Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Выполнила: Медведева Анастасия, Ученица 11А класса, МОУ СОШ 3. Руководитель: Глазунова Ольга Петровна, учитель информатики. «Сжатие данных. Алгоритм Хаффмана»

2
Способы уменьшения объема информации: Ограничение количества информации Увеличение объема носителей Использование сжатия информации

3
Цели и задачи проекта: Узнать, когда и как появились алгоритмы сжатия. Рассмотреть основные виды алгоритмов сжатия. Изучить алгоритм Хаффмана и показать его применение. Научиться решать задачи по данному алгоритму.

4
История появления алгоритмов сжатия. Клод Шеннон Клод Шеннон – основоположник науки о сжатии информации. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и на сколько та или иная информация при этом сожмется.

5
1977 год 1984 год 1977 год – изобретение Лемпелем и Зивом словарных алгоритмов год – изобретение алгоритма PPM и LZV.

6
Теоретические способы уменьшения данных: Изменение содержимого данных Изменение структуры данных Одновременное изменение как содержимого, так и структуры данных

7
Если при сжатии данных происходит изменение их содержимого, то метод сжатия называется необратимым, то есть при восстановлении (разархивировании) данных из архива не происходит полное восстановление информации. Примеры форматов сжатия с потерями: JPEG - для графических данных; MPG - для для видеоданных; MP3 - для аудиоданных. Методы сжатия с регулированными потерями информации.
 данных из архива не происходит полное восстановление информации. Примеры форматов сжатия с потерями: JPE")
8
Если при сжатии данных происходит только изменение структуры данных, то метод сжатия называется обратимым. В этом случае, из архива можно восстановить информацию полностью. Примеры форматов сжатия без потерь информации: GIF, TIFF - для графических данных; AVI - для видеоданных; ZIP, ARJ, RAR, CAB, LH - для произвольных типов данных.

9
Сжатие данных алгоритм RLE (Run Length Encoding) алгоритмы группы KWE (KeyWord Encoding) алгоритм Хаффмана
 алгоритмы группы KWE (KeyWord Encoding) алгоритм Хаффмана")
10
Алгоритм Хаффмана Дэвид Хаффман первопроходец в сфере теории информации. В 1952 году создал алгоритм префиксного кодирования с минимальной избыточностью (известный как алгоритм или код Хаффмана). В 1999 году получил медаль Ричарда Хэмминга за исключительный вклад в теорию информации.
. В 1999 году получил медаль Ричарда Хэмминга за исключи")
11
Определение. Пусть A = {a 1, a 2, …, a n } алфавит из n различных символов, W = {w 1, w 2, …, w n } соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C = {c 1, c 2, …, c n }, такой, что: 1. c i не является префиксом для c j, при i j. 2. Сумма минимальна. ( |c i | длина кода c i ) называется кодом Хаффмана.

12
Характеристики классического алгоритма Хаффмана: Коэффициенты компрессии: Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший коэффициенты). Класс изображений: Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах. Симметричность: Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых данных). Характерные особенности: Характерные особенности: Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
. Класс изображений: Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно")
13
Алгоритм. 1. Составим список кодируемых символов, при этом будем рассматривать один символ как дерево, состоящее из одного элемента, весом, равным частоте появления символа в тексте. 2. Из списка выберем два узла с наименьшим весом. 3. Сформируем новый узел с весом, равным сумме весов выбранных узлов, и присоединим к нему два выбранных узла в качестве дочерних. 4. Добавим к списку только что сформированный узел. 5. Если в списке больше одного узла, то повторить пункты со второго по пятый.

