Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Quantitative Data Analysis: Statistics

2
Sherlock Holmes "... while man is an insoluble puzzle, in the aggregate he becomes a mathematical certainty. You can, for example, never foretell what any one man will do, but you can say with precision what an average number will be up to. Individuals vary, but percentages remain constant. So says the statistician"

3
Overview General Statistics The Normal Distribution Z-Tests Confidence Intervals T-Tests

4
General Statistics ~ THE GOLDEN RULE ~ Statistics NEVER replace the judgment of the expert.

5
Approach to Statistical Research 1. Formulate a Hypothesis 2. State predictions of the hypothesis 3. Perform experiments or observations 4. Interpret experiments or observations 5. Evaluate results with respect to hypothesis 6. Refine hypothesis and start again (Basically the same as all other research)

6
Hypothesis Testing H 0 : Null Hypothesis, status quo H A : Alternative Hypothesis, research question So, either : "The data does not support H 0 " or "We fail to reject H 0 "

7
Types of Data Continuous height, age, time Discrete # of days worked this week, # leaves on a tree Ordinal {Good, O.K., Bad} Nominal {Yes/No}, {Teacher/Chemist/Haberdasher}

8
Picturing The Data

9
Pie Charts Nominal/Ordinal Only suitable for data that adds up to 1 Hard to compare values in the chart

10
Bar Charts Nominal/Ordinal Easier to compare values than pie chart Suitable for a wider range of data

11
Dot Plots Nominal/Ordinal Represents all the data Difficult to read

12
Box Plots Nominal/Ordinal 1IQR, 3IQR Outliers

13
Scatter Plots Excellent for examining association between two variables

14
Histograms Continuous Data Divide Data into ranges

15
Time-Series Plots Time related Data e.g. Stock Prices

16
Question 1 In a telephone survey of 68 households, when asked do they have pets, the following were the responses : 16 : No Pets 28 : Dogs 32 : Cats Draw the appropriate graphic to illustrate the results !!

17
Question 1 - Solution Total number surveyed = 68 Number with no pets = 16 =>Total with pets = ( ) = 52 But total 28 dogs + 32 cats = 60 => So some people have both cats and dogs
 = 52 But total 28 dogs + 32 cats = 60 => So some people have both cats and dogs")
18
Question 1 - Solution How many? It must be ( ) = 8 people No pets = 16 Dogs = 20 Cats = 24 Both = Total = 68
 = 8 people No pets = 16 Dogs = 20 Cats = 24 Both = 8 ------------------------- Total = 68")
19
Question 1 - Solution Graphic: Pie Chart or Bar Chart

20
The Literary Digest Poll 1936 US Presidential Election Alf Landon (R) vs. Franklin D. Roosevelt (D)
 vs. Franklin D. Roosevelt (D)")
21
The Literary Digest Poll Literary Digest had been conducting successful presidential election polls since 1916 They had correctly predicted the outcomes of the 1916, 1920, 1924, 1928, and 1932 elections by conducting polls. These polls were a lucrative venture for the magazine: readers liked them; newspapers played them up; and each ballot included a subscription blank.

22
The Literary Digest Poll They sent out 10 million ballots to two groups of people: prospective subscribers, who were chiefly upper- and middle-income people a list designed to "correct for bias" from the first list, consisting of names selected from telephone books and motor vehicle registries

23
The Literary Digest Poll Response rate: approximately 25%, or 2,376,523 responses Result: Landon in a landslide (predicted 57% of the vote, Roosevelt predicted 40%) Election result: Roosevelt received approximately 60% of the vote
 Election result: Roosevelt received approximately 60% of the vote")
24
The Literary Digest Poll POSSIBLE CAUSES OF ERROR Selection Bias: By taking names and addresses from telephone directories, survey systematically excluded poor voters. Republicans were markedly overrepresented in 1936, Democrats did not have as many phones, not as likely to drive cars, and did not read the Literary Digest Sampling Frame is the actual population of individuals from which a sample is drawn: Selection bias results when sampling frame is not representative of the population of interest

25
The Literary Digest Poll POSSIBLE CAUSES OF ERROR Non-response Bias: Because only 20% of 10 million people returned surveys, non- respondents may have different preferences from respondents Indeed, respondents favored Landon Greater response rates reduce the odds of biased samples

26
Terminology Population: is a set of entities concerning which statistical inferences are to be drawn. Sample: a number of independent observations from the same probability distribution Parameter: the distribution of a random variable as belonging to a family of probability distributions, distinguished from each other by the values of a finite number of parameters Bias: a factor that causes a statistical sample of a population to have some examples of the population less represented than others.

