Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Архитектура P6

2
Начало разработки: 1990 год Цель: Достигнуть производительности большей, чем процессоры архитектуры P5 и процессоры конкурентов. Процессоры Pentium Pro (1995) до 200 МГц Pentium II (1997) до 450 МГц Pentium III (1999) до 1.3 ГГц Pentium M (2003) до 2.26 ГГц
 до 200 МГц Pentium II (1997) до 450 МГц Pentium III (1999) до 1.3 ГГц Pentium M (2003) до 2")
3
Архитектура P6 Начало разработки: 1990 год Цель: Достигнуть производительности большей, чем процессоры архитектуры P5 и процессоры конкурентов. Процессоры Pentium Pro (1995) до 200 МГц Pentium II (1997) до 450 МГц Pentium III (1999) до 1.3 ГГц Pentium M (2003) до 2.26 ГГц
 до 200 МГц Pentium II (1997) до 450 МГц Pentium III (1999) до 1.3 ГГц Pentiu")
4
Архитектура P6 Отличительные особенности ядра 12-стадийный суперконвейер Внешний интерфейс CISC, внутреннее ядро RISC Двойная независимая шина Динамическое исполнение команд –Предсказание ветвлений –Переименование регистров –Спекулятивное исполнение –Исполнение вне порядка –Суперскалярное исполнение Возможно исполнение до 3-х команд за такт.

5
Упрощенная структура конвейера P6 Входной блок упорядоченной обработки команд (In-order front end) Исполнительное ядро с изменением порядка исполнения (Out-of-order execution core) Блок упорядоченного завершения команд (In- order retirement)
 Исполнительное ядро с изменением порядка исполнения (Out-of-order execution core) Блок упорядоченного завершения команд (In- order retirement)")
7
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF

8
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Определение адреса следующей команды (на основании BTB).
.")
9
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Чтение 2 кэш-строк, выборка пакета 16B, выравнивание пакета.

10
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Декодирование: преобразование команд в uOPs. Обработка максимум 3-х команд x86 (6 uOPs: 4-1-1) за такт.
 за такт.")
11
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Декодирование: преобразование команд в uOPs. Максимум 1 команда перехода за такт. Информация о ветвлениях отправляется в BTB.

12
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF На входе очереди максимум 6 uOPs за такт (4-1-1). На выходе очереди максимум 3 uOPs за такт.
. На выходе очереди максимум 3 uOPs за такт.")
13
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Создается запись в Reorder Buffer. Отображение программных регистров на физические.

14
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Чтение операндов для uOP.

15
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Когда операнды готовы, uOP помещается в станцию резервации (RS) и ждет исполнения.
 и ждет исполнения.")
16
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF В произвольном порядке uOP-ы запускаются на исполнение на различных исполнительных устройствах. Максимум 5 результатов за такт.

17
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Операции чтения данных из памяти.

18
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Операции записи данных в память.

19
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Запись результатов в Reorder Buffer.

20
Структура ядра P6 Стадии конвейера: 1.BTB0 2.BTB1 3.IFU0 4.IFU1 5.IFU2 6.ID0 7.ID1 8.RAT 9.ROB read 10.RS 11.Ex 12.ROB write 13.RRF Завершение. Запись результатов в выводящий регистровый файл (RRF). Удаление uOPs из ROB. Запись данных в память. Максимум 3 uOPs за такт.
. Удаление uOPs из ROB. Запись данных в память. Макси")
21
Блок неупорядоченного исполнения P6

22
Архитектура P7 NetBurst

23
Архитектура NetBurst Цель: Достигнуть большой производительности за счет повышения тактовой частоты. Средства: Большой конвейер с маленькими стадиями –Уменьшение задержек на ветвления – кэш трасс, большой BTB –Уменьшение задержек на обращение к памяти – быстрый кэш Уменьшение команд, необходимых для выполнения задачи –Векторное расширение SSE2 Процессоры Pentium 4 –Willametteдо 2.4 ГГц –Northwoodдо 3.2 ГГц –Prescottдо 3.х ГГц

24
Архитектура NetBurst Отличительные особенности ядра 20 или 31-стадийный гиперконвейер Внешний интерфейс CISC, внутреннее ядро RISC Динамическое исполнение команд –Предсказание ветвлений –Переименование регистров –Спекулятивное исполнение –Исполнение вне порядка –Суперскалярное исполнение Кэш трасс (работает на половине частоты) Небольшая кэш-память с быстрым доступом Часть ядра работает на удвоенной частоте Возможно исполнение до 3-х команд за такт.

25
Структура ядра архитектуры NetBurst

26
Кэш трасс Состоит из 2048 блоков по 6 ячеек (256 наборов по 8 блоков) Все блоке в каждой трассе связаны в двунаправленный список Темп чтения – 1 блок за 2 такта
 Все блоке в каждой трассе связаны в двунаправленный список Темп чтения – 1 блок за 2 такта")
27
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive

28
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Определение адреса следующей uOP в кэше трасс.

29
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Выборка из кэша трасс в очередь предвыборки до 6 uOPs за 2 такта, подстановка MROM векторов.

30
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Продвижение…

31
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Выборка 3 uOPs из очереди. Выделение ресурсов процессора (места в очередях, буфере переупорядочивания, регистровом файле).

32
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Отображение логических регистров на физические.

33
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Размещение uOP-ов в 2-х очередях uopQ: для операций с памятью и для остальных операций.

