Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Основные понятия регрессионного анализа

2
Регрессионный анализ –метод математической статистики, позволяющий в эконометрике изучать зависимость одной экономической переменной от других.

3
Вначале рассматриваем случай, когда одна переменная зависит только от одной другой переменной. До сих пор для изучения связи между двумя переменными использовался коэффициент корреляции. Он может показать, что две случайные величины связаны друг с другом, но не показывает, каким образом они связаны.

4
Если мы предполагаем, что из двух переменных одна зависит от другой, мы должны рассматривать их взаимосвязь в рамках регрессионной модели.

5
Пусть X – еженедельный доход в $, Y – еженедельное потребление в $. По этим факторам у нас есть данные для 60 человек.

8
Для этой группы из 60 человек мы хотим построить модель зависимости потребления от дохода.

9
Любая модель обязательно представляет основные закономерности моделируемого процесса или явления.

10
Видим, что для нашей группы из 60 объектов (людей) взаимосвязь доходов и потребления имеет следующие закономерности: с ростом дохода потребление растет; потребление линейно зависит от дохода.
 взаимосвязь доходов и потребления имеет следующие закономерности: с ростом дохода потребление растет; потребление линейно зависит от дохода.")
11
Графически модель зависимости потребления Y от дохода Х должна представлять собой прямую линию. Как ее провести?

12
Так? Наверное, нет, так как такая модель сильно занижает Y для малых Х и завышает для больших.

13
Так? Наверное, нет, так как занижается потребление Y для всех Х.

14
Так? Для большинства из 60 человек потребление Y завышается.

15
В РА линия, графически представляющая модель регрессии, проводится через средние для каждого Х значения Y.

16
Для дохода Х = 80 прямая пройдет через точку с Y = среднему арифметическому всех Y с Х=80. То есть Y = ( )/5 = 65. Эта точка (80; 65) показана розовым цветом на графике.
/5 = 65. Эта точка (80; 65) показана розовым цветом на графике.")
17
Для дохода Х = 100 прямая пройдет через точку с Y = среднему арифметическому всех Y с Х=100. То есть Y = ( )/6 = 77. Эта точка (100; 77) также показана розовым цветом на графике.
/6 = 77. Эта точка (100; 77) также показана розовым цветом на графике.")
18
И т. д.

19
Ордината каждой «розовой точки» - это условное среднее, или условное математическое ожидание Y при данном значении Х: E(Y | X)
")
20
E(Y|X=80) = E(Y|80) = 65 E(Y|X=100) = E(Y|100) = 77 E(Y|X=120) = E(Y|120) = 89 и т.д.
 = E(Y|80) = 65 E(Y|X=100) = E(Y|100) = 77 E(Y|X=120) = E(Y|120) = 89 и т.д.")
22
В РА строятся модели, которые представляют строгую функциональную зависимость не между Х и Y, а между Х и средними Y, соответствующими данным значениям Х.

23
В случае, когда функция регрессии линейная, она может быть записана в следующем общем виде: E(Y|X) = β 1 + β 2 *X
 = β 1 + β 2 *X")
24
В нашем случае: E(Y|X) = ,6*X. При Х=80, E(Y|X) = 17+0,6*80 = 65. При Х=100, E(Y|X) = 17+0,6*100 = 77. И т.д.
 = 17 + 0,6*X. При Х=80, E(Y|X) = 17+0,6*80 = 65. При Х=100, E(Y|X) = 17+0,6*100 = 77. И т.д.")
25
В модели регрессии значение фактора Х точно определяет не значение Y, а среднее значений Y, соответствующих этому значению Х. E(Y|X) = f (X) или E(Y|X i ) = f(X i )
 = f (X) или E(Y|X i ) = f(X i )")
26
Помимо Х, на Y может влиять множество других, неизмеримых факторов.

27
Например, на потребление человека, помимо его дохода, могут влиять его склонности, религия, традиции его семьи, состояние здоровья, уверенность или неуверенность в себя и т.д. Как учесть эти влияния в модели?

28
Если бы потребление определялось только доходом, то есть Y зависел бы только от Х, то все точки выборки лежали на прямой регрессии. Модель регрессии тогда бы имела вид не E(Y|X) = β 1 + β 2 *X, а Y = β 1 + β 2 *X.
 = β 1 + β 2 *X, а Y = β 1 + β 2 *X.")
29
В том, что точки разбросаны вокруг прямой регрессии, проявляется влияние на Y всех прочих факторов. Влияние всех этих прочих факторов учитывается в модели регрессии путем введения в модель слагаемого u: Y = β 1 + β 2 *X.+ u.