27
Outliers (and their treatment) An "outlier" is an observation that does not fit the pattern in the rest of the data Check the data Check with the measurer If reason to believe it is NOT real, change it if possible, otherwise leave it out (but note). If reason to believe it is real, leave it out and note.
 An")
28
The Mean The Mean (Arithmetic) The mean is defined as the sum of all the elements, divided by the number of elements. The statistical mean of a set of observations is the average of the measurements in a set of data
 The mean is defined as the sum of all the elements, divided by the number of elements. The statistical mean of a set of observations is the average of the measurements in a set of data")
29
The Variance But there can be a lot of variance in individual elements, e.g. teacher salaries Average = 22,000 Lowest = 12,000 Difference = 12, ,000 = -10,000

30
The Variance Sum of (Sample - Average) = 0, thus we need to define variance. The variance of a set of data is a cumulative measure of the squares of the difference of all the data values from the mean divided by sample size minus one.
 = 0, thus we need to define variance. The variance of a set of data is a cumulative measure of the squares of the difference of all the data values from the mean divided by sample size minus one.")
31
Standard Deviation The standard deviation of a set of data is the positive square root of the variance. - 1

32
Question 2 Find the mean and variance of the following sample values : 36, 41, 43, 44, 46

33
Question 2 Mean: ( )/5 = 42 Variance Difference Square 36 – 42 = – 42 = – 42 = – 42 = – 42 = / (5 -1) = 58 / 4 = 14.5
/5 = 42 Variance Difference Square 36 – 42 = -6 36 41 – 42 = -1 1 43 – 42 = 1 1 44 – 42 = 2 4 46 – 42 = 4 16 ---------------------------------------- 58 58 / (5 -1) = 58 / 4 = 14.5")
34
The Normal Distribution

36
Density Curves: Properties

37
The Normal Distribution The graph has a single peak at the center, this peak occurs at the mean The graph is symmetrical about the mean The graph never touches the horizontal axis The area under the graph is equal to 1

38
Characterization A normal distribution is bell-shaped and symmetric. The distribution is determined by the mean mu, and the standard deviation sigma,. The mean mu controls the center and sigma controls the spread.

