Скачать презентацию
1
EPIC: Explicitly Parallel Instruction Computing (IA 64 )
")
2
Аппаратные ухищрения суперскаляров внутреннее разбиение CISC-команд на простые RISC-команды, регистровый файл, аппаратный планировщик, неупорядоченное ядро, предсказание переходов, спекулятивное исполнение, предвыборка данных и т. п.

4
Архитектура Itanium (IA64) Явный ILP (параллелизм на уровне команд) –Компилятор объединяет команды процессора в связки по три, которые могут быть выполнены параллельно. –Процессор обеспечивает большое число ресурсов для реализации ILP. Способы увеличения ILP –Явная спекуляция по данным и управлению (уменьшает задержки по памяти). –Предикатное исполнение команд (устраняет ветвления). –Аппаратная поддержка программной конвейеризации циклов. –Предсказание ветвлений. Спец. способы увеличения производительности –Специальная поддержка модульности программ (регистровый стек, вращающиеся регистры). –Высокопроизводительная вещественная арифметика. –Специальные мультимедиа инструкции. мультик
 Явный ILP (параллелизм на уровне команд) –Компилятор объединяет команды процессора в связки по три, которые могут быть выполнены параллельно. –Процессор обеспечивает большое число ресурсов для реализации ILP. Способы увелич")
7
Команды IA64 Команды IA64 объединяются в связки по три независимых инструкции: Связка содержит 3 команды и поле шаблона. Шаблон указывает типы команд в связке. Он определяет, какие исполнительные устройства будут задействованы при исполнении. Типы команд: M – memory / move I – complex integer / multimedia A – simple integer / logic / multimedia F – floating point (normal / SIMD) B – branch

8
Структура команды Команды ( 41 бит) упаковываются в связки (bundle) по 128 бит. Старшие 5 бит связки – шаблон. Шаблон указывает к каким ИУ направляется каждая из команд и границы разделения групп команд, которые не имеют зависимостей.
 упаковываются в связки (bundle) по 128 бит. Старшие 5 бит связки – шаблон. Шаблон указывает к каким ИУ направляется каждая из команд и границы разделения групп команд, которые не имеют зависимостей.")
9
Система команд Система команд IA 64 обладает основными чертами RISC-архитектуры. Регулярная длина. Команды вида (reg3 = reg1 op reg2). Операции проводятся только над регистрами, для чтения/записи из/в память существует специальная группа команд. В архитектуре IA 64 нет команд с высокой латентностью, например: трансцендентных, деления, целочисленного умножения и т.п.
. Операции проводятся только над регистрами, для чтения/записи из/в память существует специальная группа команд. В ар")
10
Особенности IA 64 архитектуры Спекуляция кода. Спекуляция данных. Предсказания. Регистровый стек. Ветвления. Вращение регистров. Архитектура вычислений с плавающей точкой.

11
Память IA-64 определяет единственное однородное, линейное адресное пространство размером 2 64 байт. – единственное означает, что код и данные находятся в одной памяти. – однородное означает, что память не разделена на участки с предопределенной функциональ- ностью. – линейное означает, что память не разделена на страницы; все 2 64 байт расположен последовательно.

12
Иерархия кэш-памяти Itanium2

13
Регистры битных регистров общего назначения GR0-GR битных вещественных регистров FR0-FR битных предикатных регистра PR0-PR битных регистров ветвлений BR0-BR7. специальные архитектурные регистры, среди которых есть регистры архитектурной поддержки циклов и вызовов функций.

14
Регистры

15
Спекулятивное исполнение по коду Команда может быть выполнена задолго до её оригинального месторасположения (используется для разрешения проблемы с задержкой памяти).
.")
16
Ветвление и предикаты Различные ветви программы могут выполняться параллельно под предикатом (это позволяет перевести зависимость по управлению в зависимость по данным ).
.")
17
Предсказание

18
Спекулятивное исполнение по данным Заключается в смене порядка обращений к памяти (используется для разрешения зависимостей по данным).
.")
19
Регистровый стек механизм, помогающий избежать ненужных сохранений регистров при вызове функций. Регистры GR32- GR128 - стековые. Они динамически переименовываются при входе в функцию и выделении регистрового фрейма стека из внутреннего регистрового файла. при переходах между подпрограммами можно избегать загрузки значений локальных переменных и параметров из памяти в регистры

