Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Студент: Битнер Вильгельм, 518 гр. Научный руководитель: Степанов П.А.

2
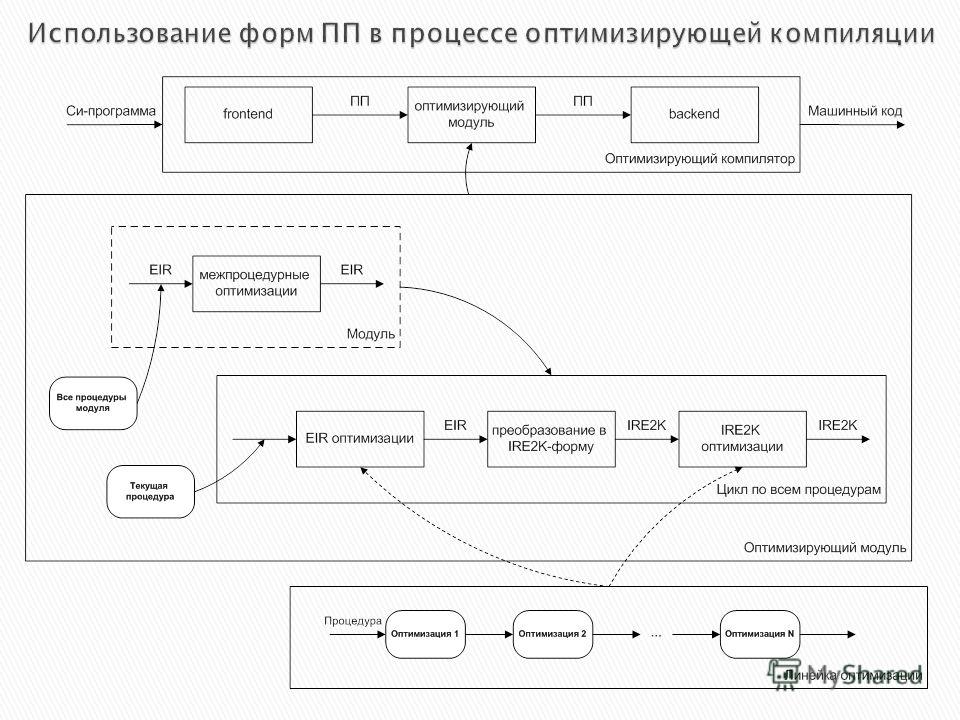
Промежуточное представление (ПП) – особая форма представления программы, предназначенного для эффективной генерации кода и проведения различных оптимизаций программы. Основные составляющие формы ПП Трехадресный код Ориентированный граф управления Типы ПП в оптимизирующем компиляторе архитектуры «Эльбрус» EIR – приближенная к языку Си форма ПП – основана на универсальных платформо-независимых средствах языка IRE2K – платформо-зависимая форма ПП – основана на машинном коде целевой архитектуры
 – особая форма представления программы, предназначенного для эффективной генерации кода и проведения различных оптимизаций программы. Основные составляющие формы ПП Трехадресный код Ориентированный граф управления Тип")
4
Виды проявления ошибок Ошибки на этапе компиляции Ошибки на этапе исполнения Возникновение исключительной ситуации Возврат неверных результатов Задача: Быстро и эффективно локализовать ошибки в оптимизациях, приводящих к неверным результатам на этапах исполнения программы Сложность диагностики ошибки: Невозможно получить исполняемый файл непосредственно после применения конкретной оптимизации (без выполнения последующих фаз) Как следствие, трудно установить какая именно оптимизация выполняет некорректное преобразование

5
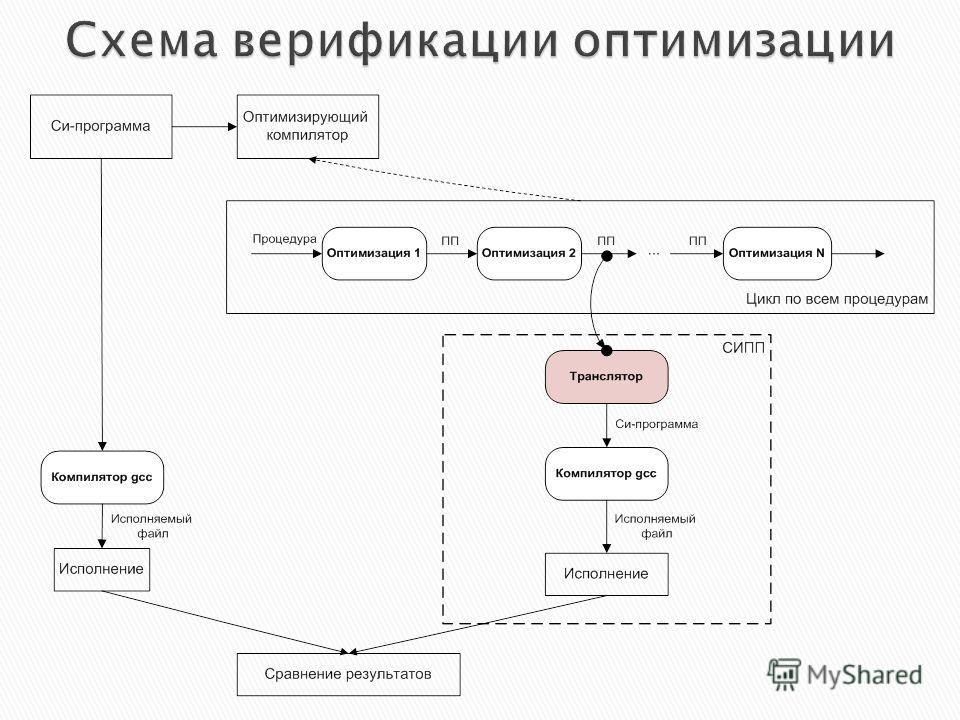
Разработать систему интерпретации промежуточного представления (СИПП) программы с целью верификации оптимизаций
 программы с целью верификации оптимизаций")
7
Моделирование ориентированного графа управления Моделирование регистров архитектуры «Эльбрус», представленных в ПП Моделирование операций ПП Моделирование предикатного режима исполнения операций Моделирование типов переменных Моделирование вызова функций Моделирование стека данных Моделирование APB

8
Средства реализации Узел метка с характерным названием Дуга оператор «goto» int main( int argc) { if ( argc > 1 ) { return 1; } else { return 0; } int main( int argc) { if ( argc > 1 ) { return 1; } else { return 0; } sint32_t main( sint32_t A1) { Rs( 0) = A1; /* CFG Start Node 0 */ nodestart0: goto nodeif8; /* CFG If Node 8 */ nodeif8: /* 25. MOVs Rs0 */ Vs(1) = Rs(0); /* 42. CMPLEs Vs1 */ Ps(0) = ( Vs(1)
 { if ( argc > 1 ) { return 1; } else { return 0; } int main( int argc) { if ( argc > 1 ) { return 1; } else { return 0; } sint32_t main( sint32_t A1) { Rs")
9
