Скачать презентацию

1
Основы нейронных сетей Рязанов М.А.

2
Построение обученной нейросети

3
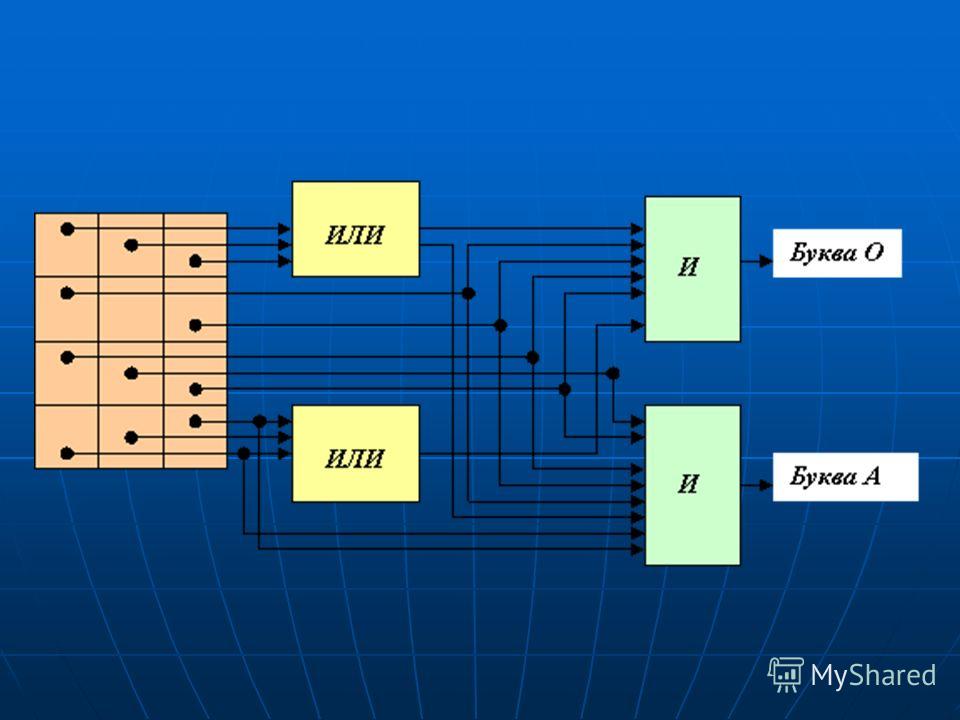
Система распознавания двух "правильно" заданных букв Пометим каждую клетку экрана ее координатами. Тогда на языке математической логики сделанное нами можно записать в виде логических высказываний - предикатов: Пометим каждую клетку экрана ее координатами. Тогда на языке математической логики сделанное нами можно записать в виде логических высказываний - предикатов: (1,2) (2,1) (2,3) (3,1) (3,3) (4,2) - О (1,2) (2,1) (2,3) (3,1) (3,3) (4,2) - О (1,2) (2,1) (2,3) (3,1) (3,2) (3,3) (4,1) (4,3) - А. (1,2) (2,1) (2,3) (3,1) (3,2) (3,3) (4,1) (4,3) - А.

4
Но что делать, если буквы на экране пишутся дрожащей рукой? Тогда мы должны разрешить альтернативную засветку каких-то соседних клеток экрана и учитывать это с помощью операции дизъюнкции, ИЛИ. Как известно, в результате выполнения этой операции формируется единичный сигнал в том случае, если на входе есть хоть один единичный сигнал. Но что делать, если буквы на экране пишутся дрожащей рукой? Тогда мы должны разрешить альтернативную засветку каких-то соседних клеток экрана и учитывать это с помощью операции дизъюнкции, ИЛИ. Как известно, в результате выполнения этой операции формируется единичный сигнал в том случае, если на входе есть хоть один единичный сигнал.

5
Рассмотрим возможность распознав ания буквы О, допустив возможность засветки клеток (1,1), (1,3), (4,1), (4,3). Тогда ранее построенный предикат примет вид Рассмотрим возможность распознав ания буквы О, допустив возможность засветки клеток (1,1), (1,3), (4,1), (4,3). Тогда ранее построенный предикат примет вид ((1,1) (1,2) (1,3)) (2,1) (2,3) (3,1) (3,3) ((4,1) (4,2) (4,3)) - О. Аналогично, для буквы А допустим засветку клеток (1,1) и (1,3): Аналогично, для буквы А допустим засветку клеток (1,1) и (1,3): ((1,1) (1,2) (1,3)) (2,1) (2,3) (3,1) (3,2) (3,3) (4,1) (4,3) - А.
, (1,3), (4,1), (4,3). Тогда ранее построенный предикат примет вид Рассмотрим возможность распознав ания буквы О, допустив возможность засветки клеток (1,1), (1,")
7
Преобразование в нейронную сеть Каждая клетка экрана - это нейрон-рецептор, который в результате засветки обретает некоторую величину возбуждения, принимающую значение между нулем и единицей. Каждая клетка экрана - это нейрон-рецептор, который в результате засветки обретает некоторую величину возбуждения, принимающую значение между нулем и единицей. Рецепторы, заменившие экран, образуют входной, или рецепторный, слой нейросети. Каждый конъюнктор и дизъюнктор заменим единой для всей сети модельюнейрона. Введем выходной слой сети, состоящий в нашем примере из двух нейронов, возбуждение которых определяет результат распознавания. Назовем нейроны выходного слоя по названиям букв - О и А. Рецепторы, заменившие экран, образуют входной, или рецепторный, слой нейросети. Каждый конъюнктор и дизъюнктор заменим единой для всей сети модельюнейрона. Введем выходной слой сети, состоящий в нашем примере из двух нейронов, возбуждение которых определяет результат распознавания. Назовем нейроны выходного слоя по названиям букв - О и А.

