации вычислительной системы, при котором допускается, чтобы множество процессоров (простых или сложных) могло бы работать одновременно, взаимодействуя по мере надобности друг с другом.

78
Классификация Дункана

79
Классификация Базу

80
Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры, разбивающие исполнение всех инструкций на несколько этапов, в данной классификации имеют обозначение OPP i S. Более естественное применение конвейеризации происходит в векторных машинах, в которых одна команда применяется к вектору независимых данных, и за счет непрерывного использования арифметического конвейера достигается значительное ускорение. К таким компьютерам подходит обозначение DPP i S. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPP a S. Если вычислительная система подобно CDC 6600 имеет процессор с отдельными функциональными устройствами, управляемыми централизованно, то ее описание выглядит так: OPP a S. Data- flow компьютеры, в зависимости от особенностей реализации, могут быть описаны либо как OPP i A, либо OPP a A.

81
Классификация Базу Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать в рамках предложенного формализма. Если процессоры дополнительно не используют параллелизм на уровне операций или данных, то для описания можно использовать лишь букву T. В противном случае, Базу предлагает использовать знак '*' между символами, обозначающими уровни параллелизма, одновременно присутствующие в системе. Например, комбинация T*D означает, что некоторая система может одновременно исполнять несколько задач, причем каждая из них может использовать векторные команды.

82
Классификация Базу Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак '+'. Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPP i S+DPP i S (пример - это TI ASC и CDC STAR-100). Если в системе есть возможность одновременного выполнения более одной векторной команды (как в CRAY-1) то для описания векторной части можно использовать запись O*DPP i S, а полное описание данного компьютера выглядит так: O*DPP i S+OPP i S. Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров, имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPP i S+OPP i S).

83
Классификация Хендлера Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ: уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы; уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления; уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.

84
Классификация Хендлера t(C) = (k, d, w)
 = (k, d, w)")
85
t( MINIMA ) = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON ) = (1,1024,1); t( ILLIAC IV ) = (1,64,64); t( STARAN ) = (1,8192,1) - в полной конфигурации; t( C.mmp ) = (16,1,16) - основной режим работы; t( PRIME ) = (5,1,16); t( BBN Butterfly GP1000 ) = (256,~1,~32). Классификация Хендлера
 = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON ) = (1,1024,1); t( ILLIAC IV ) = (1,64,64); t( STARAN ) = (1,8192,1) - в полной конфигурации; t( C.mmp ) = (16,1,16) - основной режим работы; t( PRIME ) = (5,1,16); t( BBN Butterfly GP1000 )")
86
t= (k×k',d×d',w×w') k - число процессоров (каждый со своим УУ), работающих параллельно k' - глубина макроконвейера из отдельных процессоров d - число АЛУ в каждом процессоре, работающих параллельно d' - число функциональных устройств АЛУ в цепочке w - число разрядов в слове, обрабатываемых в АЛУ параллельно w' - число ступеней в конвейере функциональных устройств АЛУ t( TI ASC ) = (1,4,64×8) t( PEPE ) = (1×3,288,32)
 k - число процессоров (каждый со своим УУ), работающих параллельно k' - глубина макроконвейера из отдельных процессоров d - число АЛУ в каждом процессоре, работающих параллельно d' - число функциональных устройств АЛУ в цепочке w")
87
Классификация Шора Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд и память данных с пословной выборкой. Считывание данных осуществляется выборкой всех разрядов некоторого слова для их параллельной обработки в арифметико- логическом устройстве. Состав АЛУ специально не оговаривается, что допускает наличие нескольких функциональных устройств, быть может конвейерного типа. По этим соображениям в данный класс попадают как классические последовательные машины (IBM 701, PDP-11, VAX 11/780), так и конвейерные скалярные (CDC 7600) и векторно-конвейерные (CRAY-1).

88
Классификация Шора Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда из всех слов, то получим машину II. Слова в памяти данных по прежнему располагаются горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит последовательная обработка слов при параллельной обработке разрядов, то в машине II - последовательная обработка битовых слоев при параллельной обработке множества слов. Другим примером служит матричная система ICL DAP, которая может одновременно обрабатывать по одному разряду из 4096 слов.

89
Классификация Шора Если объединить принципы построения машин I и II, то получим машину III. Эта машина имеет два арифметико-логических устройства - горизонтальное и вертикальное, и модифицированную память данных, которая обеспечивает доступ как к словам, так и к битовым слоям. Впервые идею построения таких систем в 1960 году выдвинул У.Шуман, называвший их ортогональными (если память представлять как матрицу слов, то доступ к данным осуществляется в направлении, "ортогональном" традиционному - не по словам (строкам), а по битовым слоям (столбцам)).

