Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Rīgas Tehniskā universitāte Datorzinātnes un informācijas tehnoloģijas fakultāte Lietišķo datorsistēmu institūts Programmatūras izstrādes tehnoloģijas profesora grupa G.MATISONS Datu struktūras Lekciju konspekts Rīga, 2003

2
G.Matisons - "Datu struktūras", Rīga Literatūras saraksts 1. Daniel Stubbs, Neil W. Webre. Data Structures with Abstract Data Types and Pascal. Brooks/Cole Publ. Company, 1989, Ca, p Robert Leroy Kruse. Data Structures and Program Design. Prentice Hall, 1994, p Ellis Honowitz, Sartaj Sahni. Fundamentals of Data Structures in Pascal. 4-th edition. W.H.Freeman and Company, NJ, 1990, p D.Wood. Data Structures, Algorithms and Performance. Addison – Wesley Publishing Company, NJ, 1993, p Mark Allen Weiss. Data Sructures & Algorithms Analysis in Java. Addison – Wesley Publishing Company, 1999, p Вирт Н. Алгортмы и структуры данных / Пер. с англ. – М., Мир, 1989, 360 с. 7. Трамбле Ж., Соресон П. Введение в структуры данных. М., Машиностроение, 1982, 784 с. 8. Бертисс А.Т. Структуры данных / Пер. с англ. М., Статистика, Макаровский В.Н. Информационные системы и структуры данных. М., Статистика, Wayne Amsbrery. Data Structures from Arrays to Priority Queues. Wadsworth Publishing Company, 1985, p.516.

3
G.Matisons - "Datu struktūras", Rīga DATU (data) JĒDZIENS Programmas datu apstrādes procesā operē ar datiem. Izveidojot jaunas programmas, galvenā uzmanība ir jāpievērš ne tikai datu apstrādes algoritmu struktūrai, analīzei un izvēlei, ne tikai pašam programmēšanas procesam vien. Programmēšanas metodoloģijā liela nozīme ir arī datu lietojuma un datu uzbūves aspektiem. Programmu var uzskatīt par konkrētu abstraktu algoritmu realizāciju, balstoties uz datu uzbūvi un reālu attēlojumu. Datu apstrādes algoritma izvēle ir atkarīga no datu uzbūves. Tātad programmas struktūra un datu struktūra ir savā starpā cieši saistīti jēdzieni. Dati ir primāri, programma ir sekundāra. Dati ir jebkuras programmas neatņemama sastāvdaļa. Dati jāuztver un jāinterpretē kā reālu objektu abstrakcija – veidojumi, kas var arī nebūt paredzēti programmēšanas valodās. Datiem var būt dažāds sarežģītības un organizācijas līmenis. Skaidrojošā vārdnīca Webster: Dati ir faktuāla informācija, piemēram, mērījumi, statistika un tml. par objektiem, notikumiem un parādībam, kas kodēta formalizētā veidā, kas derīga šīs informācijas vākšanai, glabāšanai un apstrādei ar nolūku iegūt jaunu informāciju. Dati un informācija ir sinonīmiski jēdzieni, kas tomēr nav identiski. Dati ir formalizētā veidā attēlota informācija jaunas informācijas iegūšanai. Datiem ir noteikta uzbūve jeb struktūra. Struktūra ir datu elementu saistības raksturs un to izkārtojums objektā vai sistēmā.

4
G.Matisons - "Datu struktūras", Rīga DATU TIPA (data type) JĒDZIENS Matemātikā datus klasificē pēc noteiktām pazīmēm un īpašībām. Ir skaitliskie dati un loģiskie dati. Skaitliskie dati iedalāmi veselos, reālos un kompleksos skaitļos. Dati glabājas datoros, un datori operē ar datiem. Šie dati ir klasificējami pēc datu tipiem. Katrā programmēšanas valodā ir definēti savi konkrēti datu tipi. Vienkāršākie datu tipi, kas realizēti valodā Pascal ir šādi: char integer (apakštipi: byte, word, shortint, longint) real (apakštipi: single, double, extended) boolean Šiem tipiem atbilstošie mainīgie, konstantes un funkcijas pieņem vērtības, ar kurām datu apstrādes procesā tiek izpildītas dažādas darbības: aprēķini, datu ievade, datu izvade utt. Datu tips ir 1) iespējamo vērtību kopums; 2) operāciju kopums šo vērtību apstrādei. Katram datu tipam atbilst noteikts vērtību kopums, ko sauc par domēnu (domain). Domēns Tips Vērtību kopums char alfabēta ASCII rakstzīmes – 256 gb. integer MinInt.. MaxInt boolean false.. true

, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācija" title="G.Matisons - "Datu struktūras", Rīga 2003 5 DATU STRUKTŪRAS (data structure) JĒDZIENS TipsOperāciju kopums charpiešķire := salīdzināšanas operācijas =, =, =, <>, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācija" class="link_thumb">
5
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRAS (data structure) JĒDZIENS TipsOperāciju kopums charpiešķire := salīdzināšanas operācijas =, =, =, <>, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācijas =, =, =, <>, in booleanpiešķire := loģiskās operācijas not, and, or, xor salīdzināšanas operācijas =, =, =, <>, in realpiešķire := aritmētiskās operācijas +, -, *, / salīdzināšanas operācijas =, =, =, <> Datu organizācijas un datu elementu sasaistes raksturs, iespējamo vērtību kopums un iespējamo operāciju kopums ir datu struktūra. Datu struktūra ir jebkuram informācijas objektam piemītoša īpašība. Datu struktūra ir jebkuras programmēšanas sistēmas vai vides neatņemama sastāvdaļa. Teorētiskās un praktiskās zināšanas par datu struktūrām ir nepieciešamas, izstrādājot: informācijas sistēmas, datu bāzu pārvaldības sistēmas, mākslīgā intelekta sistēmas, lēmumu pieņemšanas un vadības sistēmas, ekspertu sistēmas, imitācijas un modelēšanas sistēmas, programmēšanas valodu komplikatorus, operētājsistēmas u.c.
, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācija">
, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācijas =, =, =, <>, in booleanpiešķire := loģiskās operācijas not, and, or, xor salīdzināšanas operācijas =, =, =, <>, in realpiešķire := aritmētiskās operācijas +, -, *, / salīdzināšanas operācijas =, =, =, <> Datu organizācijas un datu elementu sasaistes raksturs, iespējamo vērtību kopums un iespējamo operāciju kopums ir datu struktūra. Datu struktūra ir jebkuram informācijas objektam piemītoša īpašība. Datu struktūra ir jebkuras programmēšanas sistēmas vai vides neatņemama sastāvdaļa. Teorētiskās un praktiskās zināšanas par datu struktūrām ir nepieciešamas, izstrādājot: informācijas sistēmas, datu bāzu pārvaldības sistēmas, mākslīgā intelekta sistēmas, lēmumu pieņemšanas un vadības sistēmas, ekspertu sistēmas, imitācijas un modelēšanas sistēmas, programmēšanas valodu komplikatorus, operētājsistēmas u.c.">
, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācija" title="G.Matisons - "Datu struktūras", Rīga 2003 5 DATU STRUKTŪRAS (data structure) JĒDZIENS TipsOperāciju kopums charpiešķire := salīdzināšanas operācijas =, =, =, <>, in integerpiešķire := aritmētiskās operācijas +, -, *, mod, div salīdzināšanas operācija">

6
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRAS (DS) UN TO KLASIFIKĀCIJA Vienkāršas datu struktūras ir tādas DS, kurām atbilstošās vērtības ir skalāra tipa dati, kas nav sadalāmas sīkākās sastāvdaļās jeb datu elementos. Vienkāršas datu struktūras ir char, integer, real, boolean u.c. skalāra tipa dati. char – A, 7 integer – 10, -5 boolean – true real – 1.23 Fundamentālas datu struktūras ir tādas DS, kurām atbilstošās vērtības ir elementu kopums, kas sadalāms sastāvdaļās jeb komponentos. Fundamentālās datu struktūras bieži izmanto, lai veidotu saliktas datu struktūras ar sarežģītāku uzbūvi. Fundamentālām DS atbilstošās vērtības ir strukturēta tipa dati, piemēram, virknes – predefinēts datu tips string, masīvi – predefinēts datu tips array, ieraksti – predefinēts datu tips record. Piemēram: var A: array [ 1.. 3, 1.. 3] of integer; j A [i, j] – masīva elements, piemēram, A [1, 2] => A =047 i 138
5 25-9 A =047 i 138">

7
G.Matisons - "Datu struktūras", Rīga Par operatīvām DS sauc tādas DS, kuras tiek izvietotas un apstrādātas datora pamatatmiņā. DS datora diskatmiņā sauc par failu (datņu) struktūrām. Failu struktūras elements ir faila ieraksts. Savstarpēji saistītu failu struktūrās glabātu sarakstu kopums veido datu bāzi. Izvēli starp operatīvām DS un failu struktūrām nosaka piekļuves un apstrādes efektivitātes, kā arī atmiņas apjoma apsvērumi. Svarīga DS īpašība ir DS elementu sasaiste un sakārtotība. Atkarībā no tā DS ir iedalāmas: 1) lineārās datu struktūrās (masīvi, ieraksti, faili, saraksti); 2) nelineārās datu struktūrās (koki, grafi, daudzkāršsaistīti saraksti). Atkarībā no tā, kā mainās DS uzbūve, izpildot DS apstrādes operācijas, tās ir iedalāmas: 1) statiskās datu struktūrās (masīvi, ieraksti, tabulas); 2) dinamiskās datu struktūrās (saistīti saraksti, koki, grafi, faili). Reizēm runā arī par pusstatiskām DS (steki, rindas). Atkarībā no tā, kā DS elementi tiek izvietoti datora pamatatmiņā, DS ir iedalāmas šādi: 1) DS ar elementu secīgu izvietojumu pamatatmiņā (masīvi, ieraksti, tabulas); 2) DS ar elementu patvaļīgu izvietojumu pamatatmiņā (saistīti saraksti, koki, grafi). Atkarībā no tā, vai DS elements satur kāda cita DS elementa adresi (rādītāju uz nākamo vai iepriekšējo elementu), DS ir iedalāmas: 1) saistītās (linked) DS; 2) nesaistītās (nonlinked) DS.

