Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Соотношение программ на ЯВУ и машинном языке Это традиционный подход. После компилирования программа переводится на машинный язык, а затем интерпретируется машиной; Компиляция идет на машинный язык более высокого уровня, сокращая тем самым семантический разрыв между ЯВУ и машиной; Здесь ЯВУ можно рассматривать как язык ассемблера, т.е. имеется взаимно однозначное соответствие между типами операторов и знаков операций ЯВУ с командами машинного языка. Здесь идет ассемблирование, а не компилирование, во время которого удаляются комментарии и пробелы в исходной программе, преобразуются разделители, ключевые слова и знаки операций в машинные коды, имена – в адреса полей памяти. Таким образом, многих привычных функций компилятора здесь нет. Остальная привязка программы к ЭВМ происходит перед выполнением программы; Здесь машинный язык является ЯВУ и идет процесс интерпретации программы на компьютере

2
Основные принципы RISC-архитектуры каждая команда независимо от ее типа выполняется за один машинный цикл, длительность которого должна быть максимально короткой; все команды должны иметь одинаковую длину и использовать минимум адресных форматов, что резко упрощает логику центрального управления процессором; обращение к памяти происходит только при выполнении операций записи и чтения, вся обработка данных осуществляется исключительно в регистровой структуре процессора; система команд должна обеспечивать поддержку языка высокого уровня. (Имеется в виду подбор системы команд, наиболее эффективной для различных языков программирования.)

3
Отличительные особенности CISC- и RISC-архитектур Достоинства RISC-архитектуры: 1.Компактность процессора, как следствие отсутствие проблем с охлаждением; 2.Высокая скорость арифметических вычислений; 3.Наличие механизма динамического прогнозирования ветвлений; 4.Большое количество оперативных регистров; 5.Многоуровневая встроенная кэш-память; Недостаток – проблема в обновлении регистров процессора, что привело к появлению двух методов обновления: аппаратный и программный.

4
Задача выбора оптимального набора операций Требует из набора стандартных задач, для выполнения которых предназначен компьютер, выбрать пакет контрольных программ и построить для них профиль их выполнения, либо использовать метод статических или динамических измерений параметров самих программ. Определяется доля общего времени центрального процессора, затрачиваемого на выполнение каждого оператора Подсчет в программе количества вхождений того или иного оператора (операции) Основа для оптимизации процессорной архитектуры

5
Пример экспериментального измерения количественной оценки операций Результаты измерений в статике, проведенные для программ- компиляторов: операторы присваивания – 48 % условные операторы – 15; циклы – 16; операторы вызова-возврата – 18; прочие операторы – 3 % Измерение процедур показали использование следующих типов операндов: константы – 33 %; скаляры – 42; массивы (структуры) – 20 и прочие – 5 % Статистика среди команд управления потоком данных следующая: команды условного перехода занимают от 66 до 78 %, команды безусловного перехода – от 12 до 18 %, частота переходов на выполнение составляет от 10 до 16 %. Вывод: операторы присваивания занимают основную часть в программах- компиляторах; операнды типа константа и локальные скаляры составляют основную часть операндов в процедурах, к которым происходит обращение в процессе выполнения программы.

6
Результат анализа типов операндов Константы – не меняются во время выполнения программы и имеют, как правило, небольшие значения. Скаляры – обращение к ним происходит, как правило, явно по их имени. Их обычно немного, и они описываются в процедурах как локальные. Обращение к элементам массивов и структур происходит посредством индексов и указателей, т. е. через косвенную адресацию. Этих элементов, как правило, много. Для осуществления доступа к операнду необходимо вначале определить физический адрес ячейки, где хранится операнд, а затем осуществить доступ к операнду. Если операнд – константа, ее можно указать в команде. Доступ к ней может быть осуществлен немедленно после обращения. Регистровые блоки адресуются короткими номерами регистров, которые обычно указываются в команде, что упрощает их декодирование. Важно распределение скалярных переменных по регистрам, так как существенно влияет на скорость обработки.