30
Рассмотрим, например, как, согласно модели регрессии, образуются потребительские расходы 52-го индивида в нашей выборке. Этот человек имеет доход Х 52 =240 и потребительские расходы Y 52 = 175.

31
Потребление Y 52 = 175 складывается из среднего потребления, определяемого данным доходом 240, E(Y| Х 52 =240) = 161, а также из величины u 52 = = 14 превышения среднего потребления, определяемой для этого человека прочими факторами.
 = 161, а также из величины u 52 = 175-161 = 14 превышения среднего потребления, определяемой для этого человека прочими факторами.")
32
Аналогично, потребление 31-го человека Y 31 = 115 с доходом Х 31 =180 складывается из среднего потребления, определяемого данным доходом 180, E(Y| Х 31 =180) = 126, а также величины u 52 = = -14 уменьшения среднего потребления, определяемой для этого человека прочими факторами.
 = 126, а также величины u 52 = 161-175 = -14 уменьшения среднего потребления, определяемой д")
33
Таким образом, в общем виде модель регрессии записывается так: Y = E(Y|X) + u или для отдельного элемента выборки Y i = E(Y i |X i ) + u i. Если известна функциональная форма модели, например, линейная, то запись можно конкретизировать: Y = β 1 + β 2 *X+u, или для отдельного элемента выборки: Y i = β 1 + β 2 *X i + u i
 + u или для отдельного элемента выборки Y i = E(Y i |X i ) + u i. Если известна функциональная форма модели, например, линейная, то запись можно конкретизировать: Y = β 1 + β 2")
34
Слагаемое u в модели регрессии представляет все факторы, которые влияют на поведение переменной Y, но по каким-то причинам не включены в модель явно. В модели Y = E(Y|X) + u = β 1 + β 2 *X + u ясно видно, что, помимо дохода, на размер потребительских расходов влияют другие факторы, и что, кроме того, потребление отдельного человека не определяется полностью только его доходом.
 + u = β 1 + β 2 *X + u ясно видно, что, помимо дохода, на размер потребительских")
35
В модели Y = E(Y|X) + u = β 1 + β 2 *X + u β 1 и β 2 – это неизвестные, но фиксированные параметры, которые называются коэффициентами регрессии: β 1 - свободный член, β 2 - коэффициент наклона. В регрессионном анализе наш интерес состоит в том, чтобы оценить модель регрессии, т.е. значения параметров β 1 и β 2 по известным значениям X и Y.
 + u = β 1 + β 2 *X + u β 1 и β 2 – это неизвестные, но фиксированные параметры, которые называются коэффициентами регрессии: β 1 - свободный член, β 2 - коэффициент наклона. В регрессионном анализе наш интерес состоит в том, чтобы")
36
Что представляет собой случайный член модели регрессии? Между зависимой переменной Y и независимым фактором Х не существует строгой функциональной зависимости. Точки (X i, Y i ) не лежат строго на линии регрессии, а разбросаны вокруг нее. Этот разброс приписывается влиянию случайного фактора u. Почему же происходит отклонение точек- объектов от линии регрессии? Или: почему в модели регрессии необходим случайный член u?
 не лежат строго на линии регрессии, а разбросаны вокруг нее. Этот разбро")
37
Основных причин несколько. Невключение в модель объясняющих переменных. Мы не можем включить в модель в явной форме все переменные, которые влияют на Y. Почему? (а)Не всегда бывает совершенна теория, объясняющая поведение фактора Y.
Не всегда бывает совершенна теория, объясняющая поведение фактора Y.")
38
(б)Часто по нужной переменной нет статистических данных. Например, в модель потребительской функции, помимо дохода индивида, в принципе должна была бы быть включена переменная «состояние индивида». Но такая информация чаще всего недоступна, и поэтому данная переменная чаще всего в модель не включается.
Часто по нужной переменной нет статистических данных. Например, в модель потребительской функции, помимо дохода индивида, в принципе должна была бы быть включена переменная «состояние индивида». Но такая информация чаще всего недоступна, и поэтому")
39
(в) Экономические модели – это модели человеческого поведения, которому неотъемлемо присуща непредсказуемость, случайность, которую нельзя представить никакими количественно измеримыми факторами.
 Экономические модели – это модели человеческого поведения, которому неотъемлемо присуща непредсказуемость, случайность, которую нельзя представить никакими количественно измеримыми факторами.")
40
Все эти невключенные влияния представляются в модели регрессии фактором u.