48
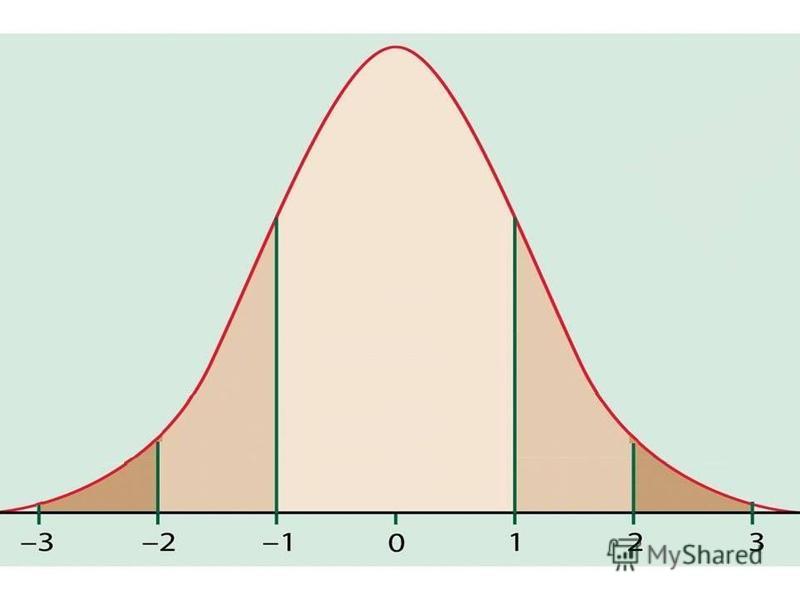
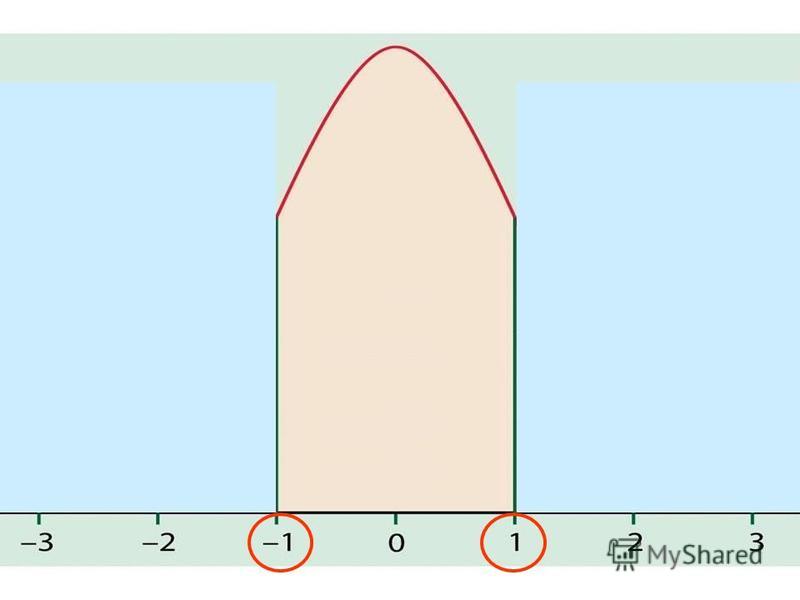
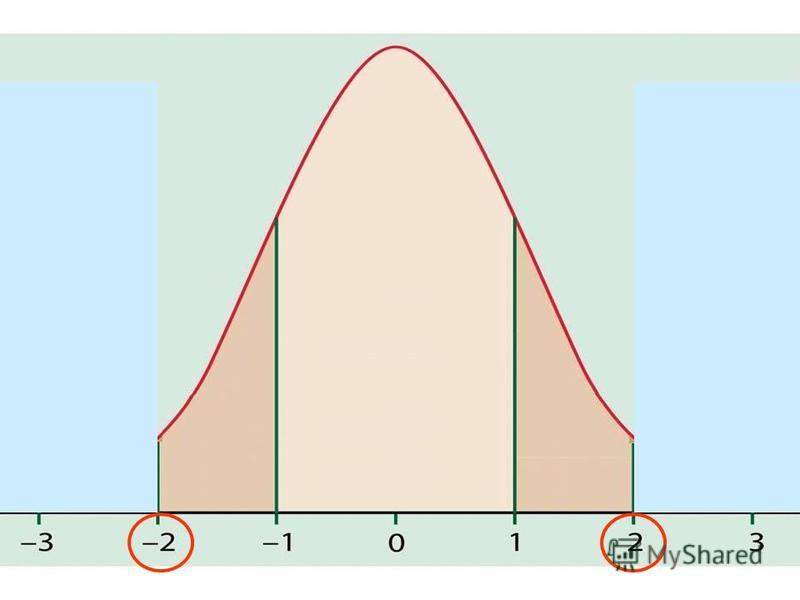
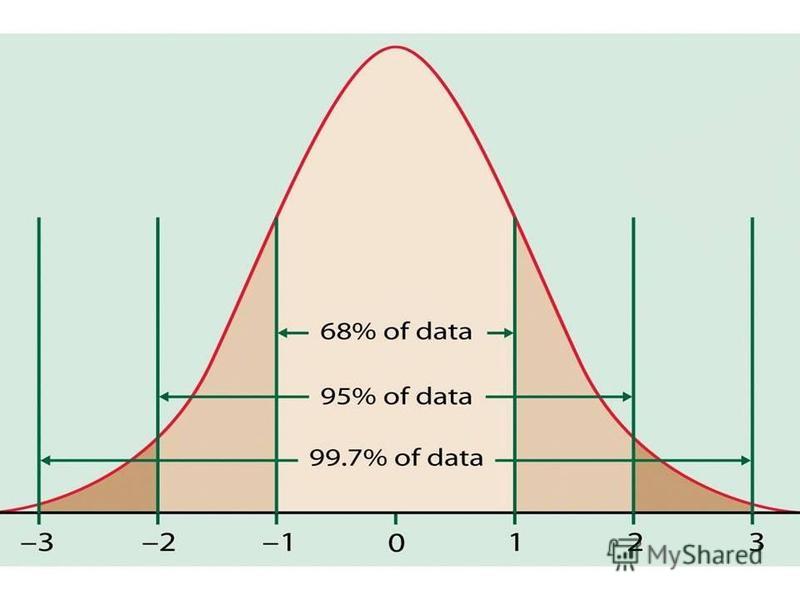
The Normal Distribution If a variable is normally distributed, then: within one standard deviation of the mean there will be approximately 68% of the data within two standard deviations of the mean there will be approximately 95% of the data within three standard deviations of the mean there will be approximately 99.7% of the data

49
The Normal Distribution

50
Why? One reason the normal distribution is important is that many psychological and organsational variables are distributed approximately normally. Measures of reading ability, introversion, job satisfaction, and memory are among the many psychological variables approximately normally distributed. Although the distributions are only approximately normal, they are usually quite close.