8
G.Matisons - "Datu struktūras", Rīga Tabula ir nesaistītas DS piemērs. Atkarībā no tā, vai elementu izvietums datu struktūrā ir patvaļīgs un nav determinēts vai arī datu struktūrā elementi izvietoti pēc kādas noteiktas pazīmes, DS ir iedalāmas: 1) sakārtotās (ordered) datu struktūrās; 2) nesakārtotās (nonordered) datu struktūrās. Saistītās DS piemērs: el next tail current head... nil n 3 2 1

9
G.Matisons - "Datu struktūras", Rīga BIEŽĀK LIETOTĀS DATU STRUKTŪRAS kopa (angl. set) sasaiste (relationship) Datu struktūru, kurā starp elementiem nav nekādas citas sasaistes kā vienīgi tās, ka visi elementi pieder pie noteikta datu kopuma, sauc par kopu. Kopā starp elementiem nav sasaistes. Kopā nav elementa, ko var saukt par pirmo, pēdējo vai tekošo. Kopas piemēri: 1) studenti grupā, kuri mācās angļu valodu; 2) grāmatas par informācijas tehnoloģiju utml. Datu struktūru, kurā elementu sasaistes raksturs ir viens ar vienu (one-to-one), sauc par lineāru datu struktūru. Lineārā datu struktūrā katram elementam ir noteikts kārtas numurs, tajā ir elements, ko sauc par pirmo, un elements, kas ir pēdējais. Visiem elementiem, izņemot pirmo un pēdējo, ir viens vienīgs priekštecis (predecessor) un viens vienīgs pēctecis (sucessor). Pirmajam elementam nav priekšteca, bet pēdējam elementam nav pēcteča.

10
G.Matisons - "Datu struktūras", Rīga Lineārās datu struktūras lieto visbiežāk. Lineārās datu struktūras ir masīvi, ieraksti, faili un saraksti. Tās arī izmanto kā pamatelementus, veidojot datu struktūras ar sarežģītu uzbūvi. Datu struktūru, kurā elementu sasaistes raksturs ir viens ar vairākiem (one-to-many), sauc par koku (tree) jeb hierarhisku datu struktūru. Hierarhisks nozīmē to, ka datu struktūras elementi izvietoti vairākos līmeņos. Kokā ir unikāls elements, ko sauc par saknes virsotni. Katram elementam ir viens, vairāki vai neviens pēctecis, ko sauc par bērnu (child) un viens vienīgs priekštecis, ko sauc par vecāku (parient). Saknes virsotnei nav priekšteča, bet var būt pēcteči. Koka virsotnes, kurām nav pēcteču, sauc par lapām (leaf). Visbiežāk lieto bināros kokus, kuros katrai virsotnei nav vairāk kā 2 pēcteči. Katrs pēctecis ir kreisais bērns vai labais bērns. Virsotnes (node) kokā savienotas ar šķautnēm (edge). koks (tree) līmeņi

11
G.Matisons - "Datu struktūras", Rīga Datu struktūru, kurā elementu sasaistes raksturs ir vairāki ar vairākiem (many-to-many), sauc par grafu (graph) jeb tīklveida datu struktūru. Grafā nav elementa, ko sauc par pirmo vai par pēdējo. Katram elementam ir vairāki pēcteči un vairāki priekšteči. Elementi savienoti ar lokiem. Darbā ar grafiem svarīga operācija ir īsākā ceļa meklēšana starp virsotnēm. Grafus plaši lieto, uzdodot dažādus procesus, to stāvokļus un norises, ar grafu palīdzību risina arī optimizācijas problēmas. Kokus un grafus sauc arī par nelineārām datu struktūrām.

12
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRU IZSTRĀDE specification design implementation DS elementu uzbūve DS elementu sasaiste Domēns Operācijas Specifikācija Projektēšana Ieviešana DS attēlojums atmiņā

13
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRAS ATTĒLOJUMA PAŅĒMIENI UN MODEĻI 1. paņēmiens: adresevārds 1000Aivars 1008Markus 1016Edgars 1024Dainis 1032Centis Ja zināma i-tā saraksta elementa adrese, tad i + 1 – saraksta elementa adrese ir aprēķināma šādi: adrese i+1 = adrese i + l (l = 8, i = 1, 2,..., n-1) Vektorālā attēluma forma, izmantojot pozicionēšanu (array representation using positioning) 2. paņēmiens: adresevārds 1000Aivars Centis 1024Dainis 1032Edgars Markus Saraksta elementa adreses aprēķins: l * (ord(pb) – ord ('A')) (l = 8, ord(A)=65) pb – vārda pirmais burts Vektorālā attēluma forma, izmantojot hešēšanu jeb jaukšanu (array representation using hashing) Hešfunkciju lietojums elementa vietas noteikšanai sarakstā Kolīzijas un to novēršana

14
G.Matisons - "Datu struktūras", Rīga paņēmiens: adresevārdspēcteča adrese – sākumadrese 1000Aivars Centis Dainis Edgars Markus --- saraksta beigas Saistītā attēlojuma forma ar elementu sasaisti (linked representation using linkage). Saistīšana nozīmē, ka elementi sarakstā sasaistīti ar rādītājiem un ka jālieto arī speciāli rādītāji, izpildot saraksta apstrādes operācijas

15
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRAS ELEMENTU IDENTIFIKĀCIJA Lineāru un nelineāru DS elementiem ir vienāda uzbūve. Elementu veido 2 lauki: 1) informatīvs lauks data, kurā sakopota plaša un daudzveidīga informācija par DS elementu. Visai bieži šo lauku definē kā ierakstu, vienkāršākajā gadījumā kā rakstzīmju virkni; 2) atslēgas laiks key, kas satur unikālu informāciju jeb kodu, kas viennozīmīgi identificē DS elementu. Parasti DS nav vairāki elementi ar vienu un to pašu atslēgu. Atslēgas laukam var uzdot jebkuru skalāru ordinālo tipu vai virknes tipu string. 1) vektoriālā formā attēlots modelis: ListInstance List

16
G.Matisons - "Datu struktūras", Rīga DS elementa uzbūve: el [i], i = 1, 2,..., n KeyType – jebkurš skalārs ordināls tips vai virknes tips string; DataType – jebkurš tips, strukturēts vai skalārs. constMaxSize = 100; {maksimālais elementu skaits} typeKeyType = integer; {skalārs ordināls datu tips vai string} DataType = string; {jebkurš datu tips} StdElement = record {saraksta elementa tips} data: DataType; {informatīvs datu lauks} key: KeyType {unikālas atslēgas lauks} end; Saraksta el ir viendimensijas masīvs, kas ir definējams šādi; el: array [1.. MaxSize] of StdElement; data key tips DataType tips KeyType tips StdElement - ieraksts

17
G.Matisons - "Datu struktūras", Rīga const MaxSize = 100; {maksimālais elementu skaits} type DataType = string; {jebkurš datu tips} KeyType = integer; {skalārs ordināls datu tips vai string} StdElement = record data: DataType; {informatīvs datu lauks} key: KeyType {unikālas atslēgas lauks} end; NodePointer = ^ Node; {rādītāja datu tips} Node = record {saraksta elementa tips} el: StdElement; next: NodePointer {rādītāja lauks} end; 2) saistītā formā attēlots modelis: el next tail current... nil head el next el next pēd. elem. 2. elem. 1. elem. Node data key tips DataType tips KeyType tips StdElement - ieraksts el

18
G.Matisons - "Datu struktūras", Rīga DATU STRUKTŪRAS PROJEKTĒJUMA VĒRTĒŠANA Projektējot DS, jārisina šādas problēmas: 1) jānovērtē datu struktūras apstrādes operāciju izpildes laiks; 2) jāizvēlas, vai tiks veidota statiska vai dinamiska datu struktūra; 3) jānoskaidro, vai iespējams, ka datu struktūras elementiem varētu būt mainīgs garums; 4) jānovērtē algoritmu izpildes efektivitāte (sarežģītības pakāpe; 5) jāizvēlas, vai datu struktūra, strādājo ar to, tiks izvietota pamatatmiņā vai diskatmiņā. Piemēram: izveidots saraksts ar N elementiem, katrs saraksta elements ir kāds vārds, piemēram, Aivars. Sarakstā jāsameklē vārds Edgars un, ja meklēšana beigusies sekmīgi, jānosaka tā pozīcijas numurs. 1.paņēmiens - saraksts izvietots pamatatmiņā: const N = 500; {elementu skaits sarakstā} type Name = string [8]; {saraksta elementu tips} Arr = array [1.. N] of Name; {masīva tips} var List: Arr; {saraksts} i: 0.. N; Test: Name; i:= 0; repeat {meklēšana sarakstā} i:= i+1; Test:= List [i] until (Test = Edgars) or (i = N);

19
G.Matisons - "Datu struktūras", Rīga paņēmiens – saraksts izvietots diskatmiņā: const N = 500; {elementu skaits sarakstā} type Name = string [8]; {saraksta elementu tips} FL = file of Name; {faila tips} var List: FL; {saraksts} i: 0.. N; Test: Name; i:= 0; repeat {meklēšanā sarakstā} i:= i+1; read (List, Test) until (Test = Edgars) or (i = N); Priekšrocības: 1. paņēmiens – meklēšanas operācija ir ātrdarbīga; 2. paņēmiens – praktiski nav ierobežojumu DS apjomam (elementu skaitam); Trūkumi: 1. paņēmiens – DS apjoms ir ierobežots; 2. paņēmiens – meklēšanas operācija ir lēndarbīga.