7
Архитектура системы команд Аккумуляторная архитектура Регистровая архитектура Стековая архитектура ROSC (Removed Operand Set Computer) СISC (Complex Instruction Set Computer) RISC (Reduced Instruction Set Computer) VLIW (Very Long Instruction Word) Стековая организация регистровой памяти Компьютеры с регистровыми окнами
 СISC (Complex Instruction Set Computer) RISC (Reduced Instruction Set Computer) VLIW (Very Long Instruction Word) С")
8
Регистровые окна Программа Подпрограмма 1 Подпрограмма 3 Подпрограмма 4 Для уменьшения время передачи данных между процедурами-родителями и процедурами-дочерьми (в случае, когда глубина их вложенности больше единицы), можно создать блок регистров, предоставив и родителям, и дочерям доступ к некоторым из них. Накладные расходы на выполнение команд сохранения/восстановления данных при вызове и возврате из процедур на стандартных процессорах доходит до 50 % всех обращений к памяти. Перекрывающиеся блоки регистров
, можно создать блок регистров, пр")
9
VLIW-архитектура Процессор VLIW, имеющий схему, представленную выше, может выполнять в предельном случае восемь операций за один такт и работать при меньшей тактовой частоте намного более эффективнее существующих суперскалярных чипов. Добавочные функциональные блоки могут повысить производительность (за счет уменьшения конфликтов при распределении ресурсов), не слишком усложняя чип. Однако такое расширение ограничивается физическими возможностями: количеством портов чтения/записи, необходимых для обеспечения одновременного доступа функциональных блоков к файлу регистров, и взаимосвязей, число которых геометрически растет при увеличении количества функциональных блоков. К тому же компилятор должен распараллелить программу до необходимого уровня, чтобы обеспечить загрузку каждому блоку это самый главный момент, ограничивающий применимость данной архитектуры. Эта гипотетическая инструкция имеет восемь операционных полей, каждое из которых выполняет традиционную трехоперандную RISC-подобную инструкцию типа = - - (типа классической команды MOV AX BX) и может непосредственно управлять специфическим функциональным блоком при минимальном декодировании.

10
Структура команд

11
Стековая организация регистровой памяти процессора

12
Основные операция и спецкоманды Операции с регистрами: Движение вниз: (P1) P2, (P2) P3,..., а P1 заполняется данными из главной памяти Движение вверх: (Pn) Pn 1, (Pn 1) Pn 2, а Pn заполняется нулями Регистры P1 и P2 связаны с АЛУ, образуют два операнда для выполнения операции. Результат операции записывается в P1, т.е. (P1) (P2) (P1) При выполнении любой операции над двумя регистрами осуществляется продвижение операндов вверх, не затрагивая P1, т. е. (P3) P2, (P4) P3 и т. д Спецкоманды: дублирование (P1) P2, (P2) P3,... и т. д., а (P1) остается при этом неизменным; реверсирование (P1) P2, а (P2) P1, что удобно для выполнения некоторых операций.
 P2, (P2) P3,..., а P1 заполняется данными из главной памяти Движение вверх: (Pn) Pn 1, (Pn 1) Pn 2, а Pn заполняется нулями Регистры P1 и P2 связаны с АЛУ, образуют два операн")
13
Программа решения математической задачи для одноадресного компьютера

14
Программа решения математической задачи на ЭВМ со стековой организацией памяти

