Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Реализация параллельного алгоритма с использованием MPI

2
Содержание Основы MPI Настройка проекта Visual Studio 2008 Основные функции MPI Блокирующие функции обмена сообщениями. Типы данных Выполнение упражнения

3
Стандарт MPI

4
Что включено в стандарт MPI? – Парные обмены (point-to-point communications) – Коллективные операции (collective operations) – Операции над группами процессов (process groups) – Операции над коммуникационными контекстами (communication contexts) – Топологии процессов (process topologies) – Привязки к языкам C и Fortran 77 (language binding)
 – Коллективные операции (collective operations) – Операции над группами процессов (process groups) – Операции над коммуникационными контекстами (communication contexts) – То")
5
Стандарт MPI Что в стандарт не входит? – Способы взаимодействия процессов, отличные от использования средств библиотеки MPI (общая память и т.д.) – Операции, требующие использования особенностей программно-аппаратной среды – Описание способов отладки – Явная поддержка многопоточной обработки данных – Поддержка управления задачами – Функции ввода-вывода
 – Операции, требующие использования особенностей программно-аппаратной среды – Описание способов отладки")
6
Термины MPI

7
Локальная операция – процедура, не требующая взаимодействия с другими процессами. Нелокальная операция – процедура, выполнение которой может потребовать выполнения действий на других процессах. Такая процедура МОЖЕТ потребовать взаимодействия с другими процессами. Коллективная операция – процедура, которая должная быть выполнена всеми процессами группы.

8
Термины MPI Блокирующая операция – подразумевает выход из нее только после полного окончания операции, т.е. вызывающий процесс блокируется, пока операция не будет завершена Неблокирующая операция - подразумевает совмещение операций обмена с другими операциями.Как правило, ее выполнение происходит в параллельном потоке и не вызывающий процесс не блокируется.

9
Термины MPI Режимы выполнения С блокировкойБез блокировки Стандартная посылка MPI_SendMPI_Isend Синхронная посылка MPI_SsendMPI_Issend Буферизованная посылка MPI_BsendMPI_Ibsend Согласованная посылка MPI_RsendMPI_Irsend Прием информации MPI_RecvMPI_Irecv

10
Термины MPI Коммуникатор – контекст взаимодействия процессов с помощью функций MPI. За коммуникатором закрепляется некоторая группа процессов. Также возможно определение виртуальных топологий для упрощения структуризации обменов в рамках коммуникатора. Процессы в группе (и, как следствие, коммуникаторе) нумеруются от 0 до ( - 1) MPI_COMM_WORLD – предопределенная в библиотеке MPI константа, представляющая коммуникатор, включающий все процессы запущенной MPI-программы. MPI_COMM_SELF – предопределенная в библиотеке MPI константа, представляющая коммуникатор, включающий только текущий процесс.

11
Термины MPI С: – все функции начинаются с префикса MPI_ int MPI_Init(int *argc, char **argv); int MPI_Finalize(void); int MPI_Initialized(int *flag); – все функции имеют тип int и возвращают либо значение MPI_SUCCESS (в случае нормального завершения), либо код, соответствующий произошедшей ошибке
; int MPI_Finalize(void); int MPI_Initialized(int *flag); – все функции имеют тип int и возвращают либо значение MPI_SUCCESS (в случае нормального завершения)")
12
Термины MPI При описании функций и их параметров будем использовать следующие обозначения: – Данные, помеченные [IN], считаются входными для функции (процедуры), то есть, используются внутри нее, но не изменяются. – Данные, помеченные [OUT], считаются выходными и могут быть изменены. – Данные, помеченные [INOUT], используются внутри функции и могут быть изменены.
![Термины MPI При описании функций и их параметров будем использовать следующие обозначения: – Данные, помеченные [IN], считаются входными для функции (процедуры), то есть, используются внутри нее, но не изменяются. – Данные, помеченные [OUT], считаютс](http://images.myshared.ru/4/265472/slide_12.jpg "Термины MPI При описании функций и их параметров будем использовать следующие обозначения: – Данные, помеченные [IN], считаются входными для функции (процедуры), то есть, используются внутри нее, но не изменяются. – Данные, помеченные [OUT], считаютс")
13
Структура MPI-программы