20
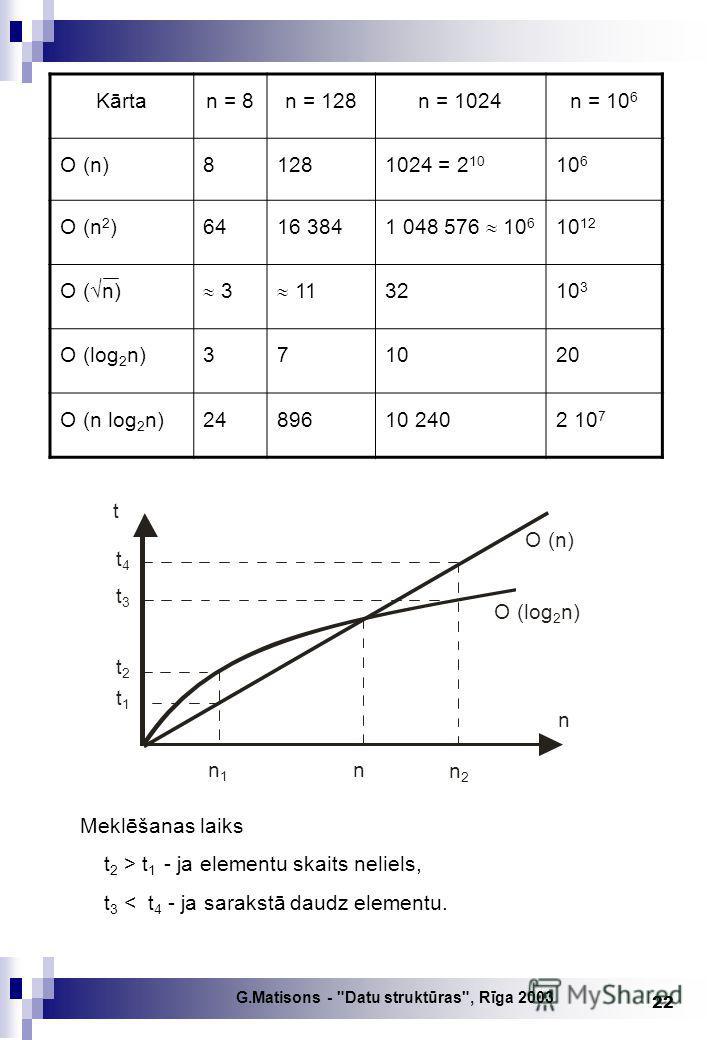
G.Matisons - "Datu struktūras", Rīga METRIKA EFEKTIVITĀTE, VEIKTSPĒJA (efficiency, performance) Bieži izpildāmas operācijas: 1) meklēšanas operācija – reducējama uz salīdzināšanu. Operācijas izpildes ātrumu nosaka salīdzinājumu skaits; 2) elementa dzēšana sarakstā – reducējama uz elementu pārvietošanu par 1 pozīciju virzienā uz dzēšamo elementu. Lai novērtētu algoritma efektivitāti izmanto: 1) salīdzināšanas vai pārsūtīšanas operāciju skaitu; 2) kopējo operatoru skaitu, alternatīvo zarojumu daudzumu, cikla izvietojuma dziļumu; 3) pierakstu matemātiskās kārtas veidā, piemēram, O(n). Salīdzinājumu skaits meklēšanas procesā: E c = n + 1,n – elementu skaits. 2 Meklēšanas laiks: t = C 1 E c + C o = C 1 n+1 + C o = C 1 n+ C o - lineāra 2 funkcija Izteiksmes lieluma kārtu nosaka tikai vislielākais operands, mazākie operandi vērtējumu būtiski neietekmē. O(n) n t

21
G.Matisons - "Datu struktūras", Rīga Dažu izteiksmju kārtas: n (n - 1)O (n 2 ) 2 15 log 2 n + 3n + 7O (n) 2n log 2 n + 0,1n O (n 2 ) 6 log 2 n + 3n + 7O (1) 2n – 5 n t O (n 2 ) n t O (log 2 n) n t O (1)
O (n 2 ) 2 15 log 2 n + 3n + 7O (n) 2n log 2 n + 0,1n 2 + 5 O (n 2 ) 6 log 2 n + 3n + 7O (1) 2n – 5 n t O (n 2 ) n t O (log 2 n) n t O (1)")
t 1 - ja element" title="G.Matisons - "Datu struktūras", Rīga 2003 22 Kārtan = 8n = 128n = 1024n = 10 6 O (n)81281024 = 2 10 10 6 O (n 2 )6416 384 1 048 576 10 6 10 12 O ( n) 3 11 3210 3 O (log 2 n)371020 O (n log 2 n)2489610 2402 10 7 Meklēšanas laiks t 2 > t 1 - ja element" class="link_thumb">
22
G.Matisons - "Datu struktūras", Rīga Kārtan = 8n = 128n = 1024n = 10 6 O (n) = O (n 2 ) O ( n) O (log 2 n) O (n log 2 n) Meklēšanas laiks t 2 > t 1 - ja elementu skaits neliels, t 3 < t 4 - ja sarakstā daudz elementu. n t O (log 2 n) O (n) n n1n1 n2n2 t4t4 t3t3 t2t2 t1t1
t 1 - ja element">
t 1 - ja elementu skaits neliels, t 3 < t 4 - ja sarakstā daudz elementu. n t O (log 2 n) O (n) n n1n1 n2n2 t4t4 t3t3 t2t2 t1t1">
t 1 - ja element" title="G.Matisons - "Datu struktūras", Rīga 2003 22 Kārtan = 8n = 128n = 1024n = 10 6 O (n)81281024 = 2 10 10 6 O (n 2 )6416 384 1 048 576 10 6 10 12 O ( n) 3 11 3210 3 O (log 2 n)371020 O (n log 2 n)2489610 2402 10 7 Meklēšanas laiks t 2 > t 1 - ja element">
23
G.Matisons - "Datu struktūras", Rīga RAKSTZĪMJU ATTĒLOŠANA AR MAINĪGU BITU SKAITU Ja bitu skaits rakstzīmes kodā n = 8, iespējams kodēt 2 8 = 256 rakstzīmes. Pieņemsim, ka ir teksts, kurā ir tikai 8 rakstzīmes. Tā kā 8 = 2 3, tad šo tekstu ir iespējams kodēt arī tā, ka katrai rakstzīmei paredz tikai 3 bitu kombināciju. Ir zināms šo 8 rakstzīmju lietojuma biežums (%): Uzdevums: atrast tādu attēlojuma formu, lai šis teksts aizņemtu vismazāk vietas atmiņā. Sāk ar to, ka izveido mežu, ko veido koki ar vienu vienīgu saknes virsotni, kas satur rakstzīmes lietojuma biežumu: Virsotnes sakārtotas lietojuma biežuma dilšanas secībā. Divas virsotnes, kurām ir viszemākais lietojuma biežums, apvieno binārajā kokā ar jaunu saknes virsotni un 2 zarojuma virsotnēm: Kokus atkal sakārto virsotņu vērtību dilšanas secībā: abcdefgh

24
G.Matisons - "Datu struktūras", Rīga Procesu turpina, vēlreiz apvienojot 2 virsotnes ar viszemākajiem lietojuma biežumiem, pēc tam kokus atkal sakārto saknes virsotņu vērtību dilšanas secībā: Vēlreiz atkārtojot procesu, iegūst šādu bināro koku: Līdzīgā veidā procesu atkārtojot vēl 4 reizes, iegūst rezultējošo bināro koku: Rakstzīmju lietojuma biežuma vērtības atrodas binārā koka lapu virsotnēs. Binārajā kokā katrai kreisajai šķautnei piešķir vērtību 0, labajai – a b c d e f g h

25
G.Matisons - "Datu struktūras", Rīga Katras rakstzīmes attēlojuma kods ir bitu virkne ceļā no saknes virsotnes uz lapas virsotni. Ir 8 šādi ceļi: Iegūto kodu sauc par Hafmena (Huffman) kodu. Tam piemīt tāda īpašība, ka nevienas rakstzīmes kods nav vienāds ar prefiksu kādas citas rakstzīmes kodā. Tāpēc no Hofmena koda var iegūt oriģinālo 8 bitu kodu. Lietojot Hofmaņa kodu teksta kodēšanai, būtu nepieciešami n (40*1 + 20*3 + 10*3 + 8*4 +8*4 + 5*4 + 5*5 +4*5)=2,59n biti 100 Atmiņas ietaupījums: 8n / 2,59n 3 - Hafmena kodu salīdzinot ar 8 bitu kodu 3n / 2,59n = 1,15 - Hafmena kodu salīdzinot ar 3 bitu kodu rakstzīmekodslietojuma biežums a 040 b c d e f g h

26
G.Matisons - "Datu struktūras", Rīga RAKSTZĪMJU VIRKNES JĒDZIENS Valodā Pascal rakstzīmju virkni iespējams definēt divējādi: 1) kā mainīga garuma rakstzīmju virkni, virknes aprakstā izmantojot predefinēto datu tipu string: type Text1 = string; Text2 = string [80]; var S: Text1; Q: Text2 ; S:= RTU; Q:=RIGA; S:= ; read(Q); writeln(Q); 1 maksimālais garums tekošais garums maksimālais garums Tekošais garums aizņem 0. baitu, tā maksimālā vērtība: = FF 16 = Tekošā garuma baits apstrādei tieši nav pieejams: var S: string [80]; L: byte absolute S; S:=ABC; writeln(L, S); 2) kā fiksēta garuma rakstzīmju virkni, virknes aprakstā izmantojot predefinēto datu tipu array: type Text1 = array [1..255] of char; Text2 = array [1..80] of char; tek. gar tg... baiti max gar. neizmantoti baiti teksts