90
Классификация Шора Если в машине I увеличить число пар арифметико-логическое устройство память данных (иногда эту пару называют процессорным элементом) то получим машину IV. Единственное устройство управления выдает команду за командой сразу всем процессорным элементам. С одной стороны, отсутствие соединений между процессорными элементами делает дальнейшее наращивание их числа относительно простым, но с другой, сильно ограничивает применимость машин этого класса. Такую структуру имеет вычислительная система PEPE, объединяющая 288 процессорных элементов.
 то получим машину IV. Единственное устройство управления выдает команду за командой сразу всем про")
91
Классификация Шора Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде матричной конфигурации, то получим схему машины V. Любой процессорный элемент теперь может обращаться к данным как в своей памяти, так и в памяти непосредственных соседей. Подобная структура характерна, например, для классического матричного компьютера ILLIAC IV.

92
Классификация Шора Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических устройств, предполагая наличие шины данных или какого- либо коммутирующего элемента между ними. Машина VI, названная матрицей с функциональной памятью (или памятью с встроенной логикой), представляет собой другой подход, предусматривающий распределение логики процессора по всему запоминающему устройству. Примерами могут служить как простые ассоциативные запоминающие устройства, так и сложные ассоциативные процессоры.

93
Классификация Фенга 93 В 1972 году Т.Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик [8]. Первая - число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Если рассмотреть предельные верхние значения данных характеристик, то каждую вычислительную систему C можно описать парой чисел (n,m) и представить точкой на плоскости в системе координат длина слова - ширина битового слоя. Площадь прямоугольника со сторонами n и m определяет интегральную характеристику потенциала параллельности P архитектуры и носит название максимальной степени параллелизма вычислительной системы: P(C)=mn. По существу, данное значение есть ничто иное, как пиковая производительность, выраженная в других единицах.
![Классификация Фенга 93 В 1972 году Т.Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик [8]. Первая - число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во](http://images.myshared.ru/6/681637/slide_93.jpg "Классификация Фенга 93 В 1972 году Т.Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик [8]. Первая - число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во")
94
Классификация Фенга 94 На основе введенных понятий все вычислительные системы в зависимости от способа обработки информации, заложенного в их архитектуру, можно разделить на четыре класса. Разрядно-последовательные пословно-последовательные (n=m=1). В каждый момент времени такие компьютеры обрабатывают только один двоичный разряд. Разрядно-параллельные пословно-последовательные (n > 1, m = 1). Большинство классических последовательных компьютеров. Разрядно-последовательные пословно-параллельные (n = 1, m > 1). Как правило вычислительные системы данного класса состоят из большого числа одноразрядных процессорных элементов, каждый из которых может независимо от остальных обрабатывать свои данные. Разрядно-параллельные пословно-параллельные (n > 1, m > 1). Большая часть существующих параллельных вычислительных систем, обрабатывая одновременно mn двоичных разрядов, принадлежит именно к этому классу.
.")
95
Классификация Шнайдера В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных. Именно разделение потоков на адреса и их содержимое позволяет описать такие ранее "неудобные" для классификации архитектуры, как компьютеры с длинным командным словом, систолические массивы и целый ряд других. Назовем потоком ссылок ( reference stream ) S некоторой вычислительной системы конечное множество бесконечных последовательностей пар: S = { (a 1 t 1 ) (a 2 t 2 )..., (b 1 u 1 ) (b 2 u 2 )..., (c 1 v 1 )(c 2 v 2 )...}, адресзначения поток команд I (поток данных D)
![Классификация Шнайдера В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредс](http://images.myshared.ru/6/681637/slide_95.jpg "Классификация Шнайдера В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредс")
96
Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая S a, - это последовательность, чей i-й элемент - набор, сформированный из адресов i-х элементов каждой последовательности из S: S a = a 1 b 1...c 1, a 2 b 2...c 2,... потока S, обозначаемая S v, - это последовательность, чей i-й элемент - набор, образованный слиянием наборов значений i-х элементов каждой последовательности из S: S v = t 1 u 1...v 1, t 2 u 2...v 2,... Если S x - последовательность элементов, где каждый элемент - набор из n чисел, то для обозначения "ширины" последовательности будем пользоваться обозначением: w(S x ) = n. Классификация Шнайдера