Условные переходы If-конструкции Switch-конструкции Особенность реализации switch-конструкции Использование gnu-расширение компилятора gcc void *_T_1[16]; int i_loop; for ( i_loop = 0; i_loop < 16; i_loop++) { _T_1[i_loop] = &&node96; } _T_1[13] = &&nodeif88; _T_1[11] = &&nodeif82; _T_1[4] = &&nodeif76; _T_1[2] = &&nodeif70; _T_1[9] = &&nodeif64; _T_1[12] = &&nodeif16; _T_1[15] = &&nodeif9; _T_1[0] = &&nodeif3;... /* 31. CTPG */ C0 = _T_1[0]; /* 10. BRANCH C0 */ goto *C0; void *_T_1[16]; int i_loop; for ( i_loop = 0; i_loop < 16; i_loop++) { _T_1[i_loop] = &&node96; } _T_1[13] = &&nodeif88; _T_1[11] = &&nodeif82; _T_1[4] = &&nodeif76; _T_1[2] = &&nodeif70; _T_1[9] = &&nodeif64; _T_1[12] = &&nodeif16; _T_1[15] = &&nodeif9; _T_1[0] = &&nodeif3;... /* 31. CTPG */ C0 = _T_1[0]; /* 10. BRANCH C0 */ goto *C0;...SWITCH NODE #1NODE #3NODE #4...NODE #N
![Условные переходы If-конструкции Switch-конструкции Особенность реализации switch-конструкции Использование gnu-расширение компилятора gcc void *_T_1[16]; int i_loop; for ( i_loop = 0; i_loop < 16; i_loop++) { _T_1[i_loop] = &&node96; } _T_1[13] = &&](http://images.myshared.ru/6/656892/slide_9.jpg "Условные переходы If-конструкции Switch-конструкции Особенность реализации switch-конструкции Использование gnu-расширение компилятора gcc void *_T_1[16]; int i_loop; for ( i_loop = 0; i_loop < 16; i_loop++) { _T_1[i_loop] = &&node96; } _T_1[13] = &&")
10
Регистры архитектуры «Эльбрус» моделируются с помощью локальных переменных языка Си 32-х разрядные регистры моделируются переменными типа «int», 64-х разрядные - переменными типа «long long int»

11
Элементарные операции: замена аналогичными операциями языка Си (ADD «+»; DIV «/» и т.д.) Специфические операции: моделирование функциональности операции в отдельной процедуре с последующим вызовом процедуры вместо операции getf insf Операции доступа к памяти load/store -> чтение/запись по указателю Инициализация указателя аргументами операции
 Специфические операции: моделирование функциональности операции в отдельной процедуре с последующим вызовом процедуры вместо операции getf insf Операции доступа")
12
Предикат – регистр, смоделированный аналогично регистрам архитектуры «Эльбрус» (переменная Ps) Моделируется предикатный режим исполнения операции передачи управления nodeif8: /* 23. ENTER // 3 */ /* 25. MOVs Rs0 -> Vs1 // 3 */ Vs(1) = Rs(0) /* 42. CMPLEs Vs1 0x1 -> P0 [T] // 3 */ Ps(0) = (Vs(1) C0 // 3 */ C0 = &&nodereturn2; /* 10. BRANCH C0 P0 [F] // 3 */ if ( !Ps(0) ) goto *C0; /* 11. END // 3 */ goto nodereturn3; nodeif8: /* 23. ENTER // 3 */ /* 25. MOVs Rs0 -> Vs1 // 3 */ Vs(1) = Rs(0) /* 42. CMPLEs Vs1 0x1 -> P0 [T] // 3 */ Ps(0) = (Vs(1) C0 // 3 */ C0 = &&nodereturn2; /* 10. BRANCH C0 P0 [F] // 3 */ if ( !Ps(0) ) goto *C0; /* 11. END // 3 */ goto nodereturn3;