255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju" title="G.Matisons - "Datu struktūras", Rīga 2003 27 var S:= Text1; Q:= Text2: S:= RTU; Q:= RIGA; writeln(S, Q); {izvadīs 335 rakstzīmes} Lieto tikai maksimālā garuma jēdzienu. Tas var būt arī > 255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju" class="link_thumb">
27
G.Matisons - "Datu struktūras", Rīga var S:= Text1; Q:= Text2: S:= RTU; Q:= RIGA; writeln(S, Q); {izvadīs 335 rakstzīmes} Lieto tikai maksimālā garuma jēdzienu. Tas var būt arī > 255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju virknes elementi ir alfabēta ASCII rakstzīmes. Katra rakstzīme atmiņā aizņem 1 baitu. Struktūra: rakstzīmju virknes elementiem ir lineāra sasaiste. Katram elementam ir unikāla pozīcija rakstzīmju virknē. Pirmais elements atrodas 1. pozīcijā. Domēns: visas iespējamās rakstzīmju kombinācijas ar garumu 0, 1,..., MaxLength. Maksimālo garumu MaxLenght definē kā konstanti, piemēram: const MaxLenght = 500; Tipi: String – rakstzīmju virknes rādītāja tips, StringPos = 1.. MaxLength – rakstzīmju virknes pozīcijas tips, StringLen = 0.. MaxLength – rakstzīmju virknes tekošā garuma tips.
255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju">
255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju virknes elementi ir alfabēta ASCII rakstzīmes. Katra rakstzīme atmiņā aizņem 1 baitu. Struktūra: rakstzīmju virknes elementiem ir lineāra sasaiste. Katram elementam ir unikāla pozīcija rakstzīmju virknē. Pirmais elements atrodas 1. pozīcijā. Domēns: visas iespējamās rakstzīmju kombinācijas ar garumu 0, 1,..., MaxLength. Maksimālo garumu MaxLenght definē kā konstanti, piemēram: const MaxLenght = 500; Tipi: String – rakstzīmju virknes rādītāja tips, StringPos = 1.. MaxLength – rakstzīmju virknes pozīcijas tips, StringLen = 0.. MaxLength – rakstzīmju virknes tekošā garuma tips.">
255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju" title="G.Matisons - "Datu struktūras", Rīga 2003 27 var S:= Text1; Q:= Text2: S:= RTU; Q:= RIGA; writeln(S, Q); {izvadīs 335 rakstzīmes} Lieto tikai maksimālā garuma jēdzienu. Tas var būt arī > 255. RAKSTZĪMJU VIRKNES TIPA SPECIFIKĀCIJA Elementi: rakstzīmju">

28
G.Matisons - "Datu struktūras", Rīga Operācijas: RAKSTZĪMJU VIRKNES ATTĒLOJUMA MODEĻI 1. paņēmiens – modelī paredzēts speciāls lauks tekošā garuma attēlošanai, virknes attēlošanai izmanto vektoriālā formā attēlotu modeli: Apkalpošanas operācijas PamatoperācijasPapildoperācijas Create Terminate Lenght Empty Full Append Concatenate Substring Delete Insert Match Find ReadString WriteString MakeEmpty Remove Equal Reverse Polindrome u.c. strlen data [1] data [2]... data [strlen]... data [MaxLength] tekošais garums virknes teksts brīvās pozīcijas StringInstance S: String

29
G.Matisons - "Datu struktūras", Rīga const MaxLength = 500; {uzdod lietotājs} type StringLen = 0.. MaxLength; StringPos = 1.. MaxLength; String = ^ StringInstance; StringInstance = record strlen: StringLen; data: array [StringPos] of char end; 2. paņēmiens – lieto vektoriālo attēlojuma formu, bet nav paredzets lauks tekošā garuma attēlošanai. Aiz virknes pēdējās rakstzīmes ieraksta virknes beigu pazīmi. Parasti izmanto vadības rakstzīmi NULL, kuras kods ir var paredzēt arī tādu paņēmienu, ka viss pārpalikušais vektors tiek aizpildīts ar šo vadības rakstzīmi. Robežmarķiera metode: const MaxLength = 500; type StringLen = 0.. MaxLength; StringPos = 1.. MaxLength; String = ^ StringInstance; StringInstance = array [ 1.. MaxLength +1] of char; data [1] data [2]... data [strlen]... data [MaxLength] teksts brīvās pozīcijas StringInstance S: String NULL

30
G.Matisons - "Datu struktūras", Rīga Trūkums: pirms operāciju izpildes jāsameklē virknes beigas, tā ir O (n) meklēšanas operācija. 3. paņēmiens: virknes attēlošanai izmanto saistītā formā attēlotu modeli. Rakstzīmju virknes teksts tiek sadalīts fragmentos (chunk) ar vienādu garumu, izņemot pēdējo posmu, kas var būt arī īsāks. const MaxLength = 500; {virknes maks.garums} ChunkSize = 10; {fragmenta garums} type ChunkPos = 1.. ChunkSize; StringLen = 0.. MaxLength; ChPointer = ^ Chunk; {elementu rādītāja tips} Chunk = record {virknes elementa fragments} data: array [ChunkPos] of char; next: ChPointer end; String = ^ StringInstance; StringInstance = record {vadības struktūra} head: ChPointer; {virknes sākuma rādītājs} tail: ChPointer; {virknes beigu rādītājs} strlen: StringLen {virknes tekošais garums} end; head datanext tail strlen... nil S: String StringInstance Chunk

31
G.Matisons - "Datu struktūras", Rīga MASĪVA JĒDZIENS Masīvs (array) – vienkāršākais strukturētais datu tips. Vēsturiski – pirmā programmēšanas valodā realizēta datu struktūra. Masīvi – visbiežāk lietotās fundamentālās datu struktūras. Masīvs – regulāra datu struktūra. Masīva elementi izvietoti dimensiju virzienā, katram elementam masīvā ir noteikts pozīcijas numurs, piemēram, A [2, 1, 3]. Masīvs ir homogēna (viendabīga) datu struktūra. Visiem elementiem ir vienāda uzbūve un viens un tas pats tips, ko sauc par bāzes tipu. Masīvs – datu struktūra, kuras elementu pieejai izmanto brīvpiekļuves metodi (random access method). Apstrādei pieejams jebkurš elements jebkurā secībā, izmantojot indeksizteiksmes, piemēram, A [i, j, k] Masīva tipa apraksts valodā Pascal: type T = array [I] of B; var A: T; I – indeksa tips, par to var būt tikai skalārs ordināls tips. Parasti to definē kā diapazona tipu ar indeksa augšējo un apakšējo robežvērtību: lo.. hi B – bāzes tips, par to var būt jebkurš datu tips, skalārs vai strukturēts datu tips, predefināts vai lietotaja definēts datu tips. Masīvs - lineāra datu struktūra. Viendimensijas masīva X apraksta piemērs: var X: array [ ] of real; I B

32
G.Matisons - "Datu struktūras", Rīga X [1] – masīva X pirmais elements, X [100] – masīva X pēdējais elements, X [i], i = 2, 3,...,99 - masīva X tekošais elements, X [i+1] – tā pēctecis, X [i-1] – tā priekštecis. Masīva elementu sasaistes raksturs: viens – ar – vienu. Ir 3 pamatoperācijas masīva elementu apstrādei, pie kam 3. operācija ir arī realizējama, izmantojot pirmās divas. type T = array [I] of B; var X, Y: T; C: B; 1) C:= X[i]; kur i – tipam I atbilstoša indeksizteiksme. {izguves operācija Retrieve} 2) X[i]:= e; kur e – bāzes tipam B atbilstoša izteiksme. {labošanas operācija Update} 3) Y:= X; ekvivalents ar for i:= 1 to n do Y [i]:= X [i]; {kopēšanas operācija Copy} Viendimensijas masīvu sauc par vektoru. Divdimensijas masīvu sauc par matricu. Masīva dimensiju skaitu praktiski ierobežo datorresursi, teorētiski šādu ierobežojumu nav. Piemēri: 1) type Row = array [ ] of real; Card = array [1.. 80] of char; Vector = array [ ] of integer; var A: Row; X, Y: Card; Q: Vector;

33
G.Matisons - "Datu struktūras", Rīga ) type Ind1 = ; Ind2 = ; Matrix = array [Ind1, Ind2] of real; var M: Matrix; 3) type Ind1 = ; Ind2 = ; Matrix = array [Ind1] of array [Ind2] of real; I B var M: Matrix;
![G.Matisons - Datu struktūras, Rīga 2003 33 2) type Ind1 = 1.. 10; Ind2 = 1.. 12; Matrix = array [Ind1, Ind2] of real; var M: Matrix; 3) type Ind1 = 1.. 10; Ind2 = 1.. 12; Matrix = array [Ind1] of array [Ind2] of real; I B var M: Matrix;](http://images.myshared.ru/19/1234678/slide_33.jpg "G.Matisons - Datu struktūras, Rīga 2003 33 2) type Ind1 = 1.. 10; Ind2 = 1.. 12; Matrix = array [Ind1, Ind2] of real; var M: Matrix; 3) type Ind1 = 1.. 10; Ind2 = 1.. 12; Matrix = array [Ind1] of array [Ind2] of real; I B var M: Matrix;")
34
G.Matisons - "Datu struktūras", Rīga MATRICAS JĒDZIENS UN INTERPRETĀCIJA Valodā Pascal iespējami 2 matricas interpretācijas veidi: 1) matrica ir divdimensiju masīvs, kura elementi izvietoti rindās un kolonnās, šādi matrica tiek interpretēta matemātikā. Programmēšanas valodās matricas interpretācija ir plašāka. const lo1 = 1; hi1 = 3; lo2 = 1; hi2 = 4; type Ind1 = lo1.. hi1; Ind2 = lo2.. hi2; B = real; Matrix = array [Ind1, Ind2] of B; var A: Matrix; j A [1,1] A[1,2] A[1,3] A[1,4] i A [2,1] A[2,2] A[2,3] A[2,4] A [3,1] A[3,2] A[3,3] A[3,4] Masīva elements ir mainīgais ar indeksiem: A [i,j],i = 1, 2, 3; j = 1, 2, 3, 4. (vispārējā gadījumā i = lo1, lo1+1,..., hi1, j = lo2, lo2+1,..., hi2). Katrai dimensijai jāuzdod sava indeksizteiksme. Mainīgais A – pārstāv visus masīva elementus, piemēram: writeln (A);