20
Регистровый стек

21
Программная конвейеризация циклов Программная конвейеризация циклов обеспечивается за счет использования: – специальных инструкций ветвления -- вращения регистров – архитектурных регистров loop counter (LC) epilogue counter (EC)
 epilogue counter (EC)")
23
Программная конвейеризация Программная конвейеризация циклов – это оптимизированный способ выполнения цикла. Если итерации в цикле могут выполняться независимо, то за счет имеющихся ФУ они могут исполняться параллельно. Как только первая команда первой итерации выполнилась, начинает выполняться вторая команда первой итерации и первая команда второй итерации. Конвейер наполняется ( стадия пролога ), и затем с конвейера за один такт сходит по одной итерации цикла ( стадии ядра и эпилога ). На стадии эпилога конвейер освобождается. Предикатные регистры (начиная с p16) контроли- руют, какие из команд должны быть выполнены, а какие – нет (на стадиях пролога и эпилога). Два счетчика – LC (loop counter) и EC (epilogue counter ) определяют количество итераций и количество команд в одной итерации.

24
Вращение регистров Зависимость между итерациями устраняется за счет вращения (переименования) регистров. Верхние 75% регистров вращающиеся: При выполнении специальной команды перехода (в цикле) вращающиеся регистры сдвигаются вправо на один:
 регистров. Верхние 75% регистров вращающиеся: При выполнении специальной команды перехода (в цикле) вращающиеся регистры сдвигаются вправо на один:")
33