14
Основные этапы жизненного цикла MPI- программы: Запуск Инициализация среды выполнения MPI Вычисления Завершение среды выполнения MPI Выгрузка

15
Структура MPI-программы MPI_Init(argc, argv) – [INOUT] argc – количество параметров командной строки запуска программы – [INOUT] argv – параметры командной строки, используемые для передачи параметров в программу C: int MPI_Init(int *argc, char ***argv) Функция MPI_Init создает группу процессов, в которой содержатся все процессы MPI-программы, и соответствующий этой группе коммуникатор MPI_COMM_WORLD. Может быть вызвана только один раз, попытка повторной инициализации завершится ошибкой.
![Структура MPI-программы MPI_Init(argc, argv) – [INOUT] argc – количество параметров командной строки запуска программы – [INOUT] argv – параметры командной строки, используемые для передачи параметров в программу C: int MPI_Init(int *argc, char ***ar](http://images.myshared.ru/4/265472/slide_15.jpg "Структура MPI-программы MPI_Init(argc, argv) – [INOUT] argc – количество параметров командной строки запуска программы – [INOUT] argv – параметры командной строки, используемые для передачи параметров в программу C: int MPI_Init(int *argc, char ***ar")
16
Структура MPI-программы MPI_Finalize() – Без параметров C: int MPI_Finalize(void) Функция MPI_Finalize освобождает ресурсы, занятые средой выполнения MPI.
 – Без параметров C: int MPI_Finalize(void) Функция MPI_Finalize освобождает ресурсы, занятые средой выполнения MPI.")
17
Структура MPI-программы #include int main(int argc, char* argv[]) { int ierr; ierr = MPI_Init(&argc, &argv); // Инициализация среды MPI if (ierr != MPI_SUCCESS) return ierr; printf("Hello world\n"); // Полезная работа MPI_Finalize(); // Завершение среды MPI }
![Структура MPI-программы #include int main(int argc, char* argv[]) { int ierr; ierr = MPI_Init(&argc, &argv); // Инициализация среды MPI if (ierr != MPI_SUCCESS) return ierr; printf(](http://images.myshared.ru/4/265472/slide_17.jpg "Структура MPI-программы #include int main(int argc, char* argv[]) { int ierr; ierr = MPI_Init(&argc, &argv); // Инициализация среды MPI if (ierr != MPI_SUCCESS) return ierr; printf(")
18
Основные функции MPI

19
MPI_Initialized(flag) – [OUT] flag – возвращает 0, если среда выполнения MPI не была еще инициализирована C: int MPI_Initialized(int *flag) Функция MPI_Initialized позволяет выяснить, была ли среда выполнения MPI уже инициализирована.
![MPI_Initialized(flag) – [OUT] flag – возвращает 0, если среда выполнения MPI не была еще инициализирована C: int MPI_Initialized(int *flag) Функция MPI_Initialized позволяет выяснить, была ли среда выполнения MPI уже инициализирована.](http://images.myshared.ru/4/265472/slide_19.jpg "MPI_Initialized(flag) – [OUT] flag – возвращает 0, если среда выполнения MPI не была еще инициализирована C: int MPI_Initialized(int *flag) Функция MPI_Initialized позволяет выяснить, была ли среда выполнения MPI уже инициализирована.")
20
Основные функции MPI MPI_Comm_size(comm, size) – [IN] comm – коммуникатор, размер которого хотим определить. – [OUT] size – количество процессов в коммуникаторе comm C:int MPI_Comm_size(MPI_Comm comm, int *size) Функция MPI_Comm_size возвращает в переменную size количество процессов в коммуникаторе comm.
![Основные функции MPI MPI_Comm_size(comm, size) – [IN] comm – коммуникатор, размер которого хотим определить. – [OUT] size – количество процессов в коммуникаторе comm C:int MPI_Comm_size(MPI_Comm comm, int *size) Функция MPI_Comm_size возвращает в пер](http://images.myshared.ru/4/265472/slide_20.jpg "Основные функции MPI MPI_Comm_size(comm, size) – [IN] comm – коммуникатор, размер которого хотим определить. – [OUT] size – количество процессов в коммуникаторе comm C:int MPI_Comm_size(MPI_Comm comm, int *size) Функция MPI_Comm_size возвращает в пер")
21
Основные функции MPI MPI_Comm_rank(comm, rank) – [IN] comm – коммуникатор, относительно которого мы хотим определить ранг текущего процесса. – [OUT] rank – ранг текущего процесса в коммуникаторе comm C:int MPI_Comm_rank(MPI_Comm comm, int *rank) Функция MPI_Comm_rank возвращает в переменную rank ранг текущего процесса в коммуникаторе comm. В различных коммуникаторах ранги одного и того же процесса могут быть различны, но обязательно уникальны в рамках каждого коммуникатора.
![Основные функции MPI MPI_Comm_rank(comm, rank) – [IN] comm – коммуникатор, относительно которого мы хотим определить ранг текущего процесса. – [OUT] rank – ранг текущего процесса в коммуникаторе comm C:int MPI_Comm_rank(MPI_Comm comm, int *rank) Функ](http://images.myshared.ru/4/265472/slide_21.jpg "Основные функции MPI MPI_Comm_rank(comm, rank) – [IN] comm – коммуникатор, относительно которого мы хотим определить ранг текущего процесса. – [OUT] rank – ранг текущего процесса в коммуникаторе comm C:int MPI_Comm_rank(MPI_Comm comm, int *rank) Функ")
22
Блокирующие функции обмена сообщениями