35
G.Matisons - "Datu struktūras", Rīga ) matrica ir vektors, kura elementi savukārt savukārt ir vektori (array of array). Šādi masīvu var interpretēt, piemēram, valodā Pascal: const lo1 = 1; hi1 = 3; lo2 = 1; hi2 =4; type Ind1 = lo1.. hi1; Ind2 = lo2.. hi2; B = real; Matrix = array [Ind1] of array [Ind2] of B; var A: Matrix; i Masīva elements ar vienu indeksizteiksmi: A [i], i = lo1, lo1+1,..., hi1, pārstāv visus elementus kādā rindā, piemēram: A [3]:= A[1]; {masīva rindas piešķire} Mainīgais ar indeksiem A [i] [j] – pārstāv vienu noteiktu elementu, kas atrodas i – tā vektora (rindas) j –tā pozīcijā, i = lo1, lo1+1,..., hi1, j = lo2,..., hi2. Mainīgais A – pārstāv visus matricas elementus. type Ind1 = lo1.. hi1; Ind2 = lo2.. hi2; B = real; Row = array [Ind2] of B; Matrix = array [Ind1] of Row; var A: Matrix; A [3] [4]A [3] [3]A [3] [2]A [3] [1] A [2] [4]A [2] [3]A [2] [2]A [2] [1] A [1] [4]A [1] [3]A [1] [2]A [1] [1] j

36
G.Matisons - "Datu struktūras", Rīga ELEMENTA MEKLĒŠANA VEKTORĀ Bieži lietota operācija darbā ar datu struktūrām. Ir 3 meklēšanas algoritmi (metodes): 1) lineārā jeb secīgā meklēšana: const N = 500; type I = 1.. N; I1 = 0.. N; B = integer; T = array [I] of B; var A: T; k: I1; X: B;... {meklēšanas atslēga} k:= 0; repeat {elementa meklēšana} k:= k + 1 until (A[k] = X) or (k = N); if A[k] <> X then writeln ( Nesekmīga meklēšana) else writeln (k, X); Operācijas izpildes efektivitāte: 0(n) 2) lineārā meklēšana, izmantojot robežmarķiera metodi: const N = 500; type I = 1.. N + 1; I1 = 0.. N + 1; B = integer; T = array [I] of B; var A: T; k: I1; X: B;... k:= 0; A [N + 1]:= X; {robežmarķieris}
X then writeln ( Nesekmīga meklēšana) else writeln (k, X); Operācijas izpildes efektivitāte: 0(n) 2) lineārā meklēšana, izmantojot robežmarķiera metodi: const N = 500; type I = 1.. N + 1; I1 = 0.. N + 1; B = integer; T = array [I] of B; var A: T; k: I1; X: B;... k:= 0; A [N + 1]:= X; {robežmarķieris}">

N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T " title="G.Matisons - "Datu struktūras", Rīga 2003 37 repeat {elementa meklēšana} k:= k + 1 until A [k] = X; if k > N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T " class="link_thumb">
37
G.Matisons - "Datu struktūras", Rīga repeat {elementa meklēšana} k:= k + 1 until A [k] = X; if k > N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T = array [I] of B; var A: T; i, j,k: I; X : B;... i:= 1; j:= N; {meklēšanas diapazons} repeat {elementa meklēšana} k = (i + j) div 2; {viduspunkts} if X > A [K] then i:= k + 1 else j:= k -1 until (A[k] = X) or (i = j); if A[k] <> X then writeln (Nesekmīga meklēšana) else writeln (k, X); Meklēšanas operācijas efektivitate: O(log 2 N)
N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T ">
N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T = array [I] of B; var A: T; i, j,k: I; X : B;... i:= 1; j:= N; {meklēšanas diapazons} repeat {elementa meklēšana} k = (i + j) div 2; {viduspunkts} if X > A [K] then i:= k + 1 else j:= k -1 until (A[k] = X) or (i = j); if A[k] <> X then writeln (Nesekmīga meklēšana) else writeln (k, X); Meklēšanas operācijas efektivitate: O(log 2 N)">
N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T " title="G.Matisons - "Datu struktūras", Rīga 2003 37 repeat {elementa meklēšana} k:= k + 1 until A [k] = X; if k > N then writeln (Nesekmīga meklēšana) else writeln (k, X); 3) binārā meklēšana (dihotomijas metode): const N = 500; type I = 1.. N; B = real; T ">

38
G.Matisons - "Datu struktūras", Rīga DESKRIPTORS UN TĀ LIETOJUMS Fiziskai datu struktūrai, kas ir masīvs, tiek piekārtots informatīvs ieraksts, ko sauc par deskriptoru un kurā sakopotas vispārīgas ziņas par attiecīgo masīvu. Deskriptoru parasti izveido kompilators, un tas paredzēts, lai masīvu apstrādes procesā indeksizteiksmju vērtības pārveidotu fiziskas datu struktūras lauka adresēs. Deskriptors ir ieraksts, kas sastāv no laukiem, kuru skaits, garums un raksturlielumi ir atkarīgi no masīva apraksta, piemēram: var A: array [ ] of real; Vektora deskriptors: A real 6 addr (A[-3]) 1 -3 C 0 2 C 1 A[-3]A[-2] A[-1] A[0]A[1]A[2] 6 baiti

39
G.Matisons - "Datu struktūras", Rīga VEKTORA ADRESĒŠANAS FUNKCIJAS NOTEIKŠANA (Address Mapping Function, AMF) const lo =... ; hi =... ; {uzdod lietotājs} type Ind = lo.. hi; {indeksa tips} B =... ; {bāzes tips - uzdod lietotājs} var A: array [Ind] of B; Elementu skaits N = hi – lo + 1 A - vekt. nosaukums Bāzes tips B Elementa garums L Vektora sāk.adrese b Dimensiju skaits d lo C0C0 hi C1C1 A [lo] A [lo + 1]... A [i]... A [hi] ( i - l o ) * L parasti rakstzīmes parasti koda veidā vesels skaitlis adrese – vesels skaitlis vesels skaitlis, d = 1 indeksa robežvērtības L baiti b + (i - lo)* L - attālums līdz i-tajam elementam, (i-lo)*L - nobīde addr (A[i]) = b + (i - lo)* L = = (b - L * lo) + i*L = C 0 + C 1 * i C = L C 0 = b – lo*C 1 1 adresēšanas funkcijas konstantes

40
G.Matisons - "Datu struktūras", Rīga Piemēram: var A: array [3.. 7] of integer; lo = 3; hi = 7; L = 2; Pieņemsim, ka b = 500. C 1 = L = 2; C 0 = b – lo*C 1 = *2 = 494 addr (A[i]) = *i – lineāra funkcija AdreseElements A [3] A [4] A [5] A [6] A [7] addr (A [3]) = *3 = 500; addr (A [5]) = *5 = 504; addr (A [7]) = *7 = 508; DIVDIMENSIJU MASĪVA ADRESĒŠANAS FUNKCIJA const lo1 =... ;hi1 =... ; {uzdod lietotājs} lo2 =... ;hi2 =... ; type Ind1 = lo1.. hi1; {indeksu tipi} Ind2 = lo2.. hi2; B =... ; {bāzes tips - uzdod lietotājs} Matrix = array [Ind1, Ind2] of B; var A: Matrix;

41
G.Matisons - "Datu struktūras", Rīga addr (A[i, j]) = b + (i – lo 1 ) (hi 2 – lo 2 +1)*L +(j – lo 2 )*L = attālums līdz attālums i-tai rindai līdz j-ajam elementam rindā i = Co +C 1 *i + C 2 *j - divargumentu lineāra funkcija C 2 = L;C 1 = (hi 2 – lo 2 + 1)*C 2 Co = b – C 1 *lo 1 – C 2 *lo 2 Piemēram: constlo1 = 1; hi1 = 3; lo2 = 1;hi2 = 4; typeInd1 = lo1.. hi1; Ind2 = lo2.. hi2; B = real; T = array [Ind1, Ind2] of B; varA: T;

42
G.Matisons - "Datu struktūras", Rīga lo 1 = 1;hi 1 = 3; lo 2 = 1;hi 2 = 4;L = 6;b = 500; C 2 = L = 6; C 1 = (hi 2 – lo 2 +1)*C 2 = (4 – 1 + 1)*6 = 24; C 0 = b – C 1 *lo 1 – C 2 *lo 2 = 500 – 24*1 – 6*1 = 470. addr (A [i,j]) = i + 6j addr (A [1, 2]) = *1 + 6*2 = 506 addr (A [1, 1]) = *1 +6*1 = 500 addr (A [3, 1]) = *3 + 6*1 = 548 addr (A [3, 4]) = *3 + 6*4 = 566 Elementu skaits n = 12. Lauka garums = 12*6 = 72 baiti. Pēdējā elementa adrese = (72 – 6) = 566.

