Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Разработка алгоритма обнаружения неправомерного использования изображений Выполнила: Явтушенко Евгения Дмитриевна ФФ- 505 Научный руководитель: Анзулевич Антон Петрович Научный консультант: Ручай Алексей Николаевич Выполнила: Явтушенко Евгения Дмитриевна ФФ- 505 Научный руководитель: Анзулевич Антон Петрович Научный консультант: Ручай Алексей Николаевич

2
Целью данной работы является изучение существующих методов поиска данных по шаблонам и разработка алгоритма обнаружения неправомерного использования изображений. Актуальность работы: Возрастает необходимость защиты личной информации граждан (данный аспект регулируется ст ГК РФ «Охрана изображения гражданина»). Кража и повторная публикация чужих изображений без согласия автора является не только нарушением авторских прав, но и кражей личной собственности. Существуют определённые перечни запрещённой для общего использования информации. Правоохранительные органы следят за распространением изображений, содержащих сведения экстремистского характера для предотвращения террористических актов. Для того чтобы создать защиту от утечки любого вида информации необходимо производить контроль над данными.

3
Задачи Рассмотреть существующие подходы к поиску изображений; Выбрать несколько технологий для реализации; Подготовить тестовую базу изображений; Провести анализ действия алгоритмов в зависимости от длины хеша, выбранной технологии, объёма базы и различных типов модификаций изображений; Разработать оптимальный алгоритм обнаружения неправомерного использования изображений.

4
Анализ существующих подходов Алгоритмы на основе нейронных сетей; Template Matching; Цветовые гистограммы; Алгоритмы перцептивного хеширования.

5
Перцептивные хеши Хеширование (англ. hashing) преобразование массива входных данных произвольной длины в (выходную) битовую строку фиксированной длины, выполняемое определённым алгоритмом. В отличие от классических хеш-функций, алгоритмы построения перцептивных хешей описывают класс функций для генерации сравнимых хешей. Они используются для построения индивидуального «отпечатка». В дальнейшем «отпечатки» можно сравнивать друг с другом, определять степень схожести исходных изображений.
 преобразование массива входных данных произвольной длины в (выходную) битовую строку фиксированной длины, выполняемое определённым алгоритмом. В отличие от классических хеш-функций, алгоритмы построения п")
6
Алгоритмы построения перцептивных хешей Перцептивный хеш по среднему значению; Перцептивный хеш на основе предыдущего значения цвета ; Хеш на основе дискретного косинусного преобразования.

7
Построение полного хеша Данный алгоритм состоит из следующих этапов: Применение фильтра размытия. Перевод изображения в оттенки серого. Изменение масштаба изображения. При уменьшении изображения до квадрата 32×32 пикселей происходит фильтрация высоких частот и выделяется структура изображения. Вычисление среднего значения цвета для всех пикселей. Построение цепочки битов. Для каждого пикселя производится замена значения цвета на 1 или 0 в зависимости от того, больше он или меньше среднего.

8
Построение короткого хеша Была произведена сортировка хеша - определены самые информативные биты по следующему алгоритму: 1. Вычислить информативность каждого бита хеша по формуле : 2. Расположить полученные значения информативности в порядке возрастания. 3. Отсортировать хеш в зависимости от значений информативности. После сортировки формируется хеш, состоящий из определённого количества первых бит. В работе были получены короткие хеши длиной 50 бит и 64 бита.

9
Каскадный поиск по отсортированному хешу 1. Вычислить полный 1024-битный хеш. 2. Отсортировать биты хеша по информативности. 3. Отсортированный полный хеш разбить на блоки (8, 8, 16, 32 и 960 бит; 8, 8, 16, 32, 64, 128, 768 бит). При поиске фильтр на первых 8 битах отбрасывает определённое количество хешей. Результаты передаются для сравнения следующих 8 бит и так далее.
. При поиске фильтр на")
10
Анализ работы алгоритмов На первом этапе исследования использовалось 10 видов модификаций изображений: Смена цветовой модели на Xyz Смена цветовой модели на Yuv Поворот на 1,1 Поворот на 1,2 Поворот на 1,3 Размытие 1% Размытие 3% Масштаб 1/2 Масштаб 1/3 Масштаб ¼

11
Процент нахождения модификаций изображений для поиска по 1024-битному хешу Параметр Значение порога Смена цветовой модели на Xyz94,3%100% Смена цветовой модели на Yuv62,8%76%76%88%88% Поворот на 1,182,1%86%100% Поворот на 1,280,9%96,5%100% Поворот на 1,384%84%96,7%99,9% Размытие 1%100% Размытие 3%80,5%99%100% Масштаб 1/296%98,3%100% Масштаб 1/3100% Масштаб 1/4100%