34
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive 5 планировщиков в зависимости от типа операции выбирают uOPы из очередей uopQ каждый в свою очередь schQ (аналог RS).

35
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Распределение uOPs из 5-ти очередей schQ по 4-м портам исполнительных устройств в произвольном порядке.

36
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Чтение операндов из регистрового файла.

37
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Исполнение

38
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Установка флагов.

39
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Проверка правильности предсказания переходов.

40
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Перенос результата проверки перехода в декодер.

41
Стадии конвейера P7 1.TC next IP 1 2.TC next IP 2 3.TC Fetch 1 4.TC Fetch 2 5.Drive 6.Allocator 7.Rename 1 8.Rename 2 9.Queue 10.Schedule 1 11.Schedule 2 12.Schedule 3 13.Dispatch 1 14.Dispatch 2 15.Register file 1 16.Register file 2 17.Execute 18.Flags 19.Branch check 20.Drive Далее uOP ждет отставки для освобождения ресурсов и записи результатов. Отставка происходит последовательно над теми же тройками uOPs, которые были сформированы на стадии Allocator.

42
Конвейер NetBurst Исполнение вне порядка Исполнение в порядке поступления команд

43
Исполнительные устройства

44
Rapid Execution Engine Работает на удвоенной частоте ядра Включает: –2 планировщика быстрых целочисленных операций –Целочисленный регистровый файл –Порты запуска 0 и 1 –Быстрые АЛУ.

45
NetBurst Replay

47
Изменения в ядре Prescott Длина конвейера увеличилась до 31 стадии Увеличился объем и латентность кэш-памяти Добавилось расширение SSE3 Улучшенная предвыборка данных Улучшенное предсказание ветвлений Дополнительные буферы комбинированной отложенной записи в память Ускорение некоторых операций с целыми числами (умножение, …)

48
Архитектура Core

49
Разработана на основе P6. Цель: увеличить производительность, снизить энергопотребление и тепловыделение. Процессорные ядра: Merom, Conroe, Woodcrest Kentsfield, Clovertown … Пока до 2.93 ГГц

50
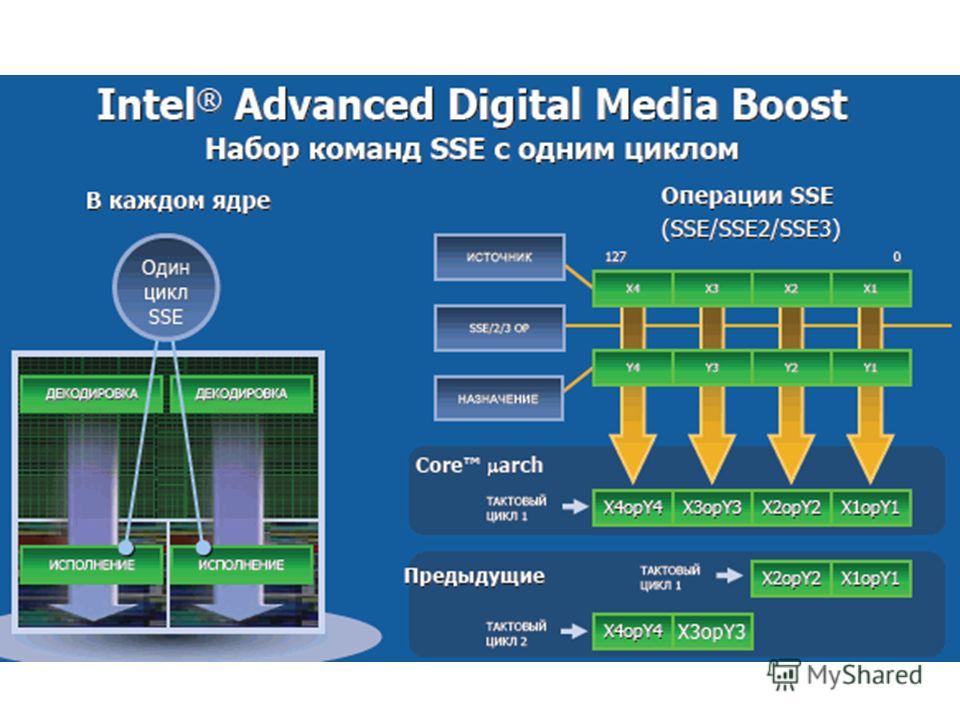
Архитектура Core Реализованы новые технологии: Intel Wide Dynamic Execution –выполнение до четырех инструкций за такт Intel Intelligent Power Capability –снижается энергопотребление системы Intel Advanced Smart Cache –общая для всех ядер кэш-память L2 Intel Smart Memory Access –оптимизирует использование пропускной способности подсистемы памяти Intel Advanced Digital Media Boost –позволяет обрабатывать все 128-разрядные команды SSE, SSE2, SSE3, … за один такт

52
Intel Wide Dynamic Execution

55
Разрешение конфликтов (между операциями чтения и записи) по адресам обращения к памяти.
 по адресам обращения к памяти.")
Еще похожие презентации в нашем архиве:












 Параллелизм команд (ILP – Instruction.")

 задач одновременно, а.")





 – микросхема, которая обрабатывает информацию и управляет всеми устройствами.")

 проф. Петрова И.Ю. Курс Информатики.")


. Шина AMD Athlon AMD Opteron.")


