Скачать презентацию
1
Архитектуры с параллелизмом на уровне команд

3
Два класса Суперскалярные процессоры Процессоры с длинным командным словом

5
Динамическое исполнение команд в суперскалярном процессоре Предсказание ветвлений (переходов) (branch prediction). Переименование регистров, чтобы удалить зависимости между данными и регистрами, невидимые компилятору (register renaming). Спекулятивное исполнение предсказанных переходов (speculative execution of predicted branches) Исполнение команд вне порядка (out-of- order instruction execution)
 (branch prediction). Переименование регистров, чтобы удалить зависимости между данными и регистрами, невидимые компилятору (register renaming). Спекулятивно")
6
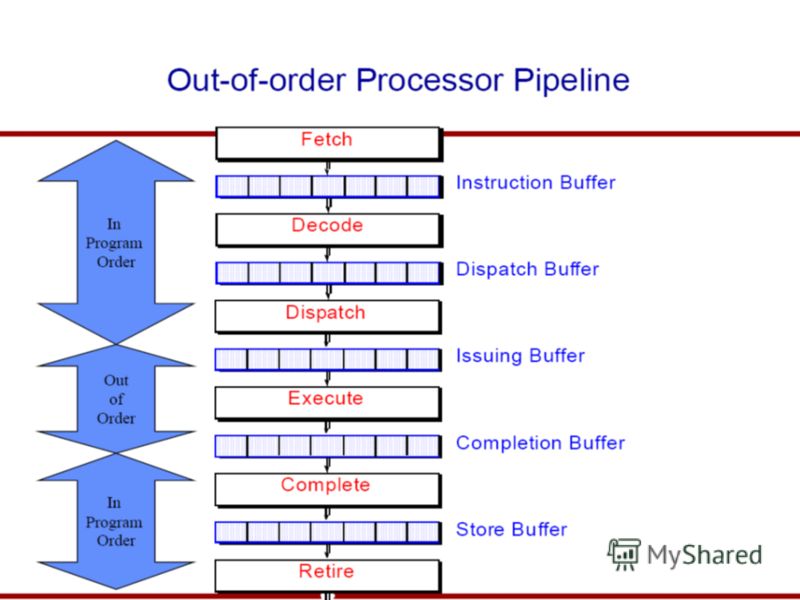
Как реализован конвейер? Устройство предварительной обработки инструкций в порядке их следования в программном коде (front end). Исполнение вне порядка (Out-Of- Order execution). Блок упорядоченного завершения (In-order retirement).
. Исполнение вне порядка (Out-Of- Order execution). Блок упорядоченного завершения (In-order retirement).")
9
Упрощенная схема процессора

10
Устройство front end Предсказание следующей инструкции. Используются два алгоритма предсказания переходов. Динамический алгоритм работает на стадии выборки. Статический алгоритм работает на стадии декодирования. Статический алгоритм использует правила: -- безусловные переходы выполняются, -- условные переходы назад выполняются, -- переходы вперед не выполняются (это соответствует обычному циклу).

11
Предсказание следующей инструкции История поведения условных переходов хранятся в таблицах BHT (Branch History Table) и BTB (Branch Target Buffer ). Устройства аналогично устройству КЭШа, только вместо данных в BHT хранится история поведения условных переходов, а в BTB хранится результат предсказания.
 и BTB (Branch Target Buffer ). Устройства аналогично устройству КЭШа, только вместо данных в BHT хранится история поведения условных")
12
Двубитный предсказатель

13
Гибридный предсказатель История локального поведения (BHT) 1024 х 10bit Локальный предсказатель 1024 х 3bit Program Counter Глобальный предсказатель 4096 х 2bit Выбор предсказателя История работы Предсказание
 1024 х 10bit Локальный предсказатель 1024 х 3bit Program Counter Глобальный предсказатель 4096 х 2bit Выбор предсказателя История работы Предсказание")
14
Устройство front end Выборка потока инструкций. Декодирование инструкций в микрооперации. Переименование внешних регистров. Размещение ВУ и запоминание статуса каждой микрооперации в переупорядочивающем буфере ( Reorder buffer (ROB) ) в исходном порядке инструкций.
 ) в исходном поря")
15
Переименования регистров Переименование регистров основано на динамическом отображении логических ресурсов в физические (аппаратные) ресурсы процессора. Отображение номеров логических регистров в номера физических регистров хранится в таблице подстановки (lookup table) ((таблица псевдонимов регистров (RAT))). Строки таблицы обновляются после декодирования каждой команды. Очередной результат записывается в новый физический регистр, но значение каждого логического регистра запоминается, чтобы легко восстановиться в случае неправильного предсказания направления условного перехода или прерывания команды из-за возникновения исключительной ситуации. Когда команда создает новое значение для логического регистра, физический ресурс, в который помещается это значение, получает имя. Последующие команды, использующие это значение, снабжаются именем физического ресурса. Эта процедура называется переименованием регистров. Таким образом, в результате переименования с одним логическим ресурсом может быть связано несколько значений в различных физических ресурсах.
 ресурсы процессора. Отображение номеров логических регистров в номера физических регистров хранится в таблице подстан")
16
Пример переименования регистров (1)a = x + f;a = x + f; (2)b = a * z;b = a * z; (3)a = a + v;a1 = a + v; (4)d = a * b;d = a1 * b;
a = x + f;a = x + f; (2)b = a * z;b = a * z; (3)a = a + v;a1 = a + v; (4)d = a * b;d = a1 * b;")
17
Каждый МОП может проходить через следующие стадии : 1 -- находится в очереди планировщика, но ещё не готов к исполнению; 2 -- готов к исполнению (все аргументы операции вычислены); 3 -- запущен на исполнение (диспетчеризован); 4 -- исполнен и ждёт отставки либо отмены спекулятивной ветви; 5 -- находится в процессе отставки.
; 3 -- запущен на исполнение (диспетчеризован); 4 -- исполнен и ждёт от")
18
Устройство Out-Of-Order execution Планирование и распределение микроопераций Выполнение микроопераций и запоминание их результатов временно в буфере ROB.

19
Блок упорядоченного завершения Запись результатов обратно во внешние архитектурные регистры, постоянная запись данных, если это необходимо. Изъятие микроопераций из буфера ROB.

20
Блок упорядоченного завершения Блок упорядоченного завершения отражает результаты выполнения микроопераций в изменениях состояния архитектурных (логичес- ких) регистров, внешней памяти и портов. Назначение блока – сохранение последователь- ной модели исполнения программы при реальном параллельном выполнении команд и условном выполнении команд ветвления. Рассматриваются логическое и физическое состояния процессора. Физическое состояние изменяется немедленно по завершении очередной команды. Логическое состояние изменяется, когда ясен результат условно исполненных команд.
 регистров, внешней памяти и портов. Назначение блока – сохранение последователь- ной модели")
21
Pentium III

22
Alpha 21264

23
Athlon

24
Opteron

25
Гипертранспорт






 Параллелизм команд (ILP – Instruction.")





.")


 Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru Киреев Сергей Евгеньевич,")
 организации памяти заключается в использовании на одном компьютере нескольких.")
 Кафедра Параллельных вычислительных технологий Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru.")