9
Проверим, как построенная нейросеть реагирует на четко заданные эталоны букв. Проверим, как построенная нейросеть реагирует на четко заданные эталоны букв. Пусть при показе буквы О засветились нейроны-рецепторы (1, 1), (1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 3), (4, 2). Тогда, при h = 0 величины возбуждения нейронов примут значения V1 = 3, V2 = 1, VO = 8, VA = 7. Пусть при показе буквы О засветились нейроны-рецепторы (1, 1), (1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 3), (4, 2). Тогда, при h = 0 величины возбуждения нейронов примут значения V1 = 3, V2 = 1, VO = 8, VA = 7. Нейрон О возбудился более, чем нейрон А, указывая тем самым, что скорее всего была показана буква О. Аналогично можно рассчитать реакцию нейросети на все возможные конфигурации четко заданных эталонов букв. Нейрон О возбудился более, чем нейрон А, указывая тем самым, что скорее всего была показана буква О. Аналогично можно рассчитать реакцию нейросети на все возможные конфигурации четко заданных эталонов букв.
, (1, 2), (1, 3), (2, 1), (2, 3),")
10
Введем неопределенность. Введем неопределенность. Пусть в процессе показа буквы О четкость утрачена и величины возбуждения нейронов- рецепторов принимают значения Пусть в процессе показа буквы О четкость утрачена и величины возбуждения нейронов- рецепторов принимают значения V(1,1) = 0,2, V(1,2) = 0,7, V(1,3) = 0, V(1,1) = 0,2, V(1,2) = 0,7, V(1,3) = 0, V(2,1) = 0,5, V(2,2) =0,1, V(2,3) = 0,5, V(3,1) = 0,5, V(3,2) = 0,5, V(3,3) = 0,1,V(4,1) = 0,4, V(4,2) = 0,4, V(4,3) = 0,5. Считаем: V1 = 0,9, V2 = 1,3, VO = 3,8, VA = 3,9. V(2,1) = 0,5, V(2,2) =0,1, V(2,3) = 0,5, V(3,1) = 0,5, V(3,2) = 0,5, V(3,3) = 0,1,V(4,1) = 0,4, V(4,2) = 0,4, V(4,3) = 0,5. Считаем: V1 = 0,9, V2 = 1,3, VO = 3,8, VA = 3,9. При таком "крупнозернистом" экране налагаемые на него образы букв О и А пересекаются весьма существенно, и зашумленный показ букв обладает малой устойчивостью. При таком "крупнозернистом" экране налагаемые на него образы букв О и А пересекаются весьма существенно, и зашумленный показ букв обладает малой устойчивостью.

11
Рассмотренный принцип распознавания является обобщением принципа простейшего Персептрона, предложенного Ф. Розенблатом в 1959 г. и ставшего классическим. Рассмотренный принцип распознавания является обобщением принципа простейшего Персептрона, предложенного Ф. Розенблатом в 1959 г. и ставшего классическим.

12
Обучение нейросети задачей обучения является выбор высоких весов некоторых связей и малых весов других связей так, чтобы в соответствии с функциональным назначением сети сложились отношения "посылка - следствие" Здесь ωj - синапсический вес входа или вес связи, по которой передается возбуждение от нейрона j нейр ону i.