23
Сообщения – данные, передаваемые между процессами, вместе с дополнительной информацией – их описанием Сообщения помечаются тегом – произвольно задаваемым программистом целым числом Тег и дополнительная информация передаются в оболочке сообщения Каждой операции отправки сообщения должна соответствовать операция приема.

24
Блокирующие функции обмена сообщениями Оболочка сообщения содержит: – Ранг процесса-источника сообщения – Ранг процесса-получателя сообщения – Количество передаваемых в сообщении данных – Тег сообщения – Коммуникатор, в рамках которого происходит отправка

25
Блокирующие функции обмена сообщениями MPI_Send(buf, count, datatype, dest, tag, comm) – [IN] buf – указатель на буфер отправляемых данных – [IN] count – количество данных типа datatype в буфере buf – [IN] datatype – тип отправляемых данных – [IN] dest – ранг процесса, которому отсылаем данные – [IN] tag – тэг отсылаемых данных – [IN] comm – коммуникатор С: MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) Функция MPI_Send отсылает сообщение из буфера buf процессу с рангом dest.
![Блокирующие функции обмена сообщениями MPI_Send(buf, count, datatype, dest, tag, comm) – [IN] buf – указатель на буфер отправляемых данных – [IN] count – количество данных типа datatype в буфере buf – [IN] datatype – тип отправляемых данных – [IN] de](http://images.myshared.ru/4/265472/slide_25.jpg "Блокирующие функции обмена сообщениями MPI_Send(buf, count, datatype, dest, tag, comm) – [IN] buf – указатель на буфер отправляемых данных – [IN] count – количество данных типа datatype в буфере buf – [IN] datatype – тип отправляемых данных – [IN] de")
26
Блокирующие функции обмена сообщениями MPI_Recv(buf, count, datatype, source, tag, comm, status) – [OUT] buf – указатель на буфер, в который будут сохранены полученные данные – [IN] count – количество принимаемых данных типа datatype – [IN] datatype – тип принимаемых данных – [IN] source – ранг процесса, от которого принимаем данные, или MPI_ANY_SOURCE – [IN] tag – тэг принимаемых данных или MPI_ANY_TAG – [IN] comm – коммуникатор – [OUT] status – статус полученного сообщения С:MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) Функция MPI_Recv принимает сообщение от процесса с рангом source. В случае, если ранг не известен или не важен, можно указать значение MPI_ANY_SOURCE. Если неизвестен или неважен тэг сообщения, можно указать значение MPI_ANY_TAG.
![Блокирующие функции обмена сообщениями MPI_Recv(buf, count, datatype, source, tag, comm, status) – [OUT] buf – указатель на буфер, в который будут сохранены полученные данные – [IN] count – количество принимаемых данных типа datatype – [IN] datatype](http://images.myshared.ru/4/265472/slide_26.jpg "Блокирующие функции обмена сообщениями MPI_Recv(buf, count, datatype, source, tag, comm, status) – [OUT] buf – указатель на буфер, в который будут сохранены полученные данные – [IN] count – количество принимаемых данных типа datatype – [IN] datatype")
27
Типы данных MPIC MPI_CHARsigned char MPI_SHORTsigned short int MPI_INTsigned int MPI_LONGsigned long int MPI_UNSIGNED_CHARunsigned char MPI_UNSIGNED_SHORTunsigned short int MPI_UNSIGNEDunsigned int MPI_UNSIGNED_LONGunsigned long int MPI_FLOATfloat MPI_DOUBLEdouble MPI_LONG_DOUBLElong double