Пример mov pr.rot = 0 // очистка предикатных регистров вращения cmp.eq p16, p0 = r0, r0 // установить p16=1 mov ar.lc = 4 // Счетчик цикла LC=n-1 mov ar.ec = 3 // Счетчик эпилога EC=3 Loop: (p16)ld1 r32 = [r12], 1;; // #1 загрузить X (p17)add r34 = 1, r33;; // #2 Y = X+1 (p18)st1 [r13] = r35, 1;; // #3 сохранить Y br.ctop.sptk.few Loop
![Пример mov pr.rot = 0 // очистка предикатных регистров вращения cmp.eq p16, p0 = r0, r0 // установить p16=1 mov ar.lc = 4 // Счетчик цикла LC=n-1 mov ar.ec = 3 // Счетчик эпилога EC=3 Loop: (p16)ld1 r32 = [r12], 1;; // #1 загрузить X (p17)add r34 = 1](http://images.myshared.ru/6/674074/slide_33.jpg "Пример mov pr.rot = 0 // очистка предикатных регистров вращения cmp.eq p16, p0 = r0, r0 // установить p16=1 mov ar.lc = 4 // Счетчик цикла LC=n-1 mov ar.ec = 3 // Счетчик эпилога EC=3 Loop: (p16)ld1 r32 = [r12], 1;; // #1 загрузить X (p17)add r34 = 1")
34
Пример Аналогичный обычный цикл Loop: ld1 r32=[r12], 1// загрузить X add r33=1, r32// Y = X+1 st1 [r13]=r33, 1// сохранить Y br Loop
![Пример Аналогичный обычный цикл Loop: ld1 r32=[r12], 1// загрузить X add r33=1, r32// Y = X+1 st1 [r13]=r33, 1// сохранить Y br Loop](http://images.myshared.ru/6/674074/slide_34.jpg "Пример Аналогичный обычный цикл Loop: ld1 r32=[r12], 1// загрузить X add r33=1, r32// Y = X+1 st1 [r13]=r33, 1// сохранить Y br Loop")
36
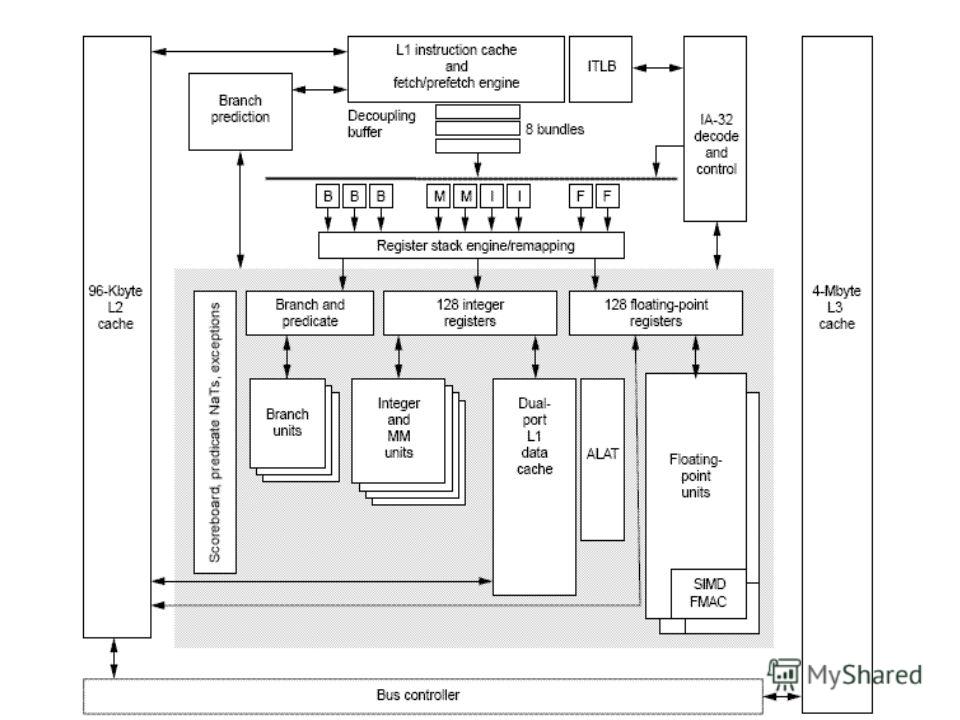
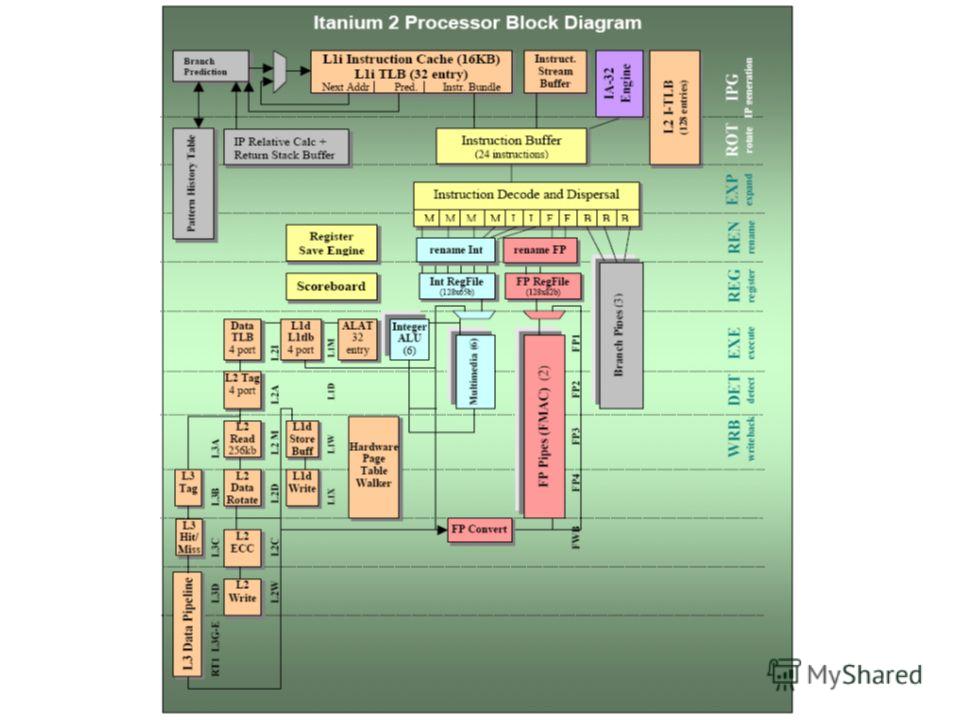
Схема Itanium® 2

38
Команды IA64 Всего возможно 24 различных шаблона: Процессор загружает по 2 связки за такт. Только некоторые сочетания шаблонов в связках могут полностью загрузить исполнительные устройства :