13
Обучение сети Для простоты положим максимальный вес связи единичным, а минимальный оставим нулевым. Это соответствует тому, что, интерпретируя связи в сети как "проводочки", мы какие-то из них оставим (считая их сопротивление нулевым), а другие, ненужные, "перекусим". Для простоты положим максимальный вес связи единичным, а минимальный оставим нулевым. Это соответствует тому, что, интерпретируя связи в сети как "проводочки", мы какие-то из них оставим (считая их сопротивление нулевым), а другие, ненужные, "перекусим". Изложенная идея обучения по четко заданным эталонам воплощена в алгоритме трассировки нейросети. Изложенная идея обучения по четко заданным эталонам воплощена в алгоритме трассировки нейросети. На следующем рисунке приведен результат такой трассировки для нашего примера, где выделенные стрелки соответствуют связям с единичными весами, а другие - с нулевыми. На следующем рисунке приведен результат такой трассировки для нашего примера, где выделенные стрелки соответствуют связям с единичными весами, а другие - с нулевыми. Просчитав несколько, в том числе "неопределенных", образов на входе, можно убедиться в ее правильной работе, хотя и демонстрирующей изначально выбранное слабое отличие О от А. Просчитав несколько, в том числе "неопределенных", образов на входе, можно убедиться в ее правильной работе, хотя и демонстрирующей изначально выбранное слабое отличие О от А. Получилась интересная игра. Мы задаем на входе случайные возбуждения и спрашиваем: на что это больше похоже из того, что "знает" нейросеть? Все, что надо сделать, это посчитать в едином цикле для каждого нейроназначение передаточной функции и проанализировать величины возбуждения нейронов выходного слоя. Получилась интересная игра. Мы задаем на входе случайные возбуждения и спрашиваем: на что это больше похоже из того, что "знает" нейросеть? Все, что надо сделать, это посчитать в едином цикле для каждого нейроназначение передаточной функции и проанализировать величины возбуждения нейронов выходного слоя.

14
Трассировка неросети Трассировка неросети

15
Искуственный нейрон где w0 биас(отображает функцию предельного значения, сдвига. Этот сигнал позволяет сдвинуть начало отсчета функции активации, которая в дальнейшем приводит к увеличению скорости обучения ); wі вес i- го нейрона; xі выход i- го нейрона; n количество нейронов, которые входят в обрабатываемый нейрон где w0 биас(отображает функцию предельного значения, сдвига. Этот сигнал позволяет сдвинуть начало отсчета функции активации, которая в дальнейшем приводит к увеличению скорости обучения ); wі вес i- го нейрона; xі выход i- го нейрона; n количество нейронов, которые входят в обрабатываемый нейрон
; wі вес i- го нейрона; xі выход i- го ней")
16
Полученный сигнал NET как правило обрабатывается функцией активации и дает выходной нейронный сигнал OUT Полученный сигнал NET как правило обрабатывается функцией активации и дает выходной нейронный сигнал OUT Если функция активации суживает диапазон изменения величины NET так, что при каждом значении NET значения OUT принадлежат некоторому диапазону конечному интервалу, то функция F называется функцией, которая суживает. В качестве этой функции часто используются логистическая или «сигмоидальная» функция. Эта функция математически выражается следующим образом: Если функция активации суживает диапазон изменения величины NET так, что при каждом значении NET значения OUT принадлежат некоторому диапазону конечному интервалу, то функция F называется функцией, которая суживает. В качестве этой функции часто используются логистическая или «сигмоидальная» функция. Эта функция математически выражается следующим образом:

17
Основное преимущество такой функции то, что она имеет простую производную и дифференцируется по всей оси абсцисс. График функции имеет следующий вид Основное преимущество такой функции то, что она имеет простую производную и дифференцируется по всей оси абсцисс. График функции имеет следующий вид

18
Алгоритм обучения простого перцептрона Подаем на вход компоненты 1й части вектора обучающей выборки Xp = (X1p,..., Xnp), p=1, P. P индекс вектора обучающей выборки. На этой стадии считается выход y = (Xp). Подаем на вход компоненты 1й части вектора обучающей выборки Xp = (X1p,..., Xnp), p=1, P. P индекс вектора обучающей выборки. На этой стадии считается выход y = (Xp). Сравниваем выход сети с желаемым значением. y(xp)? d(xp), d(xp) желаемое значение y(xp) значение сети Если y(xp) == d(xp) (как и надо), то p=p+1, переходим на шаг1. Иначе шаг 3. Сравниваем выход сети с желаемым значением. y(xp)? d(xp), d(xp) желаемое значение y(xp) значение сети Если y(xp) == d(xp) (как и надо), то p=p+1, переходим на шаг1. Иначе шаг 3. Новое значение i-веса: Wi(t) = Wi(t-1) + d(Xp)*Xi. p=p+1, шаг 1 Новое значение i-веса: Wi(t) = Wi(t-1) + d(Xp)*Xi. p=p+1, шаг 1
, p=1, P. P индекс вектора обучающей выборки. На этой стадии считается выход y = (Xp). Подаем на вход компоненты 1й части вектора о")



 Сеть поиска максимума с прямыми связями – слогослойная нейронная сеть определяющая, какой из входных сигналов имеет.")
 X 1 X n... Y 1 Y m Входной слой Скрытый слой (Радиальный) Выходной слой...")
 встречаются такие, при классификации которых.")
")
")







 Кохонена... Выходные.")


 Кохонена... Выходные.")