28
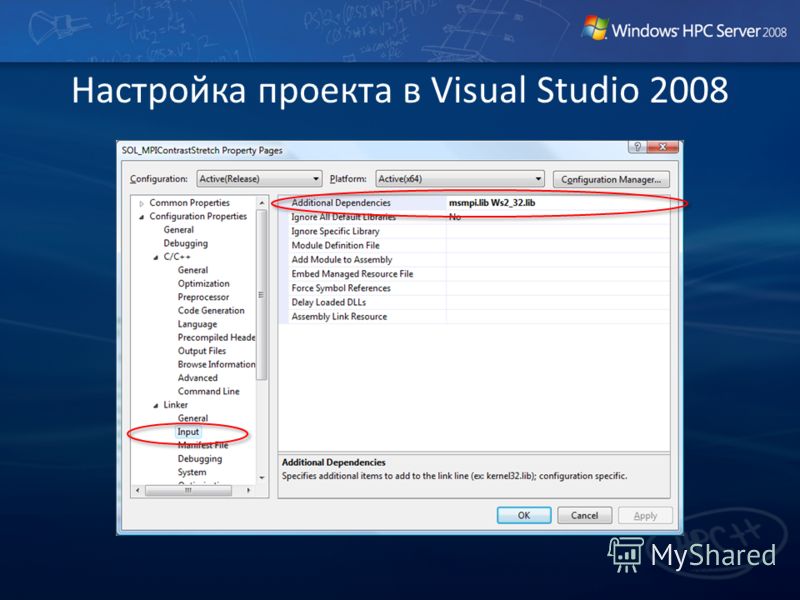
Настройка проекта в Visual Studio 2008

29
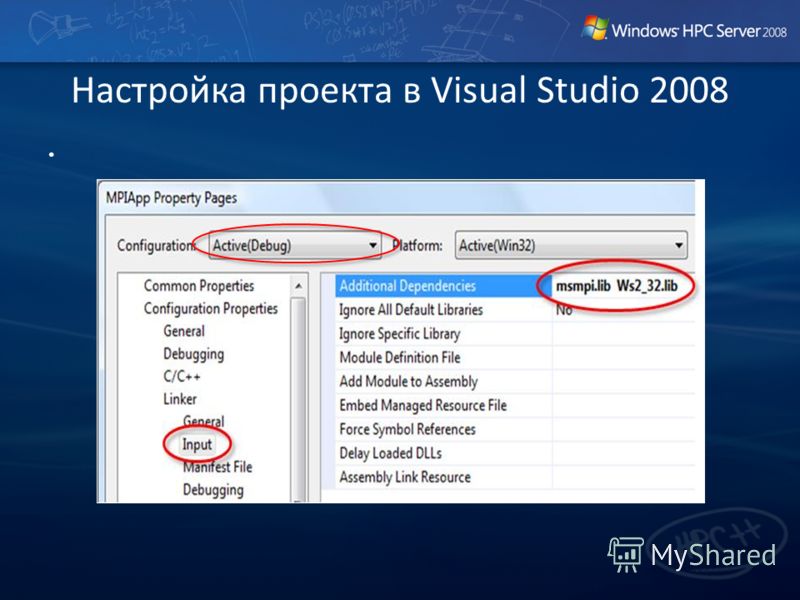
1) Project -> Project Properties-> C\C++-> General –> Additional Include Directories : затем нажмите на икону и выберите папку: C:\Program Files\Microsoft HPC Pack 2008 SDK\Include 2)Project -> Project Properties-> Linker -> General -> Additional Library Directories : C:\Program Files\Microsoft HPC Pack 2008 SDK\Lib\i386 3)Project -> Project Properties-> Linker -> Input: msmpi.lib Ws2_32.lib Для платформы x64, и введите папки: C:\Program Files\Microsoft HPC Pack 2008 SDK\Include C:\Program Files\Microsoft HPC Pack 2008 SDK\Lib\amd64
 Project -> Project Properties-> C\C++-> General –> Additional Include Directories : затем нажмите на икону и выберите папку: C:\Program Files\Microsoft HPC Pack 2008 SDK\Include 2)Project -> Project Properties-> Linker -> General -> Additional Lib")
30
Настройка проекта в Visual Studio 2008

