Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

2
Представим, что перед нами стоит задача перемножить две матрицы A и B размера n×n. Как можно это осуществить?

3
Применим алгоритм, действующий прямо по определению (назовем его Iterative). for i
. for i")
4
Время его выполнения на реальной машине: 140 c (N = 2 10 ) Тестирование происходило на системе: Intel Core i5 2.27Ghz 4096 Mb L1 32 Kb x2 64 B L2 256 Kb x2 64 B Windows 7
 Тестирование происходило на системе: Intel Core i5 2.27Ghz 4096 Mb L1 32 Kb x2 64 B L2 256 Kb x2 64 B Windows 7")
5
Разобьём каждую матрицу на (n/s)*(n/s) подматриц Мij размером s×s Следующий алгоритм использует эту стратегию( Block-Mult ): for i
*(n/s) подматриц Мij размером s×s Следующий алгоритм использует эту стратегию( Block-Mult ): for i")
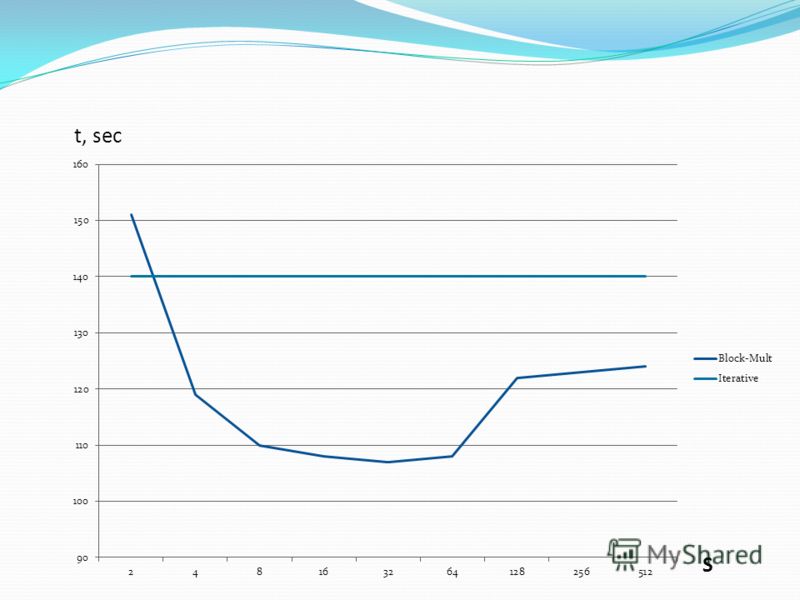
6
Изменение времени работы алгоритма от параметра s:

8
Для умножения можно воспользоваться следующим алгоритмом (обозначим его за Mult(A)): Для умножения матрицы A размером m×n на матрицу размером n×p рассматривается три случая: m >= max{n, p} AB = ( )B = ( ) n> = max{m,p} AB = (A 1 A 2 )( ) = A 1 B 1 + A 2 B 2 p> = max{m,n} AB = A(B 1 B 2 ) = (AB 1 AB 2 ) Это продолжается пока m = n = p = 1. A1 A2 A1B A2B B1 B2
): Для умножения матрицы A размером m×n на матрицу размером n×p рассматривается три случая: m >= max{n, p} AB = ( )B = ( ) n> = max{m,p} AB = (A 1 A 2 )( ) = A 1 B 1 +")
9
Время его работы можно увидеть на графике:

10
Исследователи из MIT 1994 Чарльз Лейзерсон 1997 Гаральд Прокоп 1999

11
(Z, L) – идеальная модель кэша(ideal-cache model)(она будет использоваться для оценки сложности кэша (cache complexity))
 – идеальная модель кэша(ideal-cache model)(она будет использоваться для оценки сложности кэша (cache complexity))")
12
Кэш-линии(cache lines) Высокий кэш(tall cache) (Z = (L 2 )) Попадание в кэш (cache hit) Промах кэша (cache miss) W(n) - рабочая сложность (work complexity) Q(n, Z, L) - кэш сложность (cache complexity). Кэш зависимый (cash aware) Кэш-независимый (cache oblivious)
 Высокий кэш(tall cache) (Z = (L 2 )) Попадание в кэш (cache hit) Промах кэша (cache miss) W(n) - рабочая сложность (work complexity) Q(n, Z, L) - кэш сложность (cache complexity). Кэш зависимый (cash aware) Кэш-независимый (cac")
13
Будут ли кэш-независимые алгоритмы, разработанные в рамках идеальной модели, работать также эффективно для модели с политиками LRU и FIFO или другой иерархией кэша? (Кэш сложность будет называться нормальной (regular), если Q(n; Z, L) = O(Q(n; 2Z, L))) Теорема: Оптимальный кэш-независимый алгоритм с нормальной кэш сложностью остается оптимальным в двухуровневой модели с вытесняющими политиками (LRU, FIFO).
, если Q(n; Z, L) = O(Q(n; 2Z, L)")
14
- многоуровневая идеальная модель Свойство вложенности (inclusion property): Ʉi є [1,…, r-1] значения, хранимые в кэше i, хранятся и в кэше i+1 W(n), Qi(n; Zi, Li) - кэш сложности для i є[1,…,r] Теорема: Если кэш-независимый алгоритм оптимален в многоуровневой идеальной модели, то он вызывает оптимальное количество потерь кэша и на каждом уровне кэша. Теорема: Оптимальный кэш независимый алгоритм с нормальной кэш сложностью вызывает асимптотически оптимальное количество потерь кэша на каждом уровне кэша с оптимальной вытесняющей политикой или LRU. (Доказательство этих теорем можно найти в Harald Prokop. Cache-Oblivious Algorithms. Masters thesis, MIT )
![- многоуровневая идеальная модель Свойство вложенности (inclusion property): Ʉi є [1,…, r-1] значения, хранимые в кэше i, хранятся и в кэше i+1 W(n), Qi(n; Zi, Li) - кэш сложности для i є[1,…,r] Теорема: Если кэш-независимый алгоритм оптимален в мног](http://images.myshared.ru/4/286431/slide_14.jpg "- многоуровневая идеальная модель Свойство вложенности (inclusion property): Ʉi є [1,…, r-1] значения, хранимые в кэше i, хранятся и в кэше i+1 W(n), Qi(n; Zi, Li) - кэш сложности для i є[1,…,r] Теорема: Если кэш-независимый алгоритм оптимален в мног")
15
Нужно перемножить две матрицы A и B размера n×n. Будем считать, что матрицы хранятся в построчном порядке и что n>L(чтобы упростить анализ). Построчный (row major) По столбцам (column major)
. Построчный (row major) По столбцам (column major)")
16
Iterative: for i