51
Why? A second reason the normal distribution is so important is that it is easy for mathematical statisticians to work with. This means that many kinds of statistical tests can be derived for normal distributions. Almost all statistical tests discussed in this text assume normal distributions. Fortunately, these tests work very well even if the distribution is only approximately normally distributed. Some tests work well even with very wide deviations from normality.

52
One Tail / Two Tail Imagine we undertook an experiment where we measured staff productivity before and after we introduced a computer system to help record solutions to common issues of work Average productivity before = 6.4 Average productivity after = 9.2

53
One Tail / Two Tail Before = 6.4 After =

54
One Tail / Two Tail Before = 6.4 After =

55
One Tail / Two Tail Before = 6.4 After =

56
One Tail / Two Tail Before = 6.4 After =

57
One Tail / Two Tail Before = 6.4 After =

58
One Tail / Two Tail Before = 6.4 After =

59
One Tail / Two Tail Before = 6.4 After =

60
One Tail / Two Tail Before = 6.4 After = σ σ σ

61
One Tail / Two Tail One-Tailed H0 : m1 >= m2 HA : m1 < m2 Two-Tailed H0 : m1 = m2 HA : m1 <>m2

62
STANDARD NORMAL DISTRIBUTION Normal Distribution is defined as N(mean, (Std dev)^2) Standard Normal Distribution is defined as N(0, (1)^2)
^2) Standard Normal Distribution is defined as N(0, (1)^2)")
63
STANDARD NORMAL DISTRIBUTION Using the following formula : will convert a normal table into a standard normal table.

64
Exercise If the average IQ in a given population is 100, and the standard deviation is 15, what percentage of the population has an IQ of 145 or higher ?

65
Answer P(X >= 145) P(Z >= (( )/15)) P(Z >= 3) From tables: 99.87% are less than 3 => 0.13% of population
 P(Z >= ((145 - 100)/15)) P(Z >= 3) From tables: 99.87% are less than 3 => 0.13% of population")
66
Trends in Statistical Tests used in Research Papers HistoricallyCurrently Results in: Accept/Reject Results in: p-Value Results in: Approx. Mean

67
Confidence Intervals A confidence interval is used to express the uncertainty in a quantity being estimated. There is uncertainty because inferences are based on a random sample of finite size from a population or process of interest. To judge the statistical procedure we can ask what would happen if we were to repeat the same study, over and over, getting different data (and thus different confidence intervals) each time.

68
Confidence Intervals If we know the true population mean and sample n individuals, we know that if the data is normally distributed, Average mean of these n samples has a 95% chance of falling into the interval

69
Confidence Intervals where the standard error for a 95% CI may be calculated as follows;

70
Example 1

71
Does FF-PD-G have more of the popular vote than FG-L ? In a random sample of 721 respondents : 382 FF-PD-G 339 FG-L Can we conclude that FF-PD-G has more than 50% of the popular vote ?

72
Example 1 - Solution Sample proportion = p = 382/721 = 0.53 Sample size = n = 721 Standard Error = (SqRt((p(1-p)/n))) = % Confidence Interval / (0.02) / [0.49, 0.57] Thus, we cannot conclude that FF-PD-G had more of the popular vote, since this interval spans 50%. So, we say: "the data are consistent with the hypothesis that there is no difference"
![Example 1 - Solution Sample proportion = p = 382/721 = 0.53 Sample size = n = 721 Standard Error = (SqRt((p(1-p)/n))) = 0.02 95% Confidence Interval 0.53 +/- 1.96 (0.02) 0.53 +/- 0.04 [0.49, 0.57] Thus, we cannot conclude that FF-PD-G had more of the](http://images.myshared.ru/26/1293192/slide_72.jpg "Example 1 - Solution Sample proportion = p = 382/721 = 0.53 Sample size = n = 721 Standard Error = (SqRt((p(1-p)/n))) = 0.02 95% Confidence Interval 0.53 +/- 1.96 (0.02) 0.53 +/- 0.04 [0.49, 0.57] Thus, we cannot conclude that FF-PD-G had more of the")
73
Example 2

74
Did Obama have more of the popular vote than McCain ? In a random sample of 1000 respondents 532 Obama 468 McCain Can we conclude that Obama had more than 50% of the popular vote ?