34
Выполнение упражнения

35
Master Worker Master Send / Recv Worker

36
Выполнение упражения 1.Запустите проект в папке Exercises\03 MPI\MPIContrastStretch. Настройте проект для создания MPI приложений как сказано выше. Выберите архитектуру процессора (Win32 или x64). Добавьте в файл app.h строку #include. В самом начале главной функции добавьте вызовы функций MPI_Init, MPI_Comm_size, MPI_Comm_rank, и gethostname. Для более простого способа отладки объявите связанные с ними переменные как глобальные. Например : int myRank; int numProcs; char host[256]; int main(int argc, char *argv[]) { MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numProcs); MPI_Comm_rank(MPI_COMM_WORLD, &myRank); gethostname(host, sizeof(host)/sizeof(host[0])); … MPI_Finalize(); return 0; }
. Добавьте в файл app.h строку #include. В самом начале")
37
Выполнение упражнения 2. Cоздайте тип данных MPI_PIXEL_T,добавив вызов функции CreateMPIPixelDatatype после вызова MPI_Init. Новый тип MPI данных назовем MPI_PIXEL_T: … gethostname(host,sizeof(host)/sizeof(host[0])); MPI_Datatype MPI_PIXEL_T = CreateMPIPixelDatatype(); Для его уничтожения необходимо перед вызовом функции MPI_Finalize все процессы должны вызвать функцию MPI_Type_free: … MPI_Type_free(&MPI_PIXEL_T); MPI_Finalize(); return 0;
![Выполнение упражнения 2. Cоздайте тип данных MPI_PIXEL_T,добавив вызов функции CreateMPIPixelDatatype после вызова MPI_Init. Новый тип MPI данных назовем MPI_PIXEL_T: … gethostname(host,sizeof(host)/sizeof(host[0])); MPI_Datatype MPI_PIXEL_T = Create](http://images.myshared.ru/4/265472/slide_37.jpg "Выполнение упражнения 2. Cоздайте тип данных MPI_PIXEL_T,добавив вызов функции CreateMPIPixelDatatype после вызова MPI_Init. Новый тип MPI данных назовем MPI_PIXEL_T: … gethostname(host,sizeof(host)/sizeof(host[0])); MPI_Datatype MPI_PIXEL_T = Create")
38
Выполнение упражнения 3.Найдите в файле место, где происходит вызов ContrastStretch и закомментируйте его. добавьте ниже: PIXEL_T **chunk = NULL; int myrows = 0; int mycols = 0; // разделение матрицы на части chunk = DistributeImage(image, rows, cols, myrows, mycols, MPI_PIXEL_T); assert(chunk != NULL); assert(rows > 0); assert(cols > 0); assert(myrows > 0); assert(mycols > 0); // chunk = ContrastStretch(chunk, myrows, mycols, steps, stepby, MPI_PIXEL_T); // собирание матрицы image = CollectImage(image, rows, cols, chunk, myrows, mycols, MPI_PIXEL_T);

39
Выполнение упражнения 5.Добавьте в проект файлы Distribute.cpp и Collect.cpp. Добавьте в файл Distribute.cpp функцию DistributeImage для распределения частей матрицы между вычислительными узлами : #include "app.h #include "mpi.h" PIXEL_T **DistributeImage(PIXEL_T **image, int &rows, int &cols, int &myrows, int &mycols, MPI_Datatype MPI_PIXEL_T) { return NULL; } добавьте в файл Collect.cpp функцию CollectImage для сбора частей матрицы в единую матрицу. : #include "app.h #include "mpi.h" PIXEL_T **CollectImage(PIXEL_T **image, int rows, int cols, PIXEL_T **chunk, int myrows, int mycols, MPI_Datatype MPI_PIXEL_T) { return NULL; }

