Скачать презентацию
1
Введение в параллельную обработку

2
Уровни параллелизма в процессорах Параллелизм данных (DLP – Data Level Parallelism) Параллелизм команд (ILP – Instruction Level Parallelism) Параллелизм потоков (TLP – Thread Level Parallelism) Многоядерность
 Параллелизм команд (ILP – Instruction Level Parallelism) Параллелизм потоков (TLP – Thread Level Parallelism) Многоядерность")
3
Архитектуры с параллелизмом на уровне данных DLP –Data Level Parallelism

4
Параллелизм данных Векторные вычисления (SIMD) Единообразная обработка массивов данных
 Единообразная обработка массивов данных")
5
Параллелизм данных Векторно-конвейерные процессоры –Cray –Fujitsu VX/VP –NEC SX Векторные расширения –x86: MMX, 3DNow!, SSE, SSE2, … –PowerPC: AltiVec Перспективные векторные процессоры –STI Cell –Intel Larabee

6
Особенности векторно- конвейерных процессоров Большое число векторных регистров большого размера Множество различных конвейеров –Конвейер декодирования –Конвейер работы с памятью –Исполнительные конвейеры –… Конвейеры не прерываются, как при скалярном исполнении Сцепление конвейеров: Y = A * B + X C i = A i * B i Y i = C i + X i

7
Векторно-конвейерный процессор NEC SX-9 8 векторных конвейера По элементных векторных регистра Частота 3.2 GHz Производительность: более 100 GFLOPS Скалярный процессор 64-битный 4 команды/такт Частота 1.6 GHz

8
Векторные расширения скалярных архитектур Небольшая длина вектора: 64 B, 128 B Небольшое число векторных регистров: 8 – 32 Способы реализации –Векторные операции на скалярных регистрах MMX, 3DNow! Itanium –Разбиение на несколько скалярных операций (μops) SSE, SSE2 на P6, P7 –Исполнение на специальных векторных устройствах SSE, SSE2, … на Core2, Phenom

9
Перспективные векторные процессоры STI Cell 1 ядро общего назначения (PowerPC) 8 векторных ядер 128 векторных регистра Длина вектора 16 байт Intel Larabee (CPU+GPU) 8 – 48 ядер x86-подобной архитектуры Векторное расширение Длина вектора 64 байта
 8 векторных ядер 128 векторных регистра Длина вектора 16 байт Intel Larabee (CPU+GPU) 8 – 48 ядер x86-подобной архитектуры Векторное расширение Длина вектора 64 байта")
10
Архитектуры с параллелизмом на уровне команд ILP – Instruction Level Parallelism

11
Классификация архитектур Скалярные С параллелизмом на уровне команд (ILP) СуперскалярныеVLIW / EPIC RISCCISC Itanium2 Эльбрус 2000 Alpha Power, PowerPC SPARC MIPS x86 x86-64
 СуперскалярныеVLIW / EPIC RISCCISC Itanium2 Эльбрус 2000 Alpha Power, PowerPC SPARC MIPS x86 x86-64")
12
ILP-архитектуры ILP-процессоры Имеют несколько исполнительных устройств Исполняют несколько команд одновременно Классификация ILP-архитектур Суперскалярные –Процессор ищет независимые команды и планирует поток вычислений VLIW / EPIC (Very Long Instruction Word / Explicitly Parallel Instruction Computing) –Компилятор ищет независимые команды и планирует поток вычислений

13
ILP-архитектуры СуперскалярнаяVLIW / EPIC

14
Способы повышения производительности Повышение темпа исполнения команд требует повышения темпа их доставки. Средства: –Спекулятивное исполнение команд SS: автоматический выбор способа предсказания перехода EPIC: способ предсказания перехода задает компилятор –Спекулятивная загрузка данных SS: проверка корректности автоматическая EPIC: проверка корректности по спец. команде –Разрешение ложных зависимостей по данным SS: переименование регистров EPIC: компилятор не допускает ненужных зависимостей –Оптимизация вызовов подпрограмм SS: регистровый стек управляется процессоров автоматически EPIC: регистровый стек управляется компилятором