75
Example 2 – 95% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = % Confidence Interval / (0.016) / [0.5006, ] Thus, we can conclude that Obama had more of the popular vote, since this interval does not span 50%. So, we say : "the data are consistent with the hypothesis that there is a difference in a 95% CI"
![Example 2 – 95% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 95% Confidence Interval 0.532 +/- 1.96 (0.016) 0.532 +/- 0.03136 [0.5006, 0.56336] Thus, we can conclude that Obama had mor](http://images.myshared.ru/26/1293192/slide_75.jpg "Example 2 – 95% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 95% Confidence Interval 0.532 +/- 1.96 (0.016) 0.532 +/- 0.03136 [0.5006, 0.56336] Thus, we can conclude that Obama had mor")
76
Example 2 – 99% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = % Confidence Interval / (0.016) / [0.491, 0.573] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%. So, we say : "the data are consistent with the hypothesis that there is no difference in a 99% CI"
![Example 2 – 99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99% Confidence Interval 0.532 +/- 2.58 (0.016) 0.532 +/- 0.041 [0.491, 0.573] Thus, we cannot conclude that Obama had more](http://images.myshared.ru/26/1293192/slide_76.jpg "Example 2 – 99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99% Confidence Interval 0.532 +/- 2.58 (0.016) 0.532 +/- 0.041 [0.491, 0.573] Thus, we cannot conclude that Obama had more")
77
Example 2 – 99.99% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = % Confidence Interval / (0.016) / [0.472, 0.592] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%. So, we say : "the data are consistent with the hypothesis that there is no difference in a 99.99% CI"
![Example 2 – 99.99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99.99% Confidence Interval 0.532 +/- 3.87 (0.016) 0.532 +/- 0.06 [0.472, 0.592] Thus, we cannot conclude that Obama had](http://images.myshared.ru/26/1293192/slide_77.jpg "Example 2 – 99.99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99.99% Confidence Interval 0.532 +/- 3.87 (0.016) 0.532 +/- 0.06 [0.472, 0.592] Thus, we cannot conclude that Obama had")
78
T-Tests

79
One Tail / Two Tail T-test Z-test

80
T-Tests powerful parametric test for calculating the significance of a small sample mean necessary for small samples because their distributions are not normal one first has to calculate the "degrees of freedom"

81
T-Tests The t-test is often called the Student's t-test. It was created by a chief brewer named William S. Gossett who worked for the Guinness Brewery. He discovered this statistic as part of his work in the brewery to compare the different brewing processes for changing raw materials into beer. Guinness did not allow its employees to publish results but the management decided to allow Gossett to publish it under a pseudonym - Student. Hence we have the Student's t-test.

82
T-Test ~ THE GOLDEN RULE ~ Use the t-Test when your sample size is less than 30

83
T-Tests If the underlying population is normal If the underlying population is not skewed and reasonable to normal (n < 15) If the underlying population is skewed and there are no major outliers (n > 15) If the underlying population is skewed and some outliers (n > 24)
 If the underlying population is skewed and there are no major outliers (n > 15) If the underlying population is skewed and som")
84
T-Tests Form of Confidence Interval with t- Value Mean +/- tValue * SE as before as before

85
Two Sample T-Test: Unpaired Sample Consider a questionnaire on computer use to final year undergraduates in year 2007 and the same questionnaire give to undergraduates in As there is no direct one-to-one correspondence between individual students (in fact, there may be different number of students in different classes), you have to sum up all the responses of a given year, obtain an average from that, down the same for the following year, and compare averages.

86
Two Sample T-Test: Paired Sample If you are doing a questionnaire that is testing the BEFORE/AFTER effect of parameter on the same population, then we can individually calculate differences between each sample and then average the differences. The paired test is a much strong (more powerful) statistical test.

87
Choosing the right test

88
Choosing a statistical test

89
Choosing a statistical test

Еще похожие презентации в нашем архиве:














 distribution is a continuous probability distribution that has a bell-shaped probability.")


![Statistics Probability. Statistics is the study of the collection, organization, analysis, and interpretation of data.[1][2] It deals with all aspects.](/thumbs/17/1175940/big_thumb.jpg "Statistics Probability. Statistics is the study of the collection, organization, analysis, and interpretation of data.[1][2] It deals with all aspects.")
. Family How could you describe the word family? First of all family means a close unit of parents and their.")