41
Ошибки измерения переменных, входящих в модель. Причиной отклонения точек от линии регрессии может быть не только невключение каких-то влияний, но и неправильное или неточное измерение переменных модели. В этом случае наблюдаемые значения не будут соответствовать точному соотношению, и существующее расхождение будет представлено случайным членом.

42
Неправильная функциональная форма модели. Функциональная форма модели регрессии может быть определена неверно. В этом случае точки-наблюдения будут отклоняться от графика неверно определенной функции просто потому, что они лежат вокруг кривой другой формы. Это отклонение также будет приписано влиянию фактора u.

43
u u u

44
Терминология, связанная с моделью регрессии В модели регрессии Y i = E(Y|X i ) + u i, как мы установили, E(Y|X i ) = f(X i ). Поэтому модель можно переписать в виде: Y i = f(X i ) + u i.
 + u i, как мы установили, E(Y|X i ) = f(X i ). Поэтому модель можно переписать в виде: Y i = f(X i ) + u i.")
45
Y i = f(X i ) + u i В этой модели слагаемое f(X i ), т. е. та часть изменений Y, которая связана с изменениями фактора X, называется систематической, неслучайной компонентой фактора Y. Та часть фактора Y, которая представлена слагаемым u, называется его случайной компонентой. Исследователь, построивший для объяснения изменений фактора Y регрессионную модель, разумеется, предполагает, что систематические изменения фактора Y преобладают над его случайными изменениями.
 + u i В этой модели слагаемое f(X i ), т. е. та часть изменений Y, которая связана с изменениями фактора X, называется систематической, неслучайной компонентой фактора Y. Та часть фактора Y, которая представлена слагаемым u, называется")
46
Y = f(X) + u В модели регрессии фактор Y называется: зависимой переменной (или фактором), объясняемой переменной (или фактором). Так как значения Y определяются в модели, этот фактор является эндогенной переменной. u Фактор Y является случайной величиной, так как зависит от случайной величины u
 + u В модели регрессии фактор Y называется: зависимой переменной (или фактором), объясняемой переменной (или фактором). Так как значения Y определяются в модели, этот фактор является эндогенной переменной. u Фактор Y является случайной велич")
47
Y = f(X) + u Фактор X, называется: независимой переменной (или фактором), объясняющей переменной (или фактором), регрессором. Этот фактор является экзогенным, так как значения его определяются вне модели. Фактор X, часто рассматривается в модели как детерминированная величина.
 + u Фактор X, называется: независимой переменной (или фактором), объясняющей переменной (или фактором), регрессором. Этот фактор является экзогенным, так как значения его определяются вне модели. Фактор X, часто рассматривается в модели как")
48
Y = f(X) + u Фактор u называется: случайным членом модели регрессии, случайным фактором модели регрессии, фактором ошибки модели остаточным членом модели регрессии. Фактор u представляет все влияния на Y, отличные от влияния фактора X. Фактор u является случайной величиной
 + u Фактор u называется: случайным членом модели регрессии, случайным фактором модели регрессии, фактором ошибки модели остаточным членом модели регрессии. Фактор u представляет все влияния на Y, отличные от влияния фактора X. Фактор u являе")
49
Истинная (теоретическая, генеральная) и выборочная функции регрессии В примере мы рассматривали группу из 60 человек как генеральную совокупность. То есть нас интересовали только эти 60 человек, и мы не имели ввиду результаты исследования этой группы распространить на более многочисленную совокупность.
 и выборочная функции регрессии В примере мы рассматривали группу из 60 человек как генеральную совокупность. То есть нас интересовали только эти 60 человек, и мы не имели ввиду результаты исследования этой группы")
50
Такая ситуация не характерна для эконометрики. Как правило, исследователя интересуют выводы не о нескольких десятках или даже сотнях объектов, а о гораздо более многочисленных множествах. Например, зависимость потребления от дохода для совокупности всех семей какого-то региона; о зависимости выпуска от затрат капитала в данной отрасли промышленности; о зависимости размера ВВП от инвестиций в человеческий капитал вообще; и т.д.