15
Сравнение ILP-архитектур Суперскалярные Сложный конвейер Простой компилятор Меньше ресурсов процессора –Регистры –Исп. устройства –Кэш Меньше команд за такт: 3, 4, 5 (50%)
")
16
Архитектура суперскалярных процессоров

17
Суперскалярные процессоры реализуют динамическое исполнение команд –это средства, которые процессор использует динамически (в ходе исполнения) для увеличении темпа обработки команд: Предсказание переходов Переименование регистров Параллельное исполнение команд Исполнение команд вне порядка
 для увеличении темпа обработки команд: Предсказание переходов Переименование регистров Параллельное исполне")
18
Конвейер процессора Front-end Блок предварительной обработки Back-end Блок завершения Execution core Исполнительное ядро

19
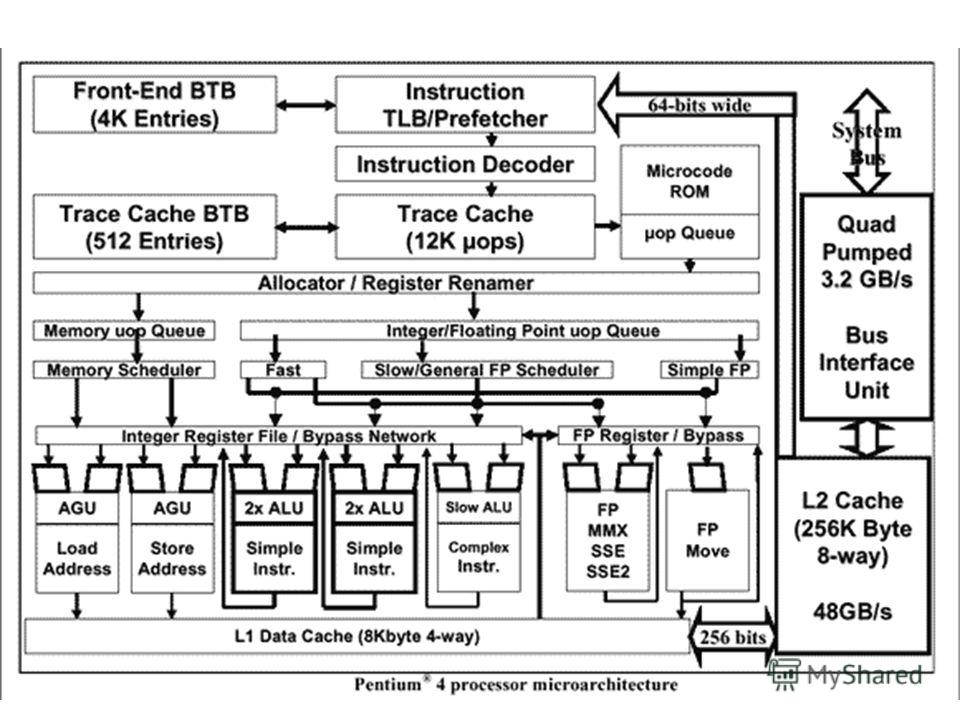
Схема суперскалярного процессора

20
Процессор PowerPC 970FX

21
Конвейер процессора с внеочередным исполнением команд In-Order Front-end Блок упорядоченной предварительной обработки In-Order Back-end Блок порядоченного завершения Out-of-Order Execution core Исполнение вне порядка

22
Схема суперскалярного процессора с переупорядочением команд

23
Буфер переупорядочения команд Каждая микрооперация проходит через следующие стадии : 1.Находится в очереди планировщика, но ещё не готова к исполнению 2.Готова к исполнению (все аргументы операции вычислены) 3.Запущена на исполнение (диспетчеризована) 4.Исполнена и ждёт отставки либо отмены спекулятивной ветви 5.Находится в процессе отставки
 3.Запущена на исполнение (диспетчеризована")
27
Оценки производительности для различных архитектур









")
 СуперскалярныеVLIW / EPIC RISCCISC Itanium2 Эльбрус.")
 – компьютер со сложным (полным) набором команд. Reduced Instruction Set Computer (RISC) – компьютер.")

")



 задач одновременно, а.")






 Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru Киреев Сергей Евгеньевич,")