15
Основные типы команд

16
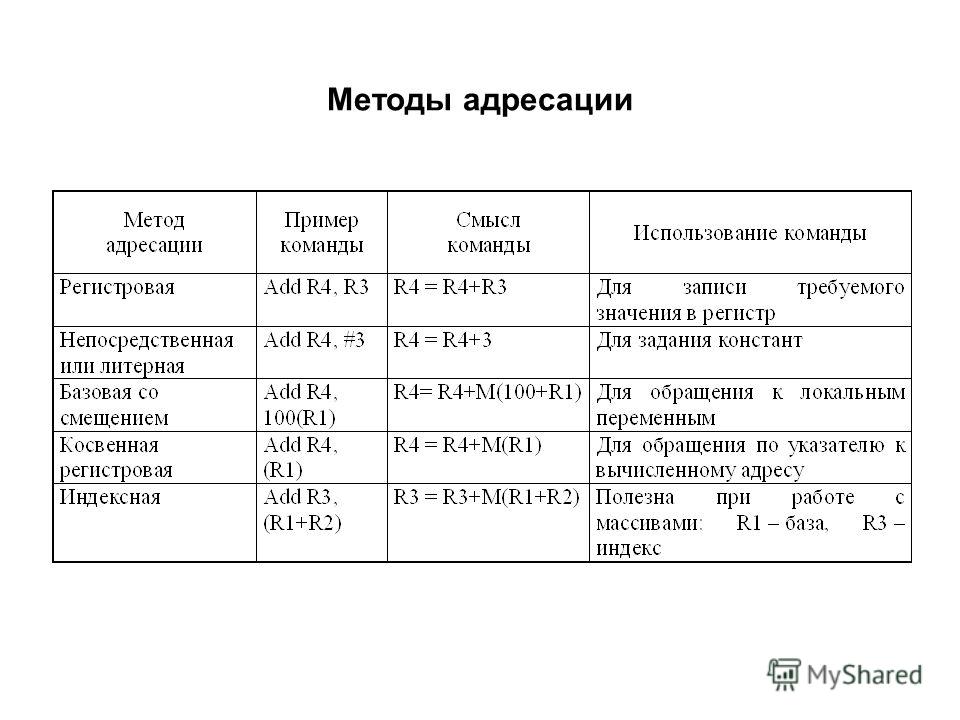
Методы адресации

18
Способы проектирования системы команд 1.Сокращение набора команд, присущих СК выбранного микропроцессора. Все частоты встреч операций для задания их в СК всякий раз можно определить из соотношений "стоимость затрат – сложность реализации – получаемый выигрыш". 2.Второй путь проектирования СК состоит в расширении имеющейся системы команд. Один из способов такого расширения – создание макрокоманд, второй – используя имеющийся синтаксис языка СК, дополнить его новыми командами с последующим переассемблированием, через расширение функций ассемблера. Оба эти способа принципиально одинаковы, но отличаются в тактике реализации аппарата расширения. Способы оптимизации системы команд 1.Выявление частоты повторений сочетаний двух или более команд, следующих друг за другом в некоторых типовых задачах для данного компьютера, с последующей заменой их одной командой, выполняющей те же функции. 2.Исследование часто генерируемых компилятором последовательностей команд с последующим редактированием и ликвидацией из них избыточных кодов. 3.Оптимизацию можно проводить и в пределах отдельной команды, исследуя ее информационную емкость. Для этого можно применить аппарат теории информации, в частности для оценки количества переданной информации – энтропию источника.

19
Развитие микропроцессорных архитектур на основе оптимизации системы команд MMX январь 1997 Pentium MMX K6 (Little Foot) AMD 6х86MX Cyrix 57 новых команд, предназначенных для обработки звуковых и видеосигналов MMX-расширение микропроцессора Pentium предназначено для поддержки приложений, ориентированных на работу с большими массивами данных целого типа, над которыми выполняются одинаковые операции. MultiMedia eXtensions Основа аппаратной компоненты – 8 MMX регистров, каждый размером в 64 бит = 8 байт. MMX работает только с целыми числами; поддерживаются данные размером в 1, 2, 4 или 8 байт.
 AMD 6х86MX Cyrix 57 новых команд, предназначенных для обработки звуковых и видеосигналов MMX-расширение микропроцессора Pentium пр")
20
SSE сентябрь 1999 Pentium III (ядро Katmai) Athlon XP (Palomino) 70 новых команд SSE оперирует с данными вещественного типа, которые используются в геометрических расчётах, то есть, приложениях трёхмерной графики, компьютерных играх, редакторах типа 3DStudioMax, и многих других.. Streaming SIMD Extensions При внедрении SSE процессор получил в дополнение к стандартным регистрам архитектуры x87 (математический сопроцессор) 8 новых больших регистров размером по 128 бит, в каждом из которых может содержаться 4 32-битных вещественных числа.
 Athlon XP (Palomino) 70 новых команд SSE оперирует с данными вещественного типа, которые используются в геометрических расчётах, то есть, приложениях трёхмерной графики, компьютерных играх, редакторах типа")
21
SSE2 сентябрь 1999 Pentium 4 (начиная с Willamette) Athlon 64 (начиная с Clawhammer) 144 команды, ориентированные на работу с потоковыми данными Команды SSE2 оперирует со 128-битными регистрами, но уже не только с четверками чисел одинарной точности, но и с любыми другими типами данных, которые умещаются в 128 бит. Streaming SIMD Extensions 2 В SSE2 регистры по сравнению с MMX удвоились, то есть, там стало помещаться не, например, 8 чисел, а 16. Поскольку скорость выполнения инструкций не изменилась, при оптимизации под SSE2 программа запросто получала двукратный прирост производительности. Продолжение MMX и SSE (симбиоз)
 Athlon 64 (начиная с Clawhammer) 144 команды, ориентированные на работу с потоковыми данными Команды SSE2 оперирует со 128-битными регистрами, но уже не только с четверками чисел одинарной точности,")
22
SSE3 февраль 2004 Pentium 4 (начиная с Prescott ) Athlon 64 (начиная с Venice) Появилась возможность горизонтального выполнения операций. Streaming SIMD Extensions 3 Prescott New Instruction Вертикальное сложение Горизонтальное сложение В SSE3 появились удобные команды горизонтального последовательного сложения и вычитания операндов, а также другие разнообразные вспомогательные команды, облегчающие работу с данными.
 Athlon 64 (начиная с Venice) Появилась возможность горизонтального выполнения операций. Streaming SIMD Extensions 3 Prescott New Instruction Вертикальное сложение Горизонтальное сложение В SSE3 появил")
23
3DNow май 1998 AMD серия К7 21 новая команда и возможность оперировать 32-битными вещественными типами в стандартных MMX-регистрах. Добавлены специальные инструкции, оптимизирующие переключение в режим MMX/3DNow!. Технология 3DNow! расширяла возможности технологии MMX, не требуя введения новых режимов работы процессора и новых регистров Важное отличие расширения 3DNow! Можно складывать между собой содержимое одного регистра, то есть, так же как и в SSE3, производить не только вертикальные операции, но и горизонтальные.