 Моделируется предикатный режим исполнения операции передачи управления nodeif8: /* 23. ENTER // 3 */ /* 25. MOVs Rs0 -> Vs1 // 3 */ Vs(1) = Rs(0) /* 42. CM")
13
Базовые типы переменных (char, int, float и т.д.) Сложные типы переменных – все типы использованные в исходной программе в моделирующем коде восстановлены с помощью эквивалентных средств языка Си typedef struct node { char n_type; char n_flags; union { struct xsym {... } n_xsym; struct xint { long xi_int; } n_xint; struct xfloat { float xf_float; } n_xfloat; } n_info; } NODE; typedef struct node { char n_type; char n_flags; union { struct xsym {... } n_xsym; struct xint { long xi_int; } n_xint; struct xfloat { float xf_float; } n_xfloat; } n_info; } NODE; struct xsym {... }; struct xint { long xi_int; }; struct xfloat { float xf_float; }; typedef union { struct xsym n_xsym; struct xint n_xint; struct xfloat n_xfloat; }class _t; struct node { sint8_t n_type; sint8_t n_flags; class _t n_info; }; struct xsym {... }; struct xint { long xi_int; }; struct xfloat { float xf_float; }; typedef union { struct xsym n_xsym; struct xint n_xint; struct xfloat n_xfloat; }class _t; struct node { sint8_t n_type; sint8_t n_flags; class _t n_info; };
 Сложные типы переменных – все типы использованные в исходной программе в моделирующем коде восстановлены с помощью эквивалентных средств языка Си typedef struct node { char n_type; char n_flags; union")
14
Передача параметров функции при ее вызове Объявление переменных необходимого количества и нужного типа Инициализация переменных путем копирования участка памяти из регистров или стека данных Вызов функции Вызов по косвенности – вызов через указатель, инициализированный смоделированным регистром подготовки передачи управления Регистр подготовки передачи управления моделируется как переменная типа void* Получение функцией параметров Копирование параметров в регистры или в стек данных

15