40
Выполнение упражнения Добавьте в файл app.h определения функций: PIXEL_T **DistributeImage(PIXEL_T **image, int &rows, int &cols, int &myrows, int &mycols, MPI_Datatype MPI_PIXEL_T); PIXEL_T **CollectImage(PIXEL_T **image, int rows, int cols, PIXEL_T **chunk, int myrows, int mycols, MPI_Datatype MPI_PIXEL_T); Также в файле app.h необходимо объявить внешними (external) переменные: extern int myRank; extern int numProcs; extern char host[256];
; PIXEL_T **CollectImage(PIXEL_T **image, int rows, int cols, PIXEL_T")
41
Выполнение упражения 6. В файле Main.cpp добавим код, для того чтобы ввод и вывод файлов осуществлялся только главным узлом. Находим строку где выводится "** Reading bitmap from '" и добавляем выше и ниже: double time = 0.0; if (myRank == 0) { cout
 { cout")
42
Выполнение упражнения 7. Изменим функцию DistributeImage: PIXEL_T **chunk = NULL; int tag = 0; int params[2] = {0, 0}; cout
![Выполнение упражнения 7. Изменим функцию DistributeImage: PIXEL_T **chunk = NULL; int tag = 0; int params[2] = {0, 0}; cout](http://images.myshared.ru/4/265472/slide_42.jpg "Выполнение упражнения 7. Изменим функцию DistributeImage: PIXEL_T **chunk = NULL; int tag = 0; int params[2] = {0, 0}; cout")
43
Выполнение упражнения else //выполняется вычислительными узлами { MPI_Status status; MPI_Recv(params, sizeof(params)/sizeof(params[0]), MPI_INT, 0 /*master*/, tag, MPI_COMM_WORLD, &status); rows = params[0]; cols = params[1]; myrows = rows / numProcs; // размер части матрицы mycols = cols; chunk = New2dMatrix (myrows+2, mycols); // почему на две строки // больше? Смотри функцию изменения контрастности MPI_Recv(chunk[1], myrows*mycols, MPI_PIXEL_T, 0 /*master*/, tag, MPI_COMM_WORLD, &status); } return chunk;
![Выполнение упражнения else //выполняется вычислительными узлами { MPI_Status status; MPI_Recv(params, sizeof(params)/sizeof(params[0]), MPI_INT, 0 /*master*/, tag, MPI_COMM_WORLD, &status); rows = params[0]; cols = params[1]; myrows = rows / numProcs](http://images.myshared.ru/4/265472/slide_43.jpg "Выполнение упражнения else //выполняется вычислительными узлами { MPI_Status status; MPI_Recv(params, sizeof(params)/sizeof(params[0]), MPI_INT, 0 /*master*/, tag, MPI_COMM_WORLD, &status); rows = params[0]; cols = params[1]; myrows = rows / numProcs")
44
Выполнение упражнения 8. Изменим функцию CollectImage : assert(chunk != NULL); assert(rows > 0); assert(cols > 0); assert(myrows > 0); assert(mycols > 0); int tag = 0; cout
; assert(rows > 0); assert(cols > 0); assert(myrows > 0); assert(mycols > 0); int tag = 0; cout")
45
else // главный вычислительный узел { assert(image != NULL); MPI_Status status; memcpy_s(image[0], myrows*mycols*sizeof(PIXEL_T), chunk[1], myrows*mycols*sizeof(PIXEL_T)); int rowsPerProc = rows / numProcs; int leftOverRows = rows % numProcs; // получение данных от узлов for (int src=1; src < numProcs; src++) MPI_Recv(image[leftOverRows + src*rowsPerProc], rowsPerProc*cols, MPI_PIXEL_T, src, tag, MPI_COMM_WORLD, &status); } Delete2dMatrix (chunk); return image;
![else // главный вычислительный узел { assert(image != NULL); MPI_Status status; memcpy_s(image[0], myrows*mycols*sizeof(PIXEL_T), chunk[1], myrows*mycols*sizeof(PIXEL_T)); int rowsPerProc = rows / numProcs; int leftOverRows = rows % numProcs; // полу](http://images.myshared.ru/4/265472/slide_45.jpg "else // главный вычислительный узел { assert(image != NULL); MPI_Status status; memcpy_s(image[0], myrows*mycols*sizeof(PIXEL_T), chunk[1], myrows*mycols*sizeof(PIXEL_T)); int rowsPerProc = rows / numProcs; int leftOverRows = rows % numProcs; // полу")
46
Выполнение упражнения Скомпилируйте приложение, скопируйте изображение в папку с EXE файлом и запустите приложение. С помощью программы WinDiff сравните полученные изображения.