24
Enhanced 3DNow! июнь 1999 AMD K6-2 (Chomper) Набор команд расширился на 24 инструкции Отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции. 3DNow! Professional AMD (Thoroughbred) июнь 2002
 Набор команд расширился на 24 инструкции Отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции. 3DNow! Professional AMD (Tho")
25
Архитектура EM64T май 2005 Технология 64-разрядного расширения Расширение включает новые режимы работы и новые расширенные инструкции, обеспечивающие увеличение функциональных возможностей процессоров. Процессор с реализацией технологии 64-разрядного расширения полностью поддерживает все существующие особенности IA-32. В дополнение к ним вводится новый рабочий режим, получивший наименование IA-32e. Режим включает два подрежима. Первый – режим совместимости, доступный 64-разрядной операционной системе, создан для эксплуатации существующего наследия не модифицированного 32-разрядного программного обеспечения. Второй, названный 64-разрядным режимом, доступен 64-разрядной операционной системе, обеспечивающий работу приложений, написанных специально под 64-битную адресацию пространства памяти.

26
Основные усовершенствования Intel Intel Wide Dynamic Execution Intel Advanced Digital Media Boost Intel Advanced Smart Cache Intel Smart Memory Access Intel Intelligent Power Capability

27
Принцип управления операциями на основе «жесткой» логики

28
Горизонтальное микропрограммирование Вертикальное микропрограммирование

29
VLIWСпецкоманды компьютеров со стековой организацией памяти

32
Архитектура системы команд Аккумуляторная архитектура Регистровая архитектура Стековая архитектура ROSC (Removed Operand Set Computer) СISC (Complex Instruction Set Computer) RISC (Reduced Instruction Set Computer) Суперскалярные процессоры (динамическое планирование, неупорядоченная модель обработки) VLIW (Very Long Instruction Word) SMT (Simultaneous Multithreading) CMP (Chip Multiprocessor)
 СISC (Complex Instruction Set Computer) RISC (Reduced Instruction Set Computer) Суперскалярные процессоры (динамиче")
33
VLIW-архитектура Процессор VLIW, имеющий схему, представленную выше, может выполнять в предельном случае восемь операций за один такт и работать при меньшей тактовой частоте намного более эффективнее существующих суперскалярных чипов. Добавочные функциональные блоки могут повысить производительность (за счет уменьшения конфликтов при распределении ресурсов), не слишком усложняя чип. Однако такое расширение ограничивается физическими возможностями: количеством портов чтения/записи, необходимых для обеспечения одновременного доступа функциональных блоков к файлу регистров, и взаимосвязей, число которых геометрически растет при увеличении количества функциональных блоков. К тому же компилятор должен распараллелить программу до необходимого уровня, чтобы обеспечить загрузку каждому блоку это самый главный момент, ограничивающий применимость данной архитектуры. Эта гипотетическая инструкция имеет восемь операционных полей, каждое из которых выполняет традиционную трехоперандную RISC-подобную инструкцию типа = - - (типа классической команды MOV AX BX) и может непосредственно управлять специфическим функциональным блоком при минимальном декодировании.

34
Enhanced 3DNow! май 1998 AMD K6-2 (Chomper) Набор команд расширился на 24 инструкции Отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции. 3DNow! Professional AMD (Thoroughbred) июнь 2002
 Набор команд расширился на 24 инструкции Отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции. 3DNow! Professional AMD (Thor")
35
3DNow июнь 1999 AMD серия К7 21 новая команда и возможность оперировать 32-битными вещественными типами в стандартных MMX-регистрах. Добавлены специальные инструкции, оптимизирующие переключение в режим MMX/3DNow!. Технология 3DNow! расширяла возможности технологии MMX, не требуя введения новых режимов работы процессора и новых регистров Важное отличие расширения 3DNow! Можно складывать между собой содержимое одного регистра, то есть, так же как и в SSE3, производить не только вертикальные операции, но и горизонтальные.

Еще похожие презентации в нашем архиве:


")


 проф. Петрова И.Ю. Курс Информатики.")


")

,")



, является МИКРОПРОЦЕССОР или.")






 Параллелизм команд (ILP – Instruction.")