15
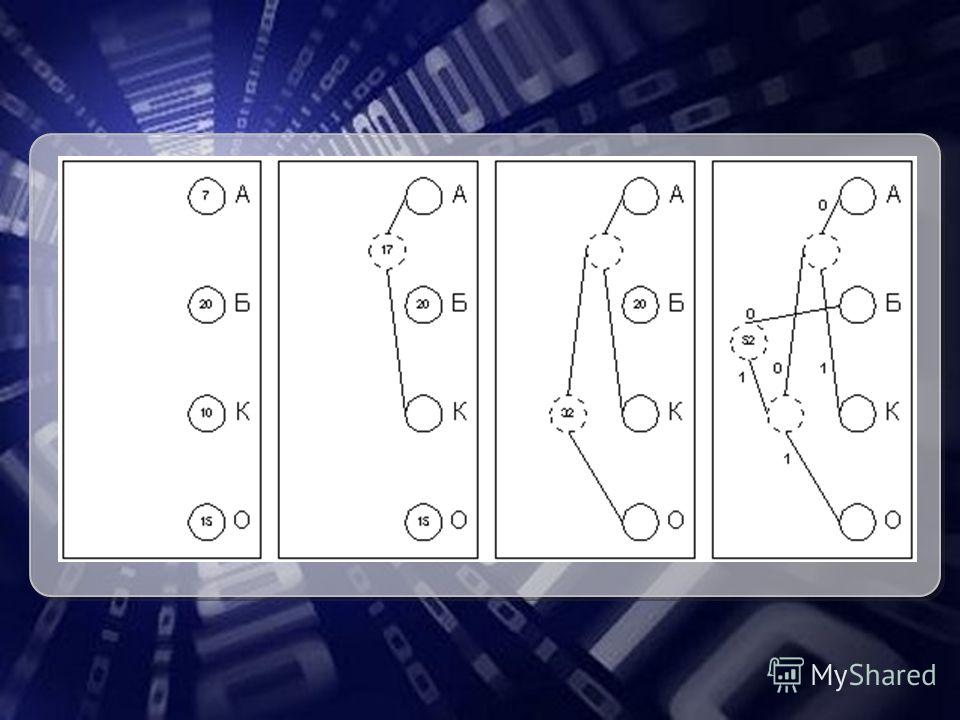
Пример 1. Для примера возьмём слово "Миссисипи". Тогда алфавит будет А={и, м, п, с}, а набор весов W={4, 1, 1, 3}: По алгоритму возьмем два символа с наименьшей частотой - это м и п. Сформируем из них новый узел мп весом 2 и добавим его к списку узлов: Затем объединим в один узел узлы мп и c: Узелимпс Вес4113 Узелимпс Вес423 Узел импс Вес 4 5

16
И, наконец, объединяем два узла и и мпс. Итак, мы получили дерево Хаффмана и соответствующую ему таблицу кодов: Таким образом, закодированное слово "Миссисипи" будет выглядеть как " ". Длина закодированного слова - 16 бит. Стоит заметить, что если бы мы использовали для кодирования каждого символа из четырёх по 2 бита, длина закодированного слова составила бы 18 бит. Символим п с Код

17
Пример 2. Предположим, что нам надо заархивировать следующую символьную последовательность: "AAABCCD". Без архивации эта последовательность занимает 7 байт. С архивацией по методу RLE она бы выглядела бы так: 3,"A",1,"B",2,"C",1,"D" то есть возросла бы до 8-ми байтов. А алгоритм Хаффмана может сократить ее почти до двух байтов, и вот как это происходит.

18
Таблица частот: Двоичное дерево: Символ 'A','B','C,'D' Количество повторений '3','1','2','3'

19
A A A B B C C D Рассмотренный нами выше текст "AAABCCD" займет всего 13 бит (а это меньше двух байтов). A A A B C C D A A A B C C D
. A A A B C C D 0 0 0 111 10 10 110 A A A B C C D 0 0 0 111 10 10 110")
20
Пример 3. Рассмотрим использование алгоритма Хаффмана на пример оптимизации занимаемого пространства БД при хранении массива, состоящего из целых чисел в диапазоне [0,255]. Массив представляет собой отображение звуковой информации wav-файла. Среднее количество хранимых элементов массива составляет ~ Результаты представления массива после различных преобразований массива $data с 9288 элементами (в символах):
![Пример 3. Рассмотрим использование алгоритма Хаффмана на пример оптимизации занимаемого пространства БД при хранении массива, состоящего из целых чисел в диапазоне [0,255]. Массив представляет собой отображение звуковой информации wav-файла. Среднее](http://images.myshared.ru/6/552229/slide_20.jpg "Пример 3. Рассмотрим использование алгоритма Хаффмана на пример оптимизации занимаемого пространства БД при хранении массива, состоящего из целых чисел в диапазоне [0,255]. Массив представляет собой отображение звуковой информации wav-файла. Среднее")
21
Список используемой литературы: Веретенников А.Б «Алгоритм Хаффмана», 2008 г. Материалы для подготовки к ЕГЭ. Ресурсы Интернет.

Еще похожие презентации в нашем архиве:








. Кодирование информации Кодирование числовой информации Диапазон целых чисел, кодируемых одним байтом, определяется.")