Стек данных есть массив типа char Работа со стеком организована через 2 реперные точки Rs( 8) и Rs( 9), соответствующие указателям stack-pointer и frame-pointer Стек моделируется в каждой процедуре как независимая составляющая struct TEST { int a; int b; int a1; int b1; double c; }; void foo( struct TEST test, short a1, char a2, int a3, double a4, long long a5, int a6, int a7, int a8, int a9, int a10 ) {... } int main( void) { struct TEST test = {1, 2, 5, 8, 9.}; foo( test, 1, 2, 3, 4., 5, 6, 7, 8, 9, 10); return 0; } struct TEST { int a; int b; int a1; int b1; double c; }; void foo( struct TEST test, short a1, char a2, int a3, double a4, long long a5, int a6, int a7, int a8, int a9, int a10 ) {... } int main( void) { struct TEST test = {1, 2, 5, 8, 9.}; foo( test, 1, 2, 3, 4., 5, 6, 7, 8, 9, 10); return 0; } Исходная программа
 и Rs( 9), соответствующие указателям stack-pointer и frame-pointer Стек моделируется в каждой процедуре как независимая составляющая struct TEST { int a; in")
16
void foo( struct TEST A1, sint16_t A2, sint8_t A3, sint32_t A4, float64_t A5, sint64_t A6, sint32_t A7, sint32_t A8, sint32_t A9, sint32_t A10, sint32_t A11) { DefT_t( R, 1024) = {0};... sint8_t Stack[size_S] = {0}; Rs( 8) = Stack + size_S; Rs( 9) = Stack; memcpy( &Rd( 0), ( &A1) + 0), 8); memcpy( &Rd( 1), ( &A1) + 8), 8); memcpy( &Rd( 2), ( &A1) + 16), 8); Rs( 3) = A2; Rs( 4) = A3; Rs( 5) = A4; Rd( 6) = A5; Rd( 7) = A6; Rs( 8) -= 104; *(Rs( 8) + 64) = A7; memset( (Rs( 8) + 68), 0, 4); *(Rs( 8) + 72) = A8; memset( (Rs( 8) + 76), 0, 4); *(Rs( 8) + 80) = A9; memset( (Rs( 8) + 84), 0, 4); *(Rs( 8) + 88) = A10; memset( (Rs( 8) + 92), 0, 4); *(Rs( 8) + 96) = A11; memset( (Rs( 8) + 100), 0, 4);... } void foo( struct TEST A1, sint16_t A2, sint8_t A3, sint32_t A4, float64_t A5, sint64_t A6, sint32_t A7, sint32_t A8, sint32_t A9, sint32_t A10, sint32_t A11) { DefT_t( R, 1024) = {0};... sint8_t Stack[size_S] = {0}; Rs( 8) = Stack + size_S; Rs( 9) = Stack; memcpy( &Rd( 0), ( &A1) + 0), 8); memcpy( &Rd( 1), ( &A1) + 8), 8); memcpy( &Rd( 2), ( &A1) + 16), 8); Rs( 3) = A2; Rs( 4) = A3; Rs( 5) = A4; Rd( 6) = A5; Rd( 7) = A6; Rs( 8) -= 104; *(Rs( 8) + 64) = A7; memset( (Rs( 8) + 68), 0, 4); *(Rs( 8) + 72) = A8; memset( (Rs( 8) + 76), 0, 4); *(Rs( 8) + 80) = A9; memset( (Rs( 8) + 84), 0, 4); *(Rs( 8) + 88) = A10; memset( (Rs( 8) + 92), 0, 4); *(Rs( 8) + 96) = A11; memset( (Rs( 8) + 100), 0, 4);... } Обработка параметров функции Реперные точки стека Смоделированный код исходной программы
![void foo( struct TEST A1, sint16_t A2, sint8_t A3, sint32_t A4, float64_t A5, sint64_t A6, sint32_t A7, sint32_t A8, sint32_t A9, sint32_t A10, sint32_t A11) { DefT_t( R, 1024) = {0};... sint8_t Stack[size_S] = {0}; Rs( 8) = Stack + size_S; Rs( 9) =](http://images.myshared.ru/6/656892/slide_16.jpg "void foo( struct TEST A1, sint16_t A2, sint8_t A3, sint32_t A4, float64_t A5, sint64_t A6, sint32_t A7, sint32_t A8, sint32_t A9, sint32_t A10, sint32_t A11) { DefT_t( R, 1024) = {0};... sint8_t Stack[size_S] = {0}; Rs( 8) = Stack + size_S; Rs( 9) =")
