Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Наполнение неструктурированного текста поясняющими ссылками на статьи Wikipedia подготовил Сергей Рябов

2
Постановка задачи Сегодня мы рассмотрим, как можно автоматически распознавать темы (topics), упомянутые в тексте, и связывать их ссылками с поясняющими статьями Википедии
, упомянутые в тексте, и связывать их ссылками с поясняющими статьями Википедии")
4
Обзор связанных работ Алгоритм устранения неоднозначности ссылок Алгоритм нахождения ключевых слов Работа метода на документах «реального мира» Применения

5
R. Mihalcea и A. Csomai - Wikify Detection – определение слов и фраз, которые станут ссылками Disambiguation – определение значения слова или фразы, то есть подходящей статьи, на которую нужно ссылаться

6
Olena Medelyan Различия с предыдущей работой в фазе устранения неоднозначности. Схожие результаты достигаются значительно проще, путем сопоставления (a) вероятности (commonness) каждого значения и (b) того, как это значение соотносится с контекстом (relatedness)
 вероятности (commonness) каждого значения и (b) того, как это значение соотносится с контекстом (")
7
Обзор связанных работ Алгоритм устранения неоднозначности ссылок Алгоритм нахождения ключевых слов Работа метода на документах «реального мира» Применения

8
Алгоритм устранения неоднозначности ссылок Всего 700 статей, 50 и более ссылок в каждой: 500 для обучения 100 для настройки 100 для окончательной оценки

9
Алгоритм устранения неоднозначности ссылок Основной подход – сопоставление commonness и relatedness значения фразы Commonness значения определяется тем, насколько часто в Википедии ссылаются именно на это значение Relatedness – взвешенное среднее семантических близостей искомого значения к каждому значению из контекста (контекстному термину, КТ)

10
Wikipedia Link-based Measure a и b – статьи, между которыми вычисляется семантическая близость, A и B – наборы всех статей, ссылающихся на a и b, соответственно, W – множество всех статей Википедии

11
Алгоритм устранения неоднозначности ссылок В качестве веса КТ берется среднее от его link probability и relatedness по отношению к документу Первое позволяет отсеять КТ, не являющиеся ссылками, и подчеркнуть те, которые встречаются практически всегда в качестве ссылок Второе помогает отсеивать КТ, слабо связанные с темой документа – Суть среднее семантических близостей данного КТ ко всем остальным КТ

12
Устранение неоднозначности термина tree, используя однозначные КТ

13
Алгоритм устранения неоднозначности ссылок Чтобы сопоставить commonness и relatedness, вводится еще одно свойство – полезность (goodness) контекста Goodness – суть сумма весов КТ Далее полученные свойства используются для обучения disambiguation classifierа, который сможет выделять подходящие смыслы На стадии конфигурации определяется минимальная допустимая вероятность смысла и классификационный алгоритм
 контекста Goodness – суть сумма весов КТ Далее полученные свойства используются для обучения disambiguation clas")
14
Алгоритм устранения неоднозначности ссылок Производительность классификаторов Производительность алгоритма устранения неопределенности

15
Обзор связанных работ Алгоритм устранения неоднозначности ссылок Алгоритм нахождения ключевых слов Работа метода на документах «реального мира» Применения

16
Алгоритм нахождения ключевых слов Классификатор тренируется и конфигурируется на все тех же 500 и 100 статьях, соответственно. Собираем все термины в документе Все термины с link probability, превышающей пороговое значение, пропускаем через disambiguation classifier Полученные данные используем для обучения wikification classifierа На стадии конфигурации определяется минимальная допустимая link probability и классификационный алгоритм

17
Алгоритм нахождения ключевых слов

18
Свойства, на основе которых работает детектирующий классификатор: Link probability Relatedness Disambiguation confidence Generality Location and spread

19
Алгоритм нахождения ключевых слов Производительность классификаторов Производительность алгоритма нахождения ключевых слов

20
Обзор связанных работ Алгоритм устранения неоднозначности ссылок Алгоритм нахождения ключевых слов Работа метода на документах «реального мира» Применения

21
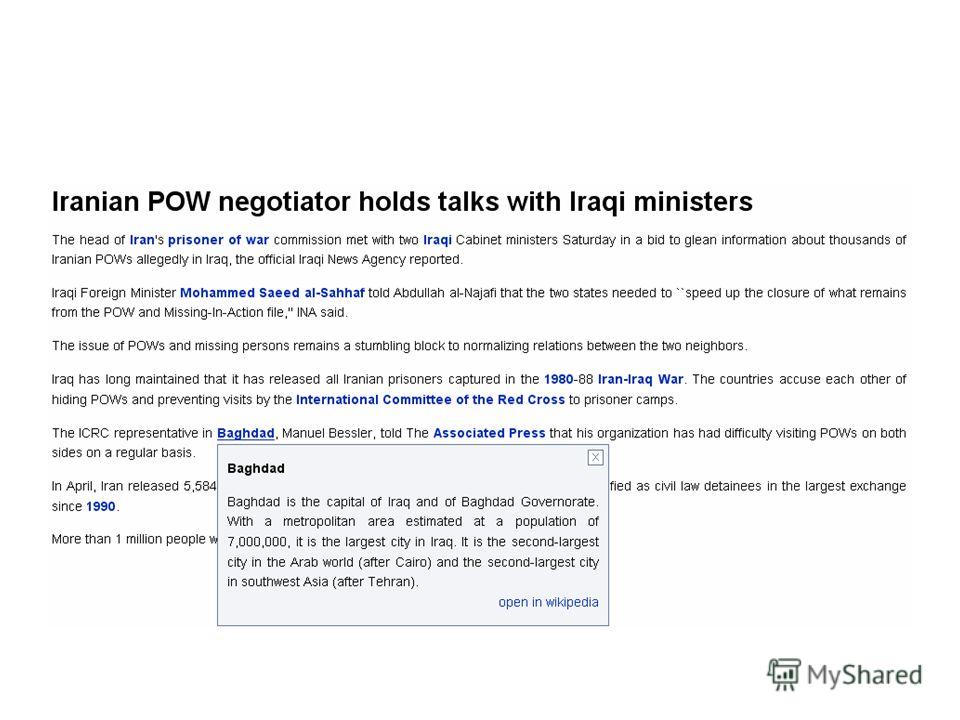
Работа метода на документах «реального мира» Для тестирования на документах «реального мира» использовались Механические Турки 50 новостных статей Система определила 449 ссылок Тест состоял из 2 частей: – Оценка найденных ссылок – Определение пропущенных ссылок Итог: (recall, precision, f-measure) = (73%, 76%, 75%)

22
Обзор связанных работ Алгоритм устранения неоднозначности ссылок Алгоритм нахождения ключевых слов Работа метода на документах «реального мира» Применения

23
Добавление поясняющих ссылок к документам – Наполнение блогов, новостных и образовательных статей ссылками – Помощь при создании новых статей Википедии Улучшение представления документов – Кластеризация документов – Topic indexing – Information retrieval

24
Применения

25
Спасибо за внимание Вопросы?

Еще похожие презентации в нашем архиве:


 на группы (кластеры) по принципу схожести.")












 моделирования данных,")


 метода при автоматизированном проектировании информационных систем.")