43
G.Matisons - "Datu struktūras", Rīga VAIRĀKDIMENSIJU MASĪVI UN TO ADRESĒŠANAS FUNKCIJAS Masīva dimensiju skaits – to praktiski ierobežo tikai datorsistēmas arhitektūra un resursi. Atmiņas apjoms un tā apstrādes laiks strauji pieaug, pieaugot dimensiju skaitam. Ja definēts masīvs ar d dimensijām un L baitiem viena elementa attēlošanai atmiņā, tad viss masīvs atmiņā aizņems L*(hi 1 – lo 1 +1)*(hi 2 – lo 2 + 1) *... *(hi d – lo d +1) baitus, piemēram: var A: array [ , , 1.. 4] of integer; L = 2; d = 3. Masīvs atmiņā aizņems apmēram baitus. Uzskatīsim, ka vispārējā gadījumā definēts šāds vairākdimensiju masīvs : var A: array [ lo 1.. hi 1,..., lo d.. hi d ] of B; Mēģināsim vispārināt adresēšanas funkcijas konstanšu C 0, C 1 un C d noteikšanas metodiku un formulas: C d = L (elementu garums baitos)... C k-1 = (hi k – lo k + 1)*C k,k = d, d -1,..., 2... C 0 = b – C 1 *lo 1 – C 2 *lo 2 -..C d * lo d addr (A [i 1, i 2,..., i d ) = C 0 + C 1 *i 1 + C 2 *i C d *i d Vairākdimensiju masīvu elementi datora atmiņā tiek izvietoti viens aiz otra tā, ka visstraujāk izmainās pēdējais indekss, bet vislēnāk – pirmais indekss.

44
G.Matisons - "Datu struktūras", Rīga Piemērs: Definēts trīsdimensiju masīvs: var A: array [1.. 2, 1.. 2, 1.. 2] of integer; N = 8; Atmiņas lauka garums ir 8*2 = 16 baiti. b = 500; L = 2; d = 3. Adresēšanas funkcijas konstantes: C 3 = L =2; C 2 = (hi 3 – lo 3 + 1)*C 3 = 2*2 = 4; C 1 = (hi 2 – lo 2 + 1)*C 2 = 2*4 = 8; C 0 = b – C 1 *lo 1 – C 2 *lo 2 – C 3 *lo 3 = 500 – 8*1 – 4*1 -2*1 = 486; Adresēšanas funkcija: addr (A [i, j, k]) = i + 4j +2k;

45
G.Matisons - "Datu struktūras", Rīga SPECIĀLIE MASĪVI UN TO LIETOJUMS Pie speciālajiem masīviem pieskaitāmi: 1) diagonālmatricas; 2) simetriskās matricas; 3) trijstūrmatricas; 4) retinātās matricas. Galvenās risināmās problēmas: 1) kā visefektīvāk speciālo masīvu attēlot datora atmiņā; 2) kā visefektīvāk organizēt piekļuvi masīva elementiem un izpildīt to meklēšanas operāciju. TRĪSDIMENSIJU MASĪVA ATTĒLOJUMS Masīva loģiskā struktūra Fiziskā struktūra addr(A[1,1,2]) = 486+8*1+4*1+2*2 = 502; addr(A[2,2,2]) = 486+8*2+4*2+2*2 = 514; addr(A[1,1,1]) = 486+8*1+4*1+2*1 = 500;

46
G.Matisons - "Datu struktūras", Rīga DIAGONĀLMATRICA (diagonal array) Galvenās diagonāles elementu skaits: N=hi-lo+1. Diagonālmatricas modeļa apraksts un meklēšanas operācija: const lo = 1; hi = 4; {uzdod lietotājs} type Ind = lo.. hi; {indeksa tips} B = integer; {matricas elementa tips} DArr = array [Ind] of B; {vektora tips} var V: DArr; function DArrFind (V: DArr; i, j: Ind): B {Diagonālmatricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} begin if i = j then DArrFind:=V[i] else DArrFind:=0 end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A[i,j] => DArrFind(V, i, j) A[i,j] = 0, A[i,i] <>0, i=lo, lo+1,..., hi j=lo, lo+1,..., hi
DArrFind(V, i, j) A[i,j] = 0, A[i,i] <>0, i=lo, lo+1,..., hi j=lo, lo+1,..., hi">

47
G.Matisons - "Datu struktūras", Rīga SIMETRISKĀ MATRICA (symmetrical array) Elementu skaits vektorā V (t.i., simetriskās matricas trijstūrmatricā): (hi – lo +1) (hi – lo +2) N = hi (hi+1) Ja lo=1, tad N = * 5 Piemērā lo = 1, hi = 4, N= = => A j V i K A[i,j] = A [j,i], i = lo, lo +1,..., hi j = lo, lo +1,..., hi
A j V i K A[i,j] = A [j,i], i = lo, lo +1,..., hi j = lo, lo +1,..., hi">

48
G.Matisons - "Datu struktūras", Rīga Simetriskās matricas modeļa apraksts un meklēšanas operācija: const lo = 1; hi = 4; {uzdod lietotājs} hk = (hi – lo +1) * (hi – lo +2) div 2; type Ind = lo.. hi; {indeksu tipi} Indk = lo.. hk; B = integer; {matricas elementa tips} SymArr = array [Indk] of B; {vektora tips} var V: SymArr; function SymArrFind (V: SymArr; i, j: Ind): B; {Simetriskās matricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} var k: Indk; begin if i >= j then k:= j + (i * i – i) div 2 else k:= i + (j * j – j) div 2; SymArrFind:= V[k] end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A [i,j] => SymArrFind (V, i, j) Pārbaude: A[1,1] i = 1, j = 1, k = 1 + ( ) / 2 = 1; A[1,2] i = 1, j = 2, k = 1+ (2 2 – 2) / 2 = / 2 = 2; A[2,1] i = 2, j = 1, k = 1 + (2 2 – 2) / 2 = / 2 = 2; A[4,4] i = 4, j = 4, k = 4 + (4 2 – 4) / 2 = /2 = 10;
= j then k:= j + (i * i – i) div 2 else k:= i + (j * j – j) div 2; SymArrFind:= V[k] end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A [i,j] => SymArrFind (V, i, j) Pārbaude: A[1,1] i = 1, j = 1, k = 1 + (1 2 - 1) / 2 = 1; A[1,2] i = 1, j = 2, k = 1+ (2 2 – 2) / 2 = 1 + 2 / 2 = 2; A[2,1] i = 2, j = 1, k = 1 + (2 2 – 2) / 2 = 1 + 2 / 2 = 2; A[4,4] i = 4, j = 4, k = 4 + (4 2 – 4) / 2 = 4 + 12/2 = 10;">

49
G.Matisons - "Datu struktūras", Rīga APAKŠĒJĀ TRIJSTŪRMATRICA (lower triangular array) (hi – lo +1) (hi – lo +2) Nesingulāro elementu skaits N = hi (hi + 1) Ja lo = 1, tad N = Apakšējās trijstūrmatricas modeļa apraksts un meklēšanas operācija: const lo = 1; hi = 4; {uzdod lietotājs} hk = (hi – lo +1) * (hi – lo +2) div 2; type Ind = lo.. hi; {indeksu tipi} Indk = lo.. hk; B = integer; {masīva elementa tips} LTArr = array [Indk] of B; {vektora tips} var V: LTArr; => A j V i k A[i,j] = 0, ja i < j, A[i,j] <>0, ja i >= j, i=lo, lo+1,..., hi j=lo, lo+1,..., hi
A j V i k A[i,j] = 0, ja i < j, A[i,j] <>0, ja i >= j, i=lo, lo+1,..., hi j=lo, lo+1,..., hi">

= j then begin k:= i * (i – 1) div 2 + j" title="G.Matisons - "Datu struktūras", Rīga 2003 50 function LTArrFind (V: LTArr; i, j: Ind): B; {Apakšējās tristūrmatricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} var k: Indk; begin if i >= j then begin k:= i * (i – 1) div 2 + j" class="link_thumb">
50
G.Matisons - "Datu struktūras", Rīga function LTArrFind (V: LTArr; i, j: Ind): B; {Apakšējās tristūrmatricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} var k: Indk; begin if i >= j then begin k:= i * (i – 1) div 2 + j; LTArrFind:= V[k] end else LTArrFind:= 0 end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A[i, j] => LTArrFind (V, i, j) Pārbaude: A[1,1] i = 1, j = 1, A[3, 2] i = 3, j = 2, A[3, 3] i = 3, j = 3, A[4, 4] i = 4, j = 4, 1 = 1 ; 2 1*(1-1) + k5 ;5 ;2 2 2*3 + k 6 ; 3 2 2*3 =+ k 10 ; 4 2 3*4 =+= k
= j then begin k:= i * (i – 1) div 2 + j">
= j then begin k:= i * (i – 1) div 2 + j; LTArrFind:= V[k] end else LTArrFind:= 0 end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A[i, j] => LTArrFind (V, i, j) Pārbaude: A[1,1] i = 1, j = 1, A[3, 2] i = 3, j = 2, A[3, 3] i = 3, j = 3, A[4, 4] i = 4, j = 4, 1 = 1 ; 2 1*(1-1) + k5 ;5 ;2 2 2*3 + k 6 ; 3 2 2*3 =+ k 10 ; 4 2 3*4 =+= k">
= j then begin k:= i * (i – 1) div 2 + j" title="G.Matisons - "Datu struktūras", Rīga 2003 50 function LTArrFind (V: LTArr; i, j: Ind): B; {Apakšējās tristūrmatricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} var k: Indk; begin if i >= j then begin k:= i * (i – 1) div 2 + j">

51
G.Matisons - "Datu struktūras", Rīga Nesingulāro elementu skaits: Ja lo = 1, tad Augšējās trijstūrmatricas modeļa apraksts un meklēšanas operācija: const lo = 1; hi = 4; {uzdod lietotājs} hk = (hi – lo +1) * (hi – lo +2) div 2; type Ind = lo.. hi; Indk = lo.. hk; {indeksu tipi} B = integer; {matricas elementa tips} UTArr = array [Indk] of B; {vektora tips} var V: UTArr; AUGŠĒJĀ TRIJSTŪRMATRICA (upper triangular array) => A j V i K A[i,j] = 0, ja i > j, A[i,j] <> 0, ja i <= j 2 (hi-lo+1) (hi-lo+2) N= 2 hi (hi+1) N
A j V i K A[i,j] = 0, ja i > j, A[i,j] <> 0, ja i <= j 2 (hi-lo+1) (hi-lo+2) N= 2 hi (hi+1) N">