17
Block-Mult: for i

18
Mult(A): Для умножения матрицы A размером m×n на матрицу размером n×p рассматривается три случая: m >= max{n, p} AB = ( )B = ( ) n> = max{m,p} AB = (A 1 A 2 )( ) = A 1 B 1 + A 2 B 2 p> = max{m,n} AB = A(B 1 B 2 ) = (AB 1 AB 2 ) Это продолжается пока m = n = p = 1. ϴ(mnp), ϴ(m + n + p + (mn + np + mp)/L + mnp/L(Z 1/2 )) A1 A2 A1B A2B B1 B2
: Для умножения матрицы A размером m×n на матрицу размером n×p рассматривается три случая: m >= max{n, p} AB = ( )B = ( ) n> = max{m,p} AB = (A 1 A 2 )( ) = A 1 B 1 + A 2 B 2 p> = max{m,n} AB = A(B 1 B 2 ) = (AB 1 AB 2 ) Это продолжается пока")
19
1. Самый быстрый с точки зрения асимптотической сложности алгоритм имеет не больше (lg Z) промахов кэша, чем асимптотически самый быстрый кэш зависимый алгоритм. 2. Если существует класс оптимальных кэш зависимых алгоритмов, решающих определённую задачу, то существует кэш-независимый алгоритм, решающий ту же задачу.
 промахов кэша, чем асимптотически самый быстрый кэш зависимый алгоритм. 2. Если существует класс оптимальных кэш зависимых алгоритмов, решающих определённую зад")
20
Нужно транспонировать квадратную A матрицу размера N×N. Применим алгоритм, действующий прямо по определению (назовем его Iterative). for (i = 0; i < N; i++) { for (j = i+1; j < N; j++) { tmp = A[i][j]; A[i][j] = A[j][i]; A[j][i] = tmp; }
![Нужно транспонировать квадратную A матрицу размера N×N. Применим алгоритм, действующий прямо по определению (назовем его Iterative). for (i = 0; i < N; i++) { for (j = i+1; j < N; j++) { tmp = A[i][j]; A[i][j] = A[j][i]; A[j][i] = tmp; }](http://images.myshared.ru/4/286431/slide_20.jpg "Нужно транспонировать квадратную A матрицу размера N×N. Применим алгоритм, действующий прямо по определению (назовем его Iterative). for (i = 0; i < N; i++) { for (j = i+1; j < N; j++) { tmp = A[i][j]; A[i][j] = A[j][i]; A[j][i] = tmp; }")
21
Рассмотрим время его выполнения на реальной машине: Тестирование происходило на системе: UltraSPARC-II 300 MHz 512 мб L1 32 б 16 кб L2 64 б 2 мб SunOS 5.6 SUNs Workshop 4.2.

22
Время работы от размера от изменения входных данных можно увидеть на графике:

23
Если учесть затраты на ввод и вывод данных между кэшем и основной памятью, то можно в несколько раз уменьшить время работы алгоритма. Z - размер всего кэша L - длина линий кэша Aʳ΄ˢ = { ai,j | rL

24
Пример его применения: L =

25
Время его работы можно увидеть на графике:

26
Для транспонирования можно воспользоваться следующим алгоритмом (обозначим его за Transpose(A)): Вход: Матрица A размера m×n Выход: Матрица B размера n×m Если n>=m A = (A1 A2) B = ( ) Если n
): Вход: Матрица A размера m×n Выход: Матрица B размера n×m Если n>=m A = (A1 A2) B = ( ) Если n")
27
Время его работы можно увидеть на графике:

28
Изменим размер линий кэша (L = 2 7 )
")
29
Изменим размер линий кэша (L = 2 6 )
")
30
Изменим размер линий кэша (L = 2 5 )
")
31
Гареев Роман КН - 301, 2011 год

Еще похожие презентации в нашем архиве:







 организации памяти заключается в использовании на одном компьютере нескольких.")


: P(x X x + x)=F(x + x) - F(x) F(x). § 6. Непрерывная случайная величина. Функция плотности. Пусть X.")


.P-сложныеNP-сложные.")

 Семейство приближенных алгоритмов для задачи Π, {A ε } ε называется.")




 Семейство приближенных алгоритмов для задачи Π, {A ε } ε называется.")