12
В ходе работы была сформирована база из различных изображений и новый список типов модификаций : Сжатие (с коэффициентами 40, 70,90) Фильтрующие преобразования (фильтр Гаусса, усиление цвета, медианный фильтр) Геометрические искажения (масштаб, кадрирование, случайное удаление части изображения, сдвиг изображения) Смешанные преобразования (поворот+изменение масштаба+ кадрирование) Добавление шума (Гауссов шум, «соль») Добавление яркости
 Фильтрующие преобразования (фильтр Гаусса, усиление цвета, медианный фильтр) Геометрические искажения (масштаб,")
14
Оценка скорости работы алгоритма на основе полного хеша Количество входных изображений Размер базы изображений Время обработки всех входных изображений, с Среднее время работы алгоритма, с , , , , ,120, ,030, ,90, , ,39

15
Анализ работы алгоритма на основе короткого хеша Процент нахождения модификаций изображений Параметр Значение порога бит 64 бита Смена цветовой модели на Xyz 66,3%93% 100% Смена цветовой модели на Yuv 43%65%74%82% Поворот на 1,189,2%90%96,8%100% Поворот на 1,288,6%91%94,2%100% Поворот на 1,387,4%100%93,2%100% Размытие 1%100% Размытие 3%97,3%100% Масштаб 1/2100% Масштаб 1/3100% Масштаб 1/4100%

16
Анализ работы каскадного алгоритма Блок хеша Порог Число ложно найденных изображений Число не найденных модификаций изображений phash0 (8 бит) phash1 (8 бит) phash2 (16 бит) phash3 (32 бита) phash (960 бит)25090
5621877 phash1 (8 бит)4427225 phash2 (16 бит)8387012 phash3 (32 бита)14273913 phash (960 бит)25090")
17
Анализ работы каскадного алгоритма Количество входных изображений Размер базы изображений Время обработки всех входных изображений, с Среднее время работы алгоритма, с , , , , , , , , ,20,01

18
выводы В данной работе было построено и исследовано несколько алгоритмов поиска изображений. Анализировались качество и скорость алгоритмов на основе полного и короткого хеша, каскадный поиск. Тестирование проходило на базе из 1000 и изображений; рассматривалось несколько перечней модификаций. Наиболее эффективным оказался каскадный поиск по отсортированному хешу. Он обладает высокой скоростью на больших объемах данных (0.015 с.), устойчив к масштабированию, изменению цветовой гаммы и размытию. Данный алгоритм выдаёт среднюю ошибку В ходе работы были реализованы три алгоритма поиска изображений по заданным оригиналам; функции формирования базы уникальных шаблонов, создание модифицированных изображений, преобразования изображения в хеш, вычисления расстояния между хешами, расчёта среднего значения информативности бит хеша, а также функции расчёта вероятности ошибок.

19
Пример работы каскадного алгоритма : Исходное изображение: Найденные изображения:

20
Спасибо за внимание!

21
модификации Средняя ошибка 0,000510,000280,00010, ,000810,00010,01682 Значение порога модификации Средняя ошибка 0,036060,034580,07480,005060,01280,0287 0,094 Значение порога модификации Средняя ошибка 0,09250,0480,05140,02470,00740,000450, Значение порога модификации 2425 Средняя ошибка 0,00670,0088 Значение порога 291