52
G.Matisons - "Datu struktūras", Rīga function UTArrFind (V: UTArr; i, j: Ind): B; {Augšējās trijstūrmatricas A elementa meklēšana vektorā V, izmantojot indeksu i un j vērtības} var k: Indk; begin if i <= j then begin k:= ((2 * hi – i + 1) * i) div 2 – hi + j; UTArrFind:= V[k] end else UTArrFind:= 0 end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A[i, j] => UTArrFind (V, i, j) Pārbaude: A[1,1], i = 1, j = 1; k = ((2*4 -1+1) *1) / = = 1 A[1,2], i = 1, j = 2; k = ((2*4 -1+1) *1) / = = 2 A[2,2], i = 2, j = 2; k = ((2*4 -2+1) *2) / = = 5 A[3,4], i = 3, j = 4; k = ((2*4 -3+1) *3) / = = 9
UTArrFind (V, i, j) Pārbaude: A[1,1], i = 1, j = 1; k = ((2*4 -1+1) *1) /2 - 4 + 1 = 4 - 4 + 1 = 1 A[1,2], i = 1, j = 2; k = ((2*4 -1+1) *1) /2 - 4 + 2 = 4 - 4 + 2 = 2 A[2,2], i = 2, j = 2; k = ((2*4 -2+1) *2) /2 - 4 + 2 = 7 - 4 + 2 = 5 A[3,4], i = 3, j = 4; k = ((2*4 -3+1) *3) /2 - 4 + 4 = 9 - 4 + 4 = 9">

53
G.Matisons - "Datu struktūras", Rīga RETINĀTĀS MATRICAS (sparse arrays) Masīvu, kurā vairums elementu ir vienādi ar kādu singulāru vērtību, (piemēram, ar nulli), sauc par retinātu matricu. Tikai dažas vērtības ir nesingulāras, un tās matricā izvietotas nevienmērīgi. Ja definēta retināta matrica: var A: array [1.. hi1, 1.. hi2] of integer; un Nz elementi nav vienādi ar 0 (Nz = 1,2,...), tad pārējie singulārie elementi atmiņā aizņemtu (hi1 * hi2 – Nz) * L baitus, ja izmanto parasto masīva elementu izvietošanas paņēmienu datora atmiņā. Piemērs: No 42 elementiem tikai Nz = 10 nav vienādi ar 0. Viens no paņēmieniem, kā glabāt retināto matricu atmiņā, ir izveidot ierakstu vektoru. Katrs vektora elements satur nesingulāro vērtību val un tai atbilstošo indeksu i un j vērtības A j = 1..7 i = 1..6

54
G.Matisons - "Datu struktūras", Rīga Retinātās matricas modeļā apraksta un meklēšanas operācija: const NzMax = 20; {uzdod lietotājs} lo1 = 1; hi1 = 6; lo2 = 1; hi2 = 7; type Ind1 = lo1.. hi1; Ind2 = lo2.. hi2; {matricas indeksu tipi} NzRange = 0.. NzMax; {vektora indeksa tips} B = integer; {matricas elementa tips} Condensed = array [NzRange] of record val: B; i: Ind1; j: Ind2 end; var V: Condensed; {ierakstu vektors} jival Vektora indekss Nz= 10; V K = 1.. Nz

55
G.Matisons - "Datu struktūras", Rīga function SparseFind (V: Condensed; i: Ind1; j: Ind2): B; {Retinātas matricas elementa A[i,j] meklēšana vektorā V} var k: NzRange; begin k:= 0; repeat k:= k + 1 until ((V[k]. i = i) and (V[k]. j = j)) or (k = NzMax); if ((V[k]. i = i) and (V[k]. j = j)) then SparseFind:= V[k].val else SparseFind:= 0 end; Masīva elementa A[i,j] vietā lieto funkcijas izsaukumu: A[i,j] => SparseFind (V, i, j) Piekļuve: Matricas elementu gadījumpiekļuves vietā notiek elementa meklēšana ierakstu vektorā. Vidēji nepieciešamas (Nz + 1) / 2 caurskates sekmīgas meklēšanas gadījumā. Trūkumi: 1) iepriekš jāuzdod NzMax vērtība, kas katras retinātas matricas gadījumā ir atšķirīga un grūti prognozējama; 2) retinātas matricas attēlojuma modelis faktiski ir tabula ar 3 vērtībām katra elementa rindā, vismaz 2 baiti nepieciešami laukiem i un j. Attēlojuma efektivitātes novērtējums: Ja lauku val, i un j garums ir L baiti (L=2), tad katrs vektora elements atmiņā aizņems 3*L baitus, un tiks ietaupīti (hi1 * hi2 - NzMax) * 3 * L baiti atmiņas. Atmiņā ietaupījums baitos vispārējā gadījumā: (hi1 * hi2 – NzMax * (2 * L1 + L2), kur L1 – lauku i un j garums, L2 – lauka val garums
SparseFind (V, i, j) Piekļuve: Matricas elementu gadījumpiekļuves vietā notiek elementa meklēšana ierakstu vektorā. Vidēji nepieciešamas (Nz + 1) / 2 caurskates sekmīgas meklēšanas gadījumā. Trūkumi: 1) iepriekš jāuzdod NzMax vērtība, kas katras retinātas matricas gadījumā ir atšķirīga un grūti prognozējama; 2) retinātas matricas attēlojuma modelis faktiski ir tabula ar 3 vērtībām katra elementa rindā, vismaz 2 baiti nepieciešami laukiem i un j. Attēlojuma efektivitātes novērtējums: Ja lauku val, i un j garums ir L baiti (L=2), tad katrs vektora elements atmiņā aizņems 3*L baitus, un tiks ietaupīti (hi1 * hi2 - NzMax) * 3 * L baiti atmiņas. Atmiņā ietaupījums baitos vispārējā gadījumā: (hi1 * hi2 – NzMax * (2 * L1 + L2), kur L1 – lauku i un j garums, L2 – lauka val garums">

56
G.Matisons - "Datu struktūras", Rīga paņēmiens: Retinātās matricas attēlojuma modeli veido trīs atsevišķi vektori. Vektorā i tiek attēlots pirmās nesingulārās vērtības kārtas numurs katrā rindā, skaitot pa rindām uz priekšu, vektorā j – katras nesingulārās vērtības val kolonnas indekss rindā i, vektorā val – retinātās matricas nesingulārās vērtības. Retinātajā matricā ir 5 rindas ar nesingulāriem elementiem

57
G.Matisons - "Datu struktūras", Rīga IERAKSTA (record) JĒDZIENS Ieraksts ir nehomogēna datu struktūra, kurā sakopoti dažāda tipa un dažāda garuma dati. Atsevišķu ieraksta lauku sauc par ieraksta komponenti. Datu tips ir jāuzdod katrai ieraksta komponentei, datu tips var būt jebkurš - skalārs vai strukturēts. Visās mūsdienu modernajās programmēšanas valodās ir līdzekļi ierakstu definēšanai, piemēram: 1) type Name = string[30]; computer = record System: Name; Manufacturer: Name; Speed: ; WordSize: ; Serial_ports: ; Parallel_ports: end; 2) type Complex = record Re, Im: real end; 3) type Date = record Day: ; Month: ; Year: end; work = record id: string [20]; start: Date; stop: Date end;

58
G.Matisons - "Datu struktūras", Rīga Ieraksta lauki var būt izvietoti vairākos hierarhijas līmeņos. Lai organizētu piekļuvi ieraksta laukiem, lieto selektoru – saliktu nosaukumu, kurā ieraksta mainīgo un atsevišķas komponentes nosaukumu atdala ar punktu. Katram hierarhijas līmenim jāparedz punkts un lauka nosaukums. Piemēram: var Q: work; Saliktie nosaukumi: Q.id – piekļuve darba nosaukumam, Q.start.Year – piekļuve darba uzsākšanas gadam, Q.stop.Day – piekļuve darba pabeigšanas dienai. writeln(Q.id, Q.start.Year, Q.stop.Day); Ieraksta lauku apstrādei plaši lieto operatoru with, piemēram: with Q do writeln(id, start.Year, stop.Day);

59
G.Matisons - "Datu struktūras", Rīga Ieraksts ir lineāra datu struktūra. Ir 3 pamatoperācijas darbā ar ierakstiem, pie kam trešā operācija arī realizējama, izmantojot pirmās divas: type T1 = real;.... TN = string; Rec = record S1: T1;... SN: TN end; var P, Q: Rec; V: T1;... 1) V:= Q.S1; {ieraksta lauka izguves operācija Retrieve} 2) Q.S1:= 3.5 * V – exp (V + 1); {labošanas operācija Update} tipam T1 atbilstoša izteiksme 3) P:= Q; {ieraksta kopēšanas operācija Copy} Vispārējā gadījumā ieraksta struktūra ir šāda: Kā pamatdaļa, tā arī variantdaļa nav obligāta, katru no tām var arī izlaist. ieraksta pamatdaļa ieraksta variantdaļa

60
G.Matisons - "Datu struktūras", Rīga Ieraksta tipa apraksta sintakse vispārējā gadījumā: type T = record pamatdaļa variantdaļas virsraksts variantdaļa end; var Q: T; S i, i = 1, 2,..., n-1-- lauka nosaukums vai nosaukumu saraksts, T i, i = 1, 2,..., n-1-- ieraksta lauka datu tips, jebkurš, S n – variantdaļas selektora nosaukums, T n – variantdaļas selektora datu tips, par to var būt tikai skalārs ordināls tips, C j, j = 1, 2,..., m -- ieraksta laukam V j atbilstoša konstante vai konstanšu saraksts, V j – ieraksta lauka nosaukums vai lauka nosaukumu saraksts, R j – ieraksta lauka V j datu tips, jebkurš. S 1: T 1 ; S 2: T 2 ;... S n-1: T n-1 ; case S n : T n of C 1: (V 1 : R 1 ); C 2: (V 2 : R 2 );... C m: (V m : R m )