17
sint32_t main( void) {... /* 30. CTPDCR [DISP 2 `foo`] -> C0 // 30 */ C0 = &foo; /* 31. CALL C0 // 30 */ { struct TEST t1_31; memcpy( (&t1_31 + 0), &Bd( 0), 8); memcpy( (&t1_31 + 8), &Bd( 1), 8); memcpy( (&t1_ ), &Bd( 2), 8); { sint16_t t2_31 = Bs(3); { sint8_t t3_31 = Bs(4); { sint32_t t4_31 = Bs(5); { float64_t t5_31 = Bd(6); { sint64_t t6_31 = Bd(7); { sint32_t t7_31 = *(Rs( 9) + 64); { sint32_t t8_31 = *(Rs( 9) + 72); { sint32_t t9_31 = *(Rs( 9) + 80); { sint32_t t10_31 = *(Rs( 9) + 88); { sint32_t t11_31 = *(Rs( 9) + 96); { typedef void proc_31( struct TEST, sint16_t, sint8_t, sint32_t, float64_t, sint64_t, sint32_t, sint32_t, sint32_t, sint32_t, sint32_t); ((proc_31 *)C0)(t1_31, t2_31, t3_31, t4_31, t5_31, t6_31, t7_31, t8_31, t9_31, t10_31, t11_31); } }}}}}}}}}}}... } sint32_t main( void) {... /* 30. CTPDCR [DISP 2 `foo`] -> C0 // 30 */ C0 = &foo; /* 31. CALL C0 // 30 */ { struct TEST t1_31; memcpy( (&t1_31 + 0), &Bd( 0), 8); memcpy( (&t1_31 + 8), &Bd( 1), 8); memcpy( (&t1_ ), &Bd( 2), 8); { sint16_t t2_31 = Bs(3); { sint8_t t3_31 = Bs(4); { sint32_t t4_31 = Bs(5); { float64_t t5_31 = Bd(6); { sint64_t t6_31 = Bd(7); { sint32_t t7_31 = *(Rs( 9) + 64); { sint32_t t8_31 = *(Rs( 9) + 72); { sint32_t t9_31 = *(Rs( 9) + 80); { sint32_t t10_31 = *(Rs( 9) + 88); { sint32_t t11_31 = *(Rs( 9) + 96); { typedef void proc_31( struct TEST, sint16_t, sint8_t, sint32_t, float64_t, sint64_t, sint32_t, sint32_t, sint32_t, sint32_t, sint32_t); ((proc_31 *)C0)(t1_31, t2_31, t3_31, t4_31, t5_31, t6_31, t7_31, t8_31, t9_31, t10_31, t11_31); } }}}}}}}}}}}... } Инициализация регистра подготовки передачи управления Подготовка переменных Вызов по косвенности
![sint32_t main( void) {... /* 30. CTPDCR [DISP 2 `foo`] -> C0 // 30 */ C0 = &foo; /* 31. CALL C0 // 30 */ { struct TEST t1_31; memcpy( (&t1_31 + 0), &Bd( 0), 8); memcpy( (&t1_31 + 8), &Bd( 1), 8); memcpy( (&t1_31 + 16), &Bd( 2), 8); { sint16_t t2_31 =](http://images.myshared.ru/6/656892/slide_17.jpg "sint32_t main( void) {... /* 30. CTPDCR [DISP 2 `foo`] -> C0 // 30 */ C0 = &foo; /* 31. CALL C0 // 30 */ { struct TEST t1_31; memcpy( (&t1_31 + 0), &Bd( 0), 8); memcpy( (&t1_31 + 8), &Bd( 1), 8); memcpy( (&t1_31 + 16), &Bd( 2), 8); { sint16_t t2_31 =")
18
