Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

4
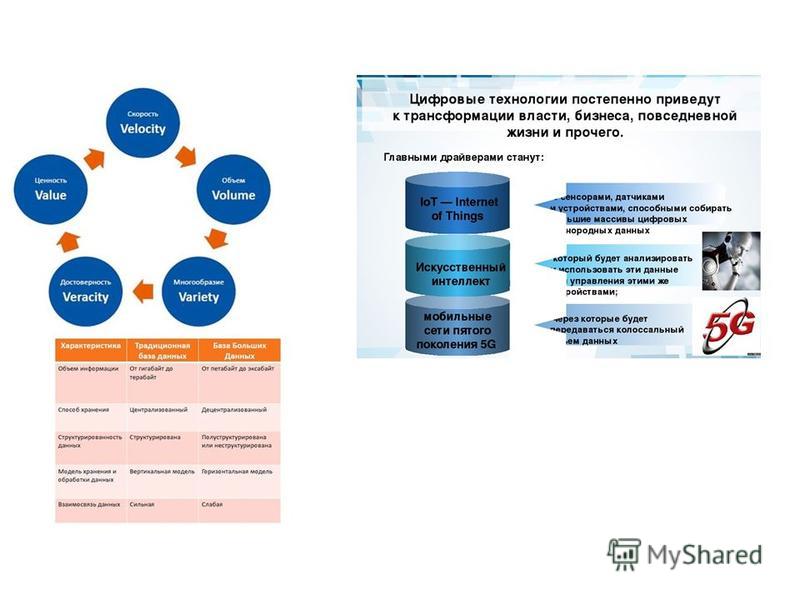
Big Data пришли в Россию

5
Объем данных в компаниях

6
ПроблемаBig Data

7
Кто использует Big Data

9
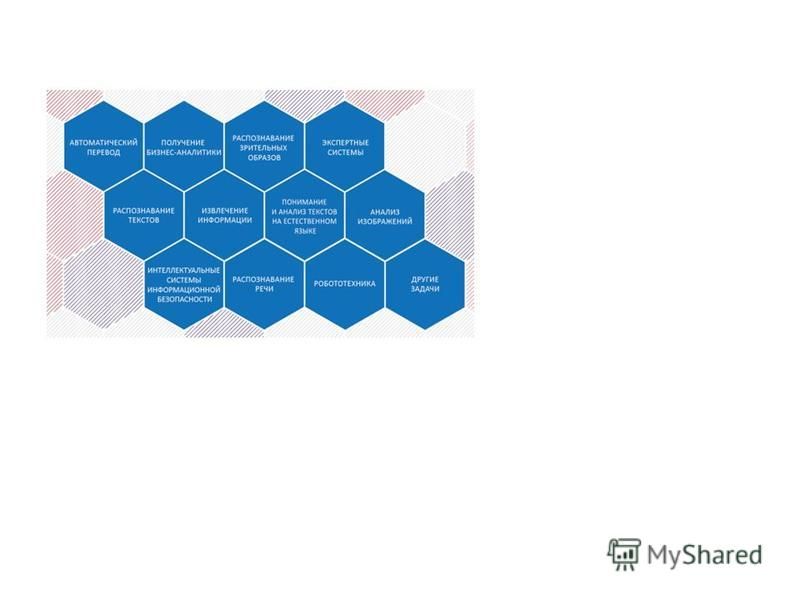
Роль в жизни человека Big Data

12
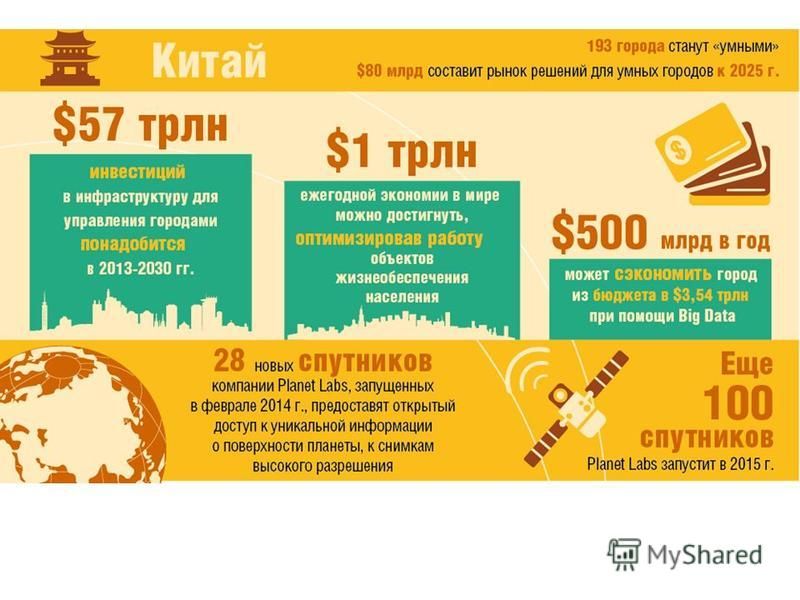
Big Data в отраслях

28
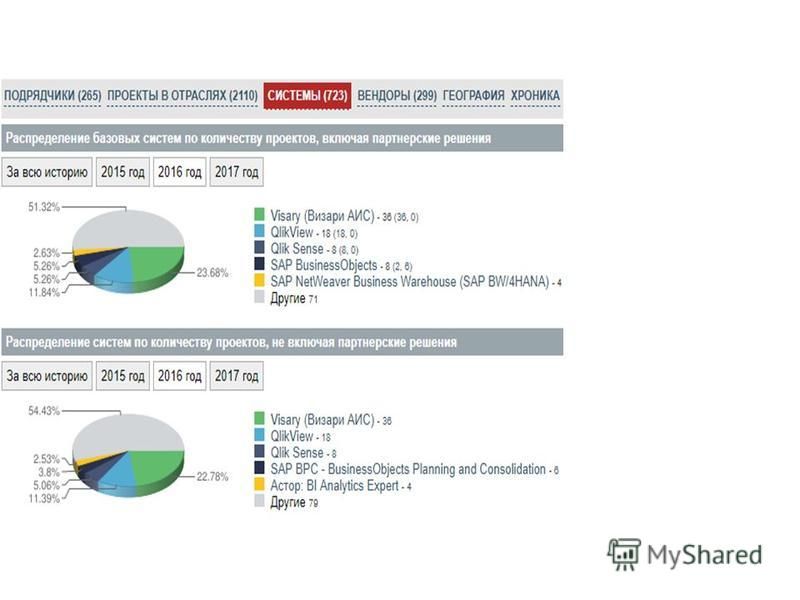
Статистка использования систем бизнес-аналитики по количеству проектов внедрений в РФ

30
Бесплатные базовые версии есть QlikView / Sense, Deductor (Loginom), Prognoz Platform. У Visary (Визари АИС, российская OLAP) бесплатной нет. Платформы QlikView / Sense входят в ТОП-3 мировых систем BI.
, Prognoz Platform. У Visary (Визари АИС, российская OLAP) бесплатной нет. Платформы QlikView / Sense входят в ТОП-3 мировых систем BI. http://www.tadviser.ru/index.php/BI")
31
Возрастающая сложность: организации инвестируют в среднем в 7 различных инструментов ML Различия между инженерами по разработке данных и научными исследованиями также распространяются на инструменты, которые они используют, и их много. Подавляющее большинство (87%) инвестируют в различные виды данных и технологии, связанные с ИИ, чтобы осуществить процесс подготовки данных, интеллектуальнвую разведку данных и моделирование, в том числе: 85% Инструменты обработки данных, такие как Apache Spark, Hadoop / MapReduce и Google BigQuery 65% Инструменты потоковой передачи данных, такие как Flume, Kafka и Onyx 80% Средства машинного обучения, такие как Azure ML, Amazon ML и Spark MLlib 65% Инструменты глубокого обучения, такие как Google TensorFlow, Microsoft CNTK и Deeplearning4j (DL4J) В целом результаты опроса показывают, что организации используют в среднем семь различных средств машинного обучения и фреймворков глубокого обучения, создавая очень сложную среду, которая может замедлить эффективность организации. Чтобы получить ценность от ИИ, предприятия зависят от их существующих данных и способности итеративно выполнять ML на массивных наборах данных. Сегодняшние инженеры по данным и ученые-аналитики используют многочисленные, несвязанные инструменты для этого, включая зоопарк ML-фреймворков.