22
Методы сравнения гистограмм. Рассмотрим основные методы определения похожести гистограмм. Заметим, что перед сравнением гистограммы необходимо нормализовать (то есть привести к такому виду, чтобы сумма значений во всех ячейках была равна единице). Корреляционный метод. Похожесть гистограмм рассчитывается по формуле: Возвращаемое значение лежит в интервале [-1; 1], -1 означает максимальное соответствие, 1 – максимальное соответствие, 0 – отсутствие корреляции. Метрика хи-квадрат. Похожесть гистограмм рассчитывается по формуле: Возвращаемое значение лежит в интервале [0; неограниченно), 0 означает максимальное соответствие. Значение метрики для случая максимального несоответствия зависит от количества ячеек гистограммы.
. Ко")
23
Расстояние Бхатачария. Похожесть гистограмм рассчитывается по формуле: Возвращаемое значение лежит в интервале [0; 1], 0 означает максимальное соответствие, 1 – максимальное соответствие.
![Расстояние Бхатачария. Похожесть гистограмм рассчитывается по формуле: Возвращаемое значение лежит в интервале [0; 1], 0 означает максимальное соответствие, 1 – максимальное соответствие.](http://images.myshared.ru/73/1368363/slide_23.jpg "Расстояние Бхатачария. Похожесть гистограмм рассчитывается по формуле: Возвращаемое значение лежит в интервале [0; 1], 0 означает максимальное соответствие, 1 – максимальное соответствие.")
24
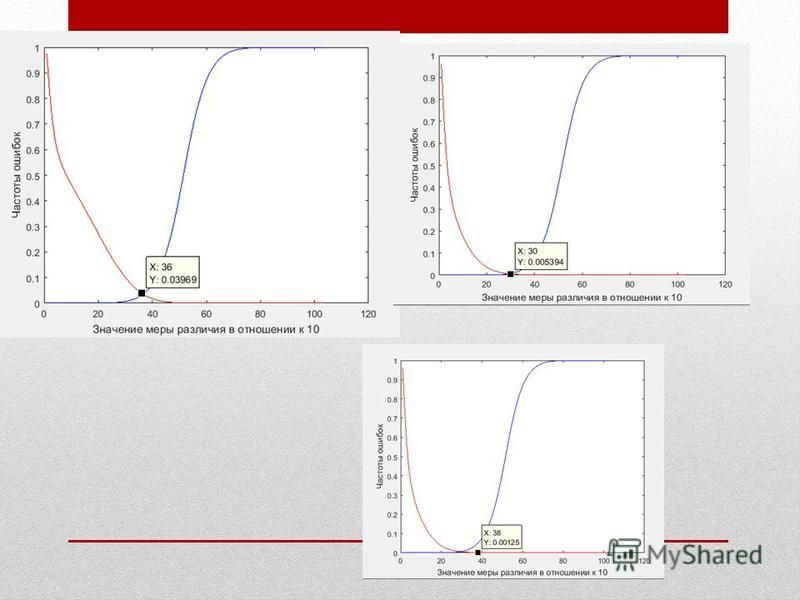
Средняя ошибка составляет 0,018. Пересечение ошибок первого и второго рода

25
Критерии оценки алгоритмов Ошибка первого рода (FRR – False Rejection Rate) – вероятность «не пропустить своего». В контексте данной работы это вероятность того, что в результате действия алгоритма не найдено изображений, подобных данному, несмотря на то, что они там есть. Ошибка второго рода (FAR – FalseAcceptanceRate) – это вероятность «пропустить чужого», то есть алгоритм находит изображения, которые не являются однотипными входному объекту.
 – вероятность «не пропустить своего». В контексте данной работы это вероятность того, что в результате действия алгоритма не найдено изображений, подобных данному, несмотря н")
27
MATLAB это высокоуровневый язык и интерактивная среда для программирования, численных расчетов и визуализации результатов. С помощью MATLAB можно анализировать данные, разрабатывать алгоритмы, создавать модели и приложения.

28
Ошибки первого и второго рода для определённого порога Модификация изображения Ошибка 1 рода Ошибка 2 рода Смена цветовой модели на Xyz 00,02453 Смена цветовой модели на Yuv 0,014450,02245 Поворот на 1,10,001090,01953 Поворот на 1,20,0010,01949 Поворот на 1,30, ,01954 Размытие 1%00,02344 Размытие 3%0,000090,02417 Масштаб 1/20,000090,02343 Масштаб 1/30,000090,02334 Масштаб 1/40,000270,023505

30
Язык, инструментарий и встроенные математические функции позволяют вам исследовать различные подходы и получать решение быстрее, чем с использованием электронных таблиц или традиционных языков программирования, таких как C/C++ или Java. MATLAB широко используется в таких областях, как: обработка сигналов и связь, обработка изображений и видео, системы управления, автоматизация тестирования и измерений, финансовый инжиниринг, вычислительная биология и т.п. Более миллиона инженеров и ученых по всем миру используют MATLAB в качестве языка технических вычислений. MATLAB по сравнению с традиционными языками программирования (C/C++, Java, Pascal, FORTRAN) позволяет на порядок сократить время решения типовых задач и значительно упрощает разработку новых алгоритмов. Ядро MATLAB позволяет максимально просто работать с матрицами реальных, комплексных и аналитических типов данных и со структурами данных и таблицами поиска. Все встроенные функции ядра MATLAB разработаны и оптимизированы специалистами и работают быстрее или так же, как их эквивалент на C/C++.

31
Гауссов шум на изображении Гауссов шум характеризуется добавлением к каждому пикселю изображения значений из соответствующего нормального распределения с нулевым средним значением..

Еще похожие презентации в нашем архиве:











 на тему: Презентация «Информационные модели»")


 X 1 X n... Y 1 Y m Входной слой Скрытый слой (Радиальный) Выходной слой...")