Асинхронная предподкачка Подкачка необходимых элементов массива заранее перед исполнением Применение только для самых вложенных циклов APB – часть механизма предподкачки – временная память для подкаченных элементов массива циклического фрагмента программы Важность асинхронной предподкачки Ускорение процесса обращения в память во время исполнения и, как следствие, уменьшение времени исполнения программы Моделирование Определение буфера, соответствующему физической реализации APB Предварительное заполнение буфера (предподкачка) Инициализация базы массива Заполнение буфера начиная с инициализированной базы Последующее заполнение буфера по мере его освобождения, что является продолжением предварительного чтения

19
nodeif50: if( !Was_Prefetch ) { Was_Prefetch = 1; IntroduceLDOVL( &apb, 255); BAP( &apb, 0, -1); } /* 129. ENTER // 6 */ /* 130. SHLs Vs0 0x2 -> Vs4 // 8 */ Vs(4) = (Vs(0) Vs6 // 8 */ Vs(6) = mova( 0, 0, 1, 1, &apb); /* 132. ADDs Vs1 Vs6 -> Vs1 // 8 */ Vs(1) = (Vs(1) + Vs(6)); /* 133. ADDs Vs0 0x1 -> Vs0 // 6 */ Vs(0) = (Vs(0) + 1); /* 134. CMPLs Vs0 0x64 -> P1 [T] // 6 */ Ps(1) = (Vs(0) < 100); /* 135. CTPD -> C0 // 6 */ C0 = &&nodeif50; /* 136. BRANCH C0 P1 [T] // 6 */ if ( Ps(1) ) goto *C0; /* 137. END // 6 */ goto node52; nodeif50: if( !Was_Prefetch ) { Was_Prefetch = 1; IntroduceLDOVL( &apb, 255); BAP( &apb, 0, -1); } /* 129. ENTER // 6 */ /* 130. SHLs Vs0 0x2 -> Vs4 // 8 */ Vs(4) = (Vs(0) Vs6 // 8 */ Vs(6) = mova( 0, 0, 1, 1, &apb); /* 132. ADDs Vs1 Vs6 -> Vs1 // 8 */ Vs(1) = (Vs(1) + Vs(6)); /* 133. ADDs Vs0 0x1 -> Vs0 // 6 */ Vs(0) = (Vs(0) + 1); /* 134. CMPLs Vs0 0x64 -> P1 [T] // 6 */ Ps(1) = (Vs(0) < 100); /* 135. CTPD -> C0 // 6 */ C0 = &&nodeif50; /* 136. BRANCH C0 P1 [T] // 6 */ if ( Ps(1) ) goto *C0; /* 137. END // 6 */ goto node52; node51: /* 138. ENTER // 6 */ /* 145. MOVs 0x64 -> Vs10 // 6 */ Vs(10).i = 100;... /* 159. ADDs Vs14 Vs2 -> Vs3 // 6 */ Vs(3) = (Vs(14) + Vs(2)); /* 160. AAURWs Vs3 -> AAIND // 6 */ AAIND(1) = Vs(3); /* 157. CTPL -> C1 // 6 */ AAIND( 0) = 0; AAINCR( 0) = 1; CTPL_node = &&continue_157; goto node53; continue_157: /* 163. AAURWq Vq128 -> AAD // 6 */ AAD(0) = Vd(128); *(&AAD(0) + 1)= *(&Vd(128) + 1); /* 139. END // 6 */ goto nodeif50; node51: /* 138. ENTER // 6 */ /* 145. MOVs 0x64 -> Vs10 // 6 */ Vs(10).i = 100;... /* 159. ADDs Vs14 Vs2 -> Vs3 // 6 */ Vs(3) = (Vs(14) + Vs(2)); /* 160. AAURWs Vs3 -> AAIND // 6 */ AAIND(1) = Vs(3); /* 157. CTPL -> C1 // 6 */ AAIND( 0) = 0; AAINCR( 0) = 1; CTPL_node = &&continue_157; goto node53; continue_157: /* 163. AAURWq Vq128 -> AAD // 6 */ AAD(0) = Vd(128); *(&AAD(0) + 1)= *(&Vd(128) + 