33
Spark также объединяет данные и ИИ с последовательным набором API для простой загрузки данных, обработки пакетных / потоковых данных, SQL Analytics, Stream Analytics и Machine Learning. Apache Spark был первым механизмом Unified Analytics для унификации данных (инженерии данных) с AI (искусственный интеллект). Apache Spark стал де-факто обработкой данных и движком AI на предприятиях сегодня благодаря своей быстроте, простоте использования и сложной аналитике. Spark упрощает подготовку данных для ИИ, объединяя данные в огромных масштабах в разных источниках - облачном хранилище, файловых системах, хранилищах значений ключей и шинах сообщений.

36
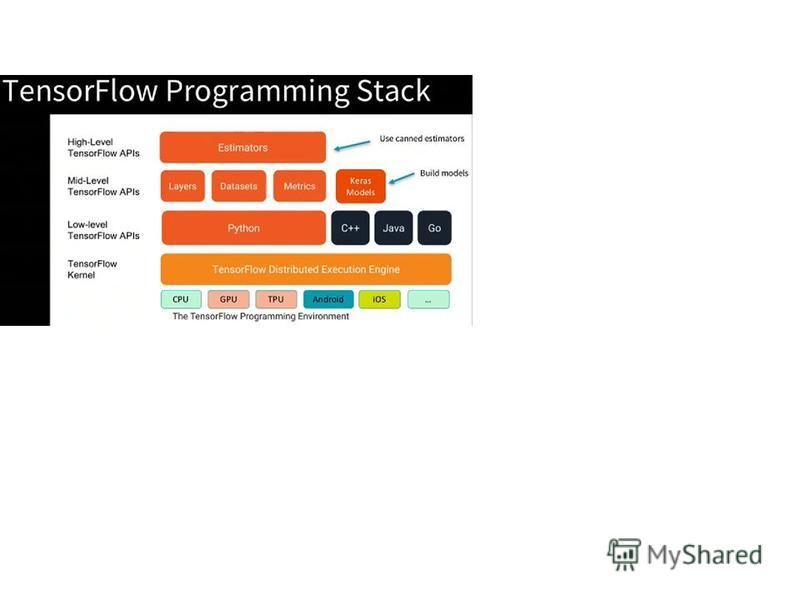
Apache Spark, мощный механизм обработки с открытым исходным кодом, построенный на скорости, простоте использования и сложной аналитике, стал стандартом де-факто для построения больших приложений данных Apache Spark (от англ. spark искра, вспышка) фреймворк с открытым исходным кодом для реализации распределённой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop. В отличие от классического обработчика из ядра Hadoop, реализующего двухуровневую концепцию MapReduce с дисковым хранилищем, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти, благодаря чему позволяет получать значительный выигрыш в скорости работы для некоторых классов задач [5], в частности, возможность многократного доступа к загруженным в память пользовательским данным делает библиотеку привлекательной для алгоритмов машинного обучения [6].англ.фреймворкоткрытым исходным кодомнеструктурированныхHadoopMapReduce [5]машинного обучения [6] Проект предоставляет программные интерфейсы для языков Java, Scala, Python, R. Изначально написан на Scala, впоследствии добавлена существенная часть кода на Java для предоставления возможности написания программ непосредственно на Java. Состоит из ядра и нескольких расширений, таких как Spark SQL (позволяет выполнять SQL-запросы над данными), Spark Streaming (надстройка для обработки потоковых данных), Spark MLlib (набор библиотек машинного обучения), GraphX (предназначено для распределённой обработки графов). Может работать как в среде кластера Hadoop под управлением YARN, так и без компонентов ядра Hadoop, поддерживает несколько распределённых систем хранения HDFS, OpenStack Swift, NoSQL-СУБД Cassandra, Amazon S3. программные интерфейсыJavaScalaPythonRScalaSQLYARNHDFSOpenStack SwiftNoSQLCassandraAmazon S3
 фре")
37
Apache Spark - это единый механизм анализа для обработки больших данных.

Еще похожие презентации в нашем архиве:
















.")






 для параллельной обработки больших объемов данных (терабайты)")









 ОС Структура связей между отдельными модулями ОС Принципы взаимодействия модулей.")