97
Каждую пару (I, D) с потоком команд I и потоком данных D будем называть вычислительным шаблоном, а все компьютеры будем разбивать на классы в зависимости от того, какой шаблон они могут исполнить. В самом деле, компьютер может исполнить шаблон (I, D), если он в состоянии: выдать w(I a ) адресов команд для одновременной выборки из памяти; декодировать и проинтерпретировать одновременно w(I v ) команд; выдать одновременно w(D a ) адресов операндов и выполнить одновременно w(D v ) операций над различными данными. Если все эти условия выполнены, то компьютер может быть описан следующим образом: I w(Ia)w(Iv) D w(Da)w(Dv)
 с потоком команд I и потоком данных D будем называть вычислительным шаблоном, а все компьютеры будем разбивать на классы в зависимости от того, какой шаблон они могут исполнить. В самом деле, компьютер может исполнить шаблон (I, D)")
98
Классификация Шнайдера Рассмотрим классическую последовательную машину. Согласно классификации Флинна, она попадает в класс SISD, следовательно |I| = |D| = 1. Поэтому описание однопроцессорной машины с фон- неймановской архитектурой будет выглядеть так: I 1,1 D 1,1

99
Классификация Шнайдера Теперь возьмем две машину из класса SIMD Goodyear Aerospace MPP Единственный поток команд означает I = 1. По тем же соображениям, использованным только что для последовательной машины, для потока команд получаем равенство w(I a ) = w(I v ) = 1. Далее, вспомним, что для доступа к операндам устройство управления MPP рассылает один и тот же адрес всем процессорным элементам, поэтому в этой терминологии MPP имеет единственную последовательность в потоке данных, т.е. D = 1. Однако затем выборка данных из памяти и последующая обработка осуществляется в каждом процессорном элементе, поэтому w(D v )=16384, а вся система MPP может быть описана так: I 1,1 D 1,16384

100
Классификация Шнайдера В ILLIAC IV устройство управления, так же, как и в MPP, рассылает один и тот же адрес всем процессорным элементам, однако каждый из них может получить свой уникальный адрес, добавляя содержимое локального индексного регистра. Это означает, что D = 64 и в системе присутствуют 64 потока адресов данных, определяющих одиночные потоки операндов, т.е. w(D a ) = w(D v ) = 64. Суммируя сказанное, приходим к описанию ILLIAC IV: I 1,1 D 64,64

101
Классификация Шнайдера Для более четкой классификации Шнайдер вводит три предиката для обозначения значений, которые могут принимать величины w(I a ), w(I v ), w(D a ) и w(D v ): s - предикат "равен 1"; с - предикат "от 1 до некоторой (небольшой) константы"; m - предикат "от 1 до произвольно большого конечного числа".
, w(I v ), w(D a ) и w(D v ): s - предикат")
102
Классификация Шнайдера I ss D ss - фон-неймановские машины; I ss D sc - фон-неймановские машины, в которых заложена возможность выбирать данные, расположенные с разным смещением относительно одного и того же адреса, над которыми будет выполнена одна и та же операция. Примером могут служить компьютеры, имеющие команды, типа одновременного выполнения двух операций сложения над данными в формате полуслова, расположенными по указанному адресу. I ss D sm - SIMD компьютеры без возможности получения уникального адреса для данных в каждом процессорном элементе, включающие MPP, Connection Machine 1 так же, как и систолические массивы. I ss D cc - многомерные SIMD машины - фон-неймановские машины, способные расщеплять поток данных на независимые потоки операндов; I ss D mm - это SIMD компьютеры, имеющие возможность независимой модификации адресов операндов в каждом процессорном элементе, например, ILLIAC IV и Connection Machine 2. I sc D cc - вычислительные системы, выбирающие и исполняющие одновременно несколько команд, для доступа к которым используется один адрес. Типичным примером являются компьютеры с длинным командным словом (VLIW). I cc D cc - многомерные MIMD машины. Фон-неймановские машины, которые могут расщеплять свой цикл выборки/выполнения с целью обработки параллельно нескольких независимых команд. I mm D mm - к этому классу относятся все компьютеры типа MIMD.

Еще похожие презентации в нашем архиве:







 - это взаимосвязанная совокупность аппаратных средств вычислительной техники и программного обеспечения, предназначенная для.")
 проф. Петрова И.Ю. Курс Информатики.")
 Флинна Дораж Е.М. ИСп-32.")



, любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых.")