1); /* 139. END // 6 */ goto nodeif50; node52: /* 140. ENTER // 6 */ /* 141. END // 6 */ STOP_APB( &apb); goto nodereturn4; node52: /* 140. ENTER // 6 */ /* 141. END // 6 */ STOP_APB( &apb); goto nodereturn4; int foo ( int ar[]) { int i, sum; for ( i = 0; i < 100; i++ ) { sum += ar[i]; } return (int)(sum/100); } int main ( void) { int i, a[100]; for ( i = 0; i < 100; i++ ) { a[i] = i; } printf( "Average = %d\n", foo( a)); return 0; }` int foo ( int ar[]) { int i, sum; for ( i = 0; i < 100; i++ ) { sum += ar[i]; } return (int)(sum/100); } int main ( void) { int i, a[100]; for ( i = 0; i < 100; i++ ) { a[i] = i; } printf( "Average = %d\n", foo( a)); return 0; }` CTPL AAU BAP CTPL AAU BAP MOVA EAP node 51 node 50 node 52 Начинается загрузка программы асинхронной предподкачки в APB Инициализация регистров доступа к массиву Начало асинхронной предподкачки в буфер APB Чтение из буфера APB Остановка асинхронной предподкачки
 { Was_Prefetch = 1; IntroduceLDOVL( &apb, 255); BAP( &apb, 0, -1); } /* 129. ENTER // 6 */ /* 130. SHLs Vs0 0x2 -> Vs4 // 8 */ Vs(4) = (Vs(0) Vs6 // 8 */ Vs(6) = mova( 0, 0, 1, 1, &apb); /* 132. ADDs Vs1 Vs6 -> Vs1 // 8")
20
Разработана система интерпретации промежуточного представления программы Произведено успешное тестирование системы на 230 тестах пакета тестов SpecPerf (пакет тестов для операционного контроля производительности оптимизирующего компилятора) Реализована возможность трансляции 20 оптимизаций Дальнейшие развитие СИПП Завершение отладки на пакете тестов SpecPerf Покрытие всей линейки оптимизации
 Реализова")
Еще похожие презентации в нашем архиве:
 оператор; else оператор; Пример: if (i!=0) { if (j) j++; if(k) k++; else if(p) k--; } else i--;")




 Инструкция 1 Инструкция 2 Инструкция 3 Инструкция.")

 { … } void.")
![Лекция 9 Функции. Массивы-параметры функции Передача массива в функцию Пример: void array_enter(int a[], int size) { int i; for (i = 0; i < size; i++)](/thumbs/6/756450/big_thumb.jpg "Лекция 9 Функции. Массивы-параметры функции Передача массива в функцию Пример: void array_enter(int a[], int size) { int i; for (i = 0; i < size; i++)")


,")


![УКАЗАТЕЛИ. Переменная - это именованная область памяти с заданным типом. [=значение]; int a; //Переменная типа integer с именем a int b=2;// Переменная.](/thumbs/5/471412/big_thumb.jpg "УКАЗАТЕЛИ. Переменная - это именованная область памяти с заданным типом. [=значение]; int a; //Переменная типа integer с именем a int b=2;// Переменная.")
 Доцент Кафедры вычислительных систем,")