47
9. В файле Main. cpp уберите комментарии для строки chunk = ContrastStretch(chunk, myrows, mycols, steps, stepby, MPI_PIXEL_T); Измените определение функций ContrastStretch в файл app.h : PIXEL_T **ContrastStretch(PIXEL_T **image, int rows, int cols, int steps, int stepby, MPI_Datatype MPI_PIXEL_T); Откройте файл ContrastStretch.cpp и измените код в соответствии с PIXEL_T **ContrastStretch(PIXEL_T **image, int rows, int cols, int steps, int stepby, MPI_Datatype MPI_PIXEL_T) { cout
; Измените определение функций ContrastStretch в файл app.h : PIXEL_T **ContrastStretch(PIXEL_T **image, int rows, int cols,")
48
int firstRow = 1; // это справедливо для всех узлов кроме главного int lastRow = rows; if (myRank == 0) // главный узел начинает вычисления со второй строки firstRow = 2; if (myRank == numProcs-1) // последний узел не вычисляет значения для //последней строки lastRow = rows-1; bool converged = false;
 // главный узел начинает вычисления со второй строки firstRow = 2; if (myRank == numProcs-1) // последний узел не вычисляет значения для //последн")
49
Выполнение упражнения 10. Для добавления возможности обмена строками необходимо добавить код в самом начале цикла while в файле ContrastStretch.cpp: cout

50
Выполнение упражнения 11. Изменение цикла for для вычисления переменной diffs : if (myRank > 0) // вычислительные узлы: { MPI_Send(&diffs, 1, MPI_LONG_LONG, 0 /*master*/, 0 /*tag*/, MPI_COMM_WORLD); MPI_Recv(&diffs, 1, MPI_LONG_LONG, 0 /*master*/, 0 /*tag*/, MPI_COMM_WORLD, &status); }
 // вычислительные узлы: { MPI_Send(&diffs, 1, MPI_LONG_LONG, 0 /*master*/, 0 /*tag*/, MPI_COMM_WORLD); MPI_Recv(&diffs, 1, MPI_LONG_LONG, 0 /*master*/, 0")
51
Выполнение упражнения else // главный узел: { long long temp; for (int src=1; src < numProcs; src++) // получение значений от все вычислительных //узлов: { MPI_Recv(&temp, 1, MPI_LONG_LONG, MPI_ANY_SOURCE, 0 /*tag*/, MPI_COMM_WORLD, &status); diffs += temp; // суммирование } for (int dest=1; dest < numProcs; dest++) // отправка вычислительным узлам //нового значения MPI_Send(&diffs, 1, MPI_LONG_LONG, dest, 0 /*tag*/, MPI_COMM_WORLD); } cout
 // получение значений от все вычислительных //узлов: { MPI_Recv(&temp, 1, MPI_LONG_LONG, MPI_ANY_SOURCE, 0 /*tag*/, MPI_COMM_WORLD, &status); diffs +")
52
Выполнение упражнения 12. Обновление циклов копирования матрицы: for (int row = firstRow; row

53
14.Скомпилируйте проект и запустите локальной машине mpiexec –n 4 MPIApp.exe 14. Запишите полученные значения. Выполнение упражнения

54
1.Скомпилируйте приложение для выполнения на процессоре x64 и скопируйте его вместе с изображением в своем папку на кластере 2.Для выполнения MPI-приложения на кластере запустите Job Manager, выберите адрес кластера: HN.PRACTICUM ( , :,CLUSTER) 3.Добавьте новое задание, указав в командной строке mpiexec.exe MPIContrastStretch.exe Sunset.bmp out.bmp Добавьте в качестве настроек: – \\hn\apps\ – \\hn\apps\ \out.txt – \\hn\apps\ \err.txt

55
Выполнение упражнения

56
Заключение

57
© 2008 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries. The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.

Еще похожие презентации в нашем архиве:




 Антонов Александр Сергеевич, к.ф.-м.н., н.с. лаборатории Параллельных.")









 Директор по производству «Интеллектуальные системы»")






