Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Методы определения семантической близости документов

2
Области применения: 1.Текстовый поиск в интернете. 2.Поиск «близких» документов. 3.Классификация текстов. 4.Устранение многозначности.

3
Методы: 1.По тексту 2.По связям

4
Методы: 1.По тексту 2.По связям

5
Латентно-семантический анализ

6
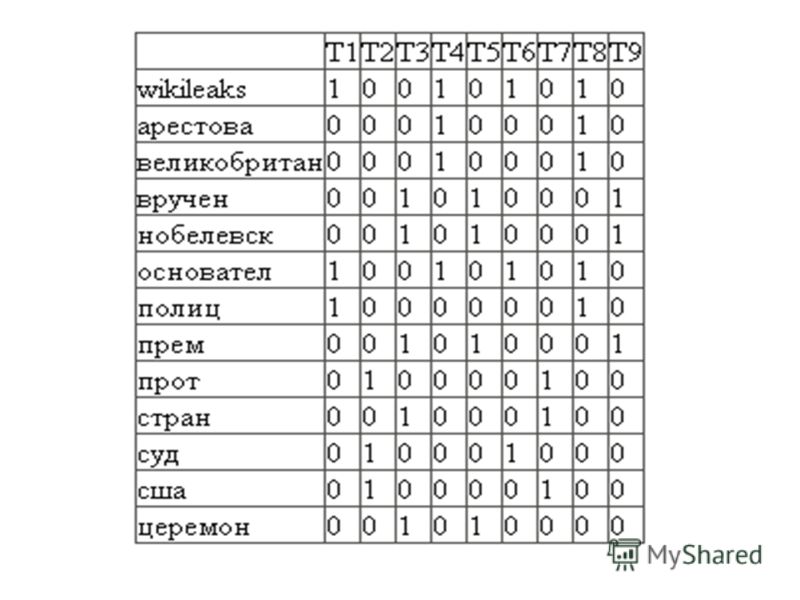
Задача: кластеризовать новости по заголовкам.

7
Британская полиция знает о местонахождении основателя WikiLeaks В суде США начинается процесс против россиянина, рассылавшего спам Церемонию вручения Нобелевской премии мира бойкотируют 19 стран В Великобритании арестован основатель Wikileaks Джулиан Ассандж Украина игнорирует церемонию вручения Нобелевской премии Шведский суд отказался рассматривать апелляцию основателя Wikileaks НАТО и США разработали планы обороны стран Балтии против России Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала В Стокгольме и Осло сегодня состоится вручение Нобелевских премий

8
Подготовка: 1.Удаление стоп-слов 2.Стемминг 3.Удаление слов в единст- венном экземпляре

9
Британская полиция знает о местонахождении основателя WikiLeaks В суде США начинается процесс против россиянина, рассылавшего спам Церемонию вручения Нобелевской премии мира бойкотируют 19 стран В Великобритании арестован основатель Wikileaks Джулиан Ассандж Украина игнорирует церемонию вручения Нобелевской премии Шведский суд отказался рассматривать апелляцию основателя Wikileaks НАТО и США разработали планы обороны стран Балтии против России Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала В Стокгольме и Осло сегодня состоится вручение Нобелевских премий

10
Считаем количество раз вхождения каждого слова в документы и заносим в матрицу.

12
Сингулярное разложение матрицы: M = U*W*V t U и V t – ортогональные W – диагональная (элементы в порядке неубывания)
")
14
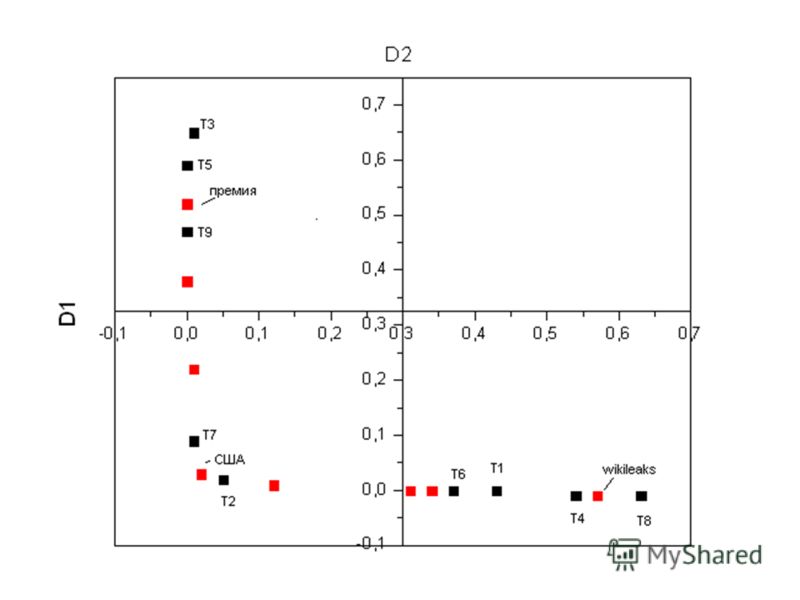
Строки и столбцы с меньшим сингулярным числом дают меньший вклад в произведение. Оставим только 2 самых весомых.

17
Методы: 1.По тексту 2.По связям

18
Методы, использующие связи: абстрагируемся от текста, важны только связи между документами. Унификация.

19
1.Локальные 2.Глобальные

20
1.Локальные 2.Глобальные

21
Локальные: близость определяется для пары вершин и не затрагивает большинство вершин.

22
Ближайшие соседи:

23
N(a) – множество ближайших соседей узла a
 – множество ближайших соседей узла a")
24
Коэффициент Жаккара: Коэффициент Дайса: СимКос:

25
Для направленных графов: Со-цитирование Библиографическое сочетание

26
1.Локальные 2.Глобальные

27
Глобальные: вычисляют близость между всеми вершинами графа.

28
SimRank: два объекта похожи, если на них ссылаются похожие объекты C – коэффициент затухания.

29
Метод итеративен.

30
Затраты времени и памяти. Базовый подход. O(n 2 ) памяти. O(Kn 2 d 2 ) времени, где: K – количество итераций d 2 – среднее значение |I(a)||I(b)| по всем (a, b)
 памяти. O(Kn 2 d 2 ) времени, где: K – количество итераций d 2 – среднее значение |I(a)||I(b)| по всем (a, b)")
31
Затраты времени и памяти. Улучшенный подход: рассматриваем только близкие вершины в графе. Пусть r – радиус в котором рассматриваются соседи. d r – среднее количество соседей в r. O(d r n) памяти O(Knd r d 2 ) времени
 памяти O(Knd r d 2 ) времени")
32
??

Еще похожие презентации в нашем архиве:





 - граф, ребрам или дугам которого поставлены в соответствие числовые величины.")




 метода при автоматизированном проектировании информационных систем.")
 называют произведение натуральных.")





 метода при автоматизированном проектировании информационных систем.")

 называют произведение натуральных.")