39
Исполнительные устройства

40
Конвейер Itanium2 IPG Вычисление IP, чтение кэша L1I (6 инст.) и TLB. EXE Выполнение (6), обращение к кэшу L1D и TLB + обращение к тэгам L2 кэша (4) ROT Расцепление и буферизация инструкций. DET Обнаружение исключений, выполнение переходов EXP Разворачивание инструкции, назначение порта WBЗавершение, запись регистрового файла REN Переименование регистров (6 инстр.) FP1-WB Конвейер FP FMAC + запись результата в регистр REGЧтение регистровых файлов (6)L2N-L2IL2 Queue Nominate / Issue (4) L2A-WL2 Access, Rotate, Correct, Write (4) Короткий 8-стадийный конвейер Полностью детерминированный путь команд Упорядоченная выборка команд, неупорядоченное завершение Требует малых задержек по памяти
 и TLB. EXE Выполнение (6), обращение к кэшу L1D и TLB + обращение к тэгам L2 кэша (4) ROT Расцепление и буферизация инструкций. DET Обнаружение исключений, выполнение переходов EXP Развор")
41
Типы команд IA64 Логические (and, …) Арифметические (add, …) Команды сравнения Команды сдвига Мультимедиа (целочисленные SIMD) Команды ветвлений (перехода) Команды ветвлений, управляющие циклом Вещественные (fma, …) SIMD вещественные (fpma, …) Команды чтения / записи данных в памяти Команды присваивания Команды управления кэшированием
 Арифметические (add, …) Команды сравнения Команды сдвига Мультимедиа (целочисленные SIMD) Команды ветвлений (перехода) Команды ветвлений, управляющие циклом Вещественные (fma, …) SIMD вещественные (fpma, …) Команд")
42
Особенности вещественной арифметики в Itanium2 Максимальная производительность –2 за такт: двойная точность –4 за такт: одинарная точность (SIMD) Основная операция –fma: f = a * b + c (4 такта) –Используется и для целочисленного умножения Быстрое преобразование значений между целыми и вещественными регистрами –FP INT (getf): 5 тактов –INT FP (setf): 6 тактов Операции деления (вещественного и целочисленного) и взятия квадратного корня реализованы программно
 Основная операция –fma: f = a * b + c (4 такта) –Используется и для целочисленного умножения Быстрое пре")
43
Register Stack Engine (RSE) автоматически сохраняет/восстанавливает регистры без вмешательства программы обеспечивает иллюзию бесконечности числа физических регистров достигается путем отображения стека физических регистров в память RSE может быть настроен на использование свободной части канала памяти для сохранения/восстановления регистров в фоновом режиме
 автоматически сохраняет/восстанавливает регистры без вмешательства программы обеспечивает иллюзию бесконечности числа физических регистров достигается путем отображения стека физических регистров в память RSE может быть на")
46
PowerPC 970FXItanium2 Частота ядра1.6 – 2.7 GHz1 – 1.66 GHz Программные регистры 32 целочисл (64 бит) 32 веществ (64 бит) 16 векторных (128-бит) 128 целочисл (64 бит) 128 веществ (82 бит) 64 предикатных (1 бит) 8 регистров ветвлений (64 бит) 128 прикладных регистра Аппаратные регистры целочисл веществ векторных соответствуют программным Кэш данных L1 32 KB 2-way строка 128 B 16 KB 4-way строка 64 B Кэш команд L1 64 KB прямого отображения строка 128 B 16 KB 4-way строка 64 B Кэш L2 512 KB 8-way строка 128B 256 KB 8-way строка 128B Кэш L3– 1.5 – 9 MB 12-way строка 128B Векторные расширенияAltiVec MMX SSE3 Длина окна215– Исполнительные устройства 12(вещ 2)11(вещ 2) Макс. число инструкций за такт 56 (2 связки) Длина конвейера целочисл 5 веществ 11 векторн Пиковая производительность 4.39 GFLOP/s (2.195 GHz) 3.20 GFLOP/s (1.600 GHz)
 32 веществ (64 бит) 16 векторных (128-бит) 128 целочисл (64 бит) 128 веществ (82 бит) 64 предикатных (1 бит) 8 регистров ветвлений (64 бит) 128 прик")















")

 Параллелизм команд (ILP – Instruction.")

 СуперскалярныеVLIW / EPIC RISCCISC Itanium2 Эльбрус.")

 организации памяти заключается в использовании на одном компьютере нескольких.")







 проф. Петрова И.Ю. Курс Информатики.")
 Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru Киреев Сергей Евгеньевич,")


 БПА команд, буфер TLB.")