51
Как правило, данных о всей генеральной совокупности, для которой хотят получить выводы, исследователи не имеют. Они делают или откуда-то получают выборку объектов из генеральной совокупности, для нее проводят исследования и полученные выводы (с определенными оговорками) распространяют на всю генеральную совокупность.

52
Поэтому и в регрессионном анализе различают генеральную, истинную, теоретическую модель регрессии, и ее выборочную оценку – выборочное уравнение регрессии.

53
Модель регрессии Y = E(Y|X) + u называется истинной (теоретической, генеральной) функцией регрессии, так как она описывает зависимость Y от Х для генеральной совокупности значений двумерной случайной величины (Х, Y).
 + u называется истинной (теоретической, генеральной) функцией регрессии, так как она описывает зависимость Y от Х для генеральной совокупности значений двумерной случайной величины (Х, Y).")
54
В практических ситуациях исследователи, как правило, имеют только выборку значений Y, соответствующих некоторым фиксированным значениям независимой переменной Х. Поэтому встает задача: оценить истинную, генеральную функцию регрессии по выборочным данным.

55
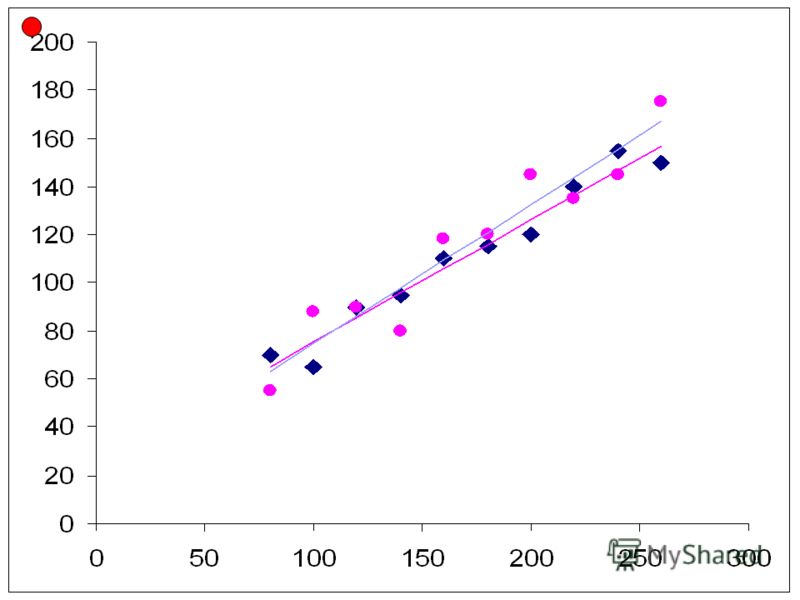
В нашем примере мы рассматривали совокупность из 60 индивидов как генеральную и соответствующая ей линия регрессии была истинной или генеральной линией регрессии. Теперь возьмем случайную выборку из нашей генеральной совокупности. Задача состоит в том, чтобы по этой выборке оценить истинную линию регрессии.

56
Дох од Пот реб лен ие

57
Построим по этой выборке линию регрессии, как можно лучше представляющую точки нашей выборки. Будет ли эта линия такой же как и истинная линия регрессии? Очевидно, нет. Так как если мы возьмем другую выборку, то получим другую, вообще говоря, линию регрессии.

58
Дох од Пот реб лен ие

60
Каждая из построенных по выборке линий регрессии называется выборочной линией регрессии. Выборочные линии регрессии только приближают, оценивают истинную линию регрессии: Y = E(Y|X) + u = β 1 + β 2 *X + u.
 + u = β 1 + β 2 *X + u.")
61
Уравнение выборочной линии регрессии в случае, когда она является прямой линией, записывается следующим образом: Ŷ = b 1 + b 2 *Х. Здесь: Ŷ - оценка E(Y|X) b 1 – оценка β 1, b 2 – оценка β 2..
 b 1 – оценка β 1, b 2 – оценка β 2..")
62
Теперь каждое попавшее в выборку значение Y i может быть записано как: Y i = b 1 + b 2 *X i + e i, где e i –представляет собой расстояние от точки выборки до выборочной прямой регрессии. e i = Y i - Ŷ i. По-другому, Y i = Ŷ i + e i или Y i = E(Y|X i ) + e i.

64
Величина e i называется остатком или отклонением значения Y i от выборочной линии регрессии. e i может служить оценкой u i.

Еще похожие презентации в нашем архиве:




 и выборочная функции регрессии.")




")