61
G.Matisons - "Datu struktūras", Rīga Piemēram: 1) type StateType = (solid, liquid, gas); Substance = record pamatdaļa variantdaļa end var S: Substance; 2) type Figura = (TA, TR, RI); GeomFig = record case Veids: Figura of TA: (Platums, Augstums: real); TR: (Mala1, Mala2, Lenkis: real); RI: (Radiuss: real) end; function Laukums (Fig: GeomFig): real; {Ģeometrisku figūru laukumu aprēķināšana} begin with Fig do case Veids of TA: Laukums:= Platums * Augstums; TR: Laukums:= 0.5 * Mala1* Mala2 * sin(Lenkis); RI: Laukums:= PI * sqr(Radiuss) end end; Name: string [20]; Number: integer; case state: StateType of solid: (hardness: real); liquid: (boil, freeze: real); gas: ()

62
G.Matisons - "Datu struktūras", Rīga ) type CoordMode = (cartesian, polar); Coordinate = record case Kind: CoordMode of cartesian: (X, Y: real); polar: (R, Phi:real) end; Noteikumi, veidojot ieraksta tipa aprakstu: 1) lauku nosaukumiem jābūt atšķirīgiem, pat tad, ja tie sastopami dažādos variantos; 2) tukšu variantdaļas lauku uzdod formā konstante: (); 3) katrā ierakstā var uzdot tikai vienu variantdaļu, kura savukārt var saturēt citu variantdaļu; 4) varianta selektoram jādefinē tikai skalārs ordināls tips; 5) variantdaļā nedrīkst definēt file tipa laukus; 6) ieraksta variantdaļas lauki programmā apstrādei būs pieejami tikai tad, ja programmā iepriekš variantdaļas selektoram tiek piešķirta vērtība; 7) katram selektora vērtības gadījumam jāparedz savs lauks vai to saraksts ieraksta variantdaļā, citādi izpildes procesā iespējamas kļūdas.

63
G.Matisons - "Datu struktūras", Rīga IERAKSTA LAUKU ADRESĒŠANA UN PIEKĻUVE Jābūt mehānismam, kas programmā lietotos ieraksta lauku saliktos nosaukumus pārveido reālās atmiņas adresēs. Šim nolūkam kompilators katram programmā lietotam ierakstam piekārto speciāli izveidotu nobīžu sarakstu (offset list). Tajā katrai ieraksta komponentei tiek fiksēti 4 raksturlielumi: 1) ieraksta lauka nosaukums; 2) ieraksta lauka tips; 3) ieraksta lauka tipam atbilstošs garums; 4) ieraksta lauka nobīde (baitos) attiecībā pret ieraksta sākumadresi b datora pamatatmiņā. Nobīdes vērtības aprēķina kompilātors. Sākumadrese b ir zināma, kad programmu ielādē atmiņā izpildei. Ieraksta lauka nobīdes vērtība nemainās, mainoties ieraksta sākumadresei b. Ieraksta lauka adrese b c ir nosakāma šādi: b c = b + O c, kur O c – ieraksta lauka nobīde. Kāda ieraksta lauka nobīdes O c vērtību aprēķina šādi: Q c = l 1 + l l c-1 t.i., sasummējot visu ierakstu lauku garumus ceļā no sākumadreses b līdz ieraksta laukam ar kārtas numuru c.

64
G.Matisons - "Datu struktūras", Rīga Piemēram: type Date = record Day = 1..31; Month = 1..12; Year = end; work = record id: string [20]; start: Date; stop: Date; end; var Q: work; Nobīžu tabula: NosaukumsTipsGar.Nob. Q.id Q.start Q.start.Day Q.start.Month Q.start.Year Q.stop Q.stop.Day Q.stop.Month Q.stop.Year string[20] Date integer Date integer id startDay Month Year stopDay Month Year

65
G.Matisons - "Datu struktūras", Rīga MASĪVU IERAKSTI (records of arrays) Masīvi var būt ieraksta lauki dažādos hierarhijas līmeņos. Masīvu ieraksti pieder pie saliktajām struktūrām. Piemērā dots ieraksts, kuru izmanto, lai fiksētu informāciju par noteiktu notikumu, kas var notikt 20 dažādās vietās un 15 dažādos datumos katrā vietā: type RA = record event: string [30]; place: array [1.. 20] of record placeName: string [20]; date: array [1..15] of record dy: ; mo: ; yr: end end; var Q: RA; i = 1, 2,..., 20, j = 1, 2,..., 15. Saliktie nosaukumi: Q.place[i].date[j].mo – uzdod notikumu Q.event i-tās vietas j-tajā datumā. Q.place[i].placeName – uzdod i-tā notikuma vietu.

66
G.Matisons - "Datu struktūras", Rīga IERAKSTU MASĪVI JEB TABULAS (arrays of records or tables) Viendimensijas ierakstu masīvi ir plaši lietota datu struktūra, ko sauc arī par tabulu, un kuru izmanto, lai sakopotu informāciju par objektiem vai personām, kas pieder pie vienas grupas. Ierakstu masīvs pieskaitāms pie saliktajām datu struktūrām. Piemērā dota tabula, kurā sakopota informācija par studentiem grupā: const N = 25; type text1 = string [20]; text2 = string [30]; text3 = string [50]; Studenti = array [1.. N] of record Nr: 1..N; Vards: text1; Uzv: text2; st_apl: string [11] adrese: text3; telefons: longint end; var S: Studenti; Lai organizētu piekļuvi tabulā grupas i-tā studenta ieraksta laukiem, jālieto saliktie mainīgie ar indeksiem: S[i].Nr, S[i].Vards, …, S[i].telefons, i = 1, 2, 3,..., N.

67
G.Matisons - "Datu struktūras", Rīga RĀDĪTĀJU MASĪVI UN TO LIETOJUMS 1) rādītāji uz masīva elementiem, kuriem var būt mainīgs garums. Masīva elementi tiek dinamiski izveidoti, uz katru elementu norāda savs rādītājs, visus rādītājus sakopo masīvā: headNode [1] Rīga next nil Chunk [2] Vent next spil next s next nil... [N] Liep next āja next nil const N = 100; {elementu skaits masīvā} ChunkSize = 4; {fragmenta garums, ko uzdod lietotājs} type NodePointer = ^Node; {rādītāja datu tips} Node = record {masīva elements} Chunk: array [1.. ChunkSize] of char; {fragmenta lauks} next: NodePointer {rādītāja lauks} end; var head: array [1.. N] of NodePointer; {rādītāju masīvs} 2) saraksta vai vektora elementu sasaiste ar rādītājiem, uzdodot noteiktu sasaistes likumu, piemēram, nosaukumu sasaiste alfabētiskā secībā. Pēc šāda principa veido vairākkārtīgi saistītus sarakstus. Katram sasaistes kontūram paredz savu rādītāju vektoru. Šādus vektorus sauc par datu indeksvektoriem. Ar to palīdzību ērti nodrošināt piekļuvi datiem un organizēt vajadzīgo datu sameklēšanu. Apskatīsim tabulu, kurā ir vairākas kolonnas un kurā sakopota informācija par datoriem.

68
G.Matisons - "Datu struktūras", Rīga const N = 4; {uzdod lietotājs} type Computers = array [1.. N] of record {tabulas datu tips} Company: string [20]; System: string [10];... Systype: string [5] end; Table = ^Computers; {rādītāju datu tips} var Q: Table; Manufacturer = array [1.. N] of Table; {rādītāju masīvs} Class = array [1.. N] of Table; {rādītāju masīvs} {Rādītāju iestatīšana uz kādu noteiktu tabulas elementu:} Manufacturer [1]:= addr (Q ^ [4].Company);... Class [1]:= addr (Q ^ [3].Systype); [1] DEC VAX 11/ mini [1] [2] IBM PC... micro [2] [3] IBM maxi [3] [4] Apple Macintosh... micro [4] Manufacturer Class

69
G.Matisons - "Datu struktūras", Rīga SARAKSTA (list) JĒDZIENS Saraksts ir lineāra datu struktūra, kurā, ja saraksts nav tukšs: 1) ir unikāls elements, ko sauc par pirmo; 2) ir unikāls elements, ko sauc par pēdējo; 3) visiem saraksta elementiem, izņemot, pirmo un pēdējo, ir unikāls priekštecis un pēctecis. Pirmajam elementam ir tikai pēctecis, bet pēdējam elementam ir tikai priekštecis; 4) saraksts var būt tukšs. Saraksta elementu sasaistes raksturs: viens ar vienu: Visiem saraksta elementiem ir tips StdElement, kas paredz, ka saraksta datu laukam data tiek pievienots atslēgas lauks key. Saraksta elementu atslēgām key jābūt atšķirīgām, jo tās viennozīgi identificē elementu sarakstā. Viens no elementiem sarakstā vienmēr ir tekošais (current).

70
G.Matisons - "Datu struktūras", Rīga Saraksta attēlojums: 1) vektoriālā formā, izmantojot saraksta pozicionēšanu vai hešēšanu (jaukšanu); 2) saistītā formā, visus elementus sarakstā saistot ar rādītājiem. Nesakārtotos sarakstos elementu izvietojums tajā var būt patvaļīgs. Sakārtotos sarakstos elementu izvietojums atbilst noteiktam kārtošanas kritērijam. Sakārtoti saraksti: 1) hronoloģiski sakārtoti saraksti; 2) pēc lietojuma biežuma sakārtoti saraksti. Pie tiem pieskaitāmi arī pašorganizētie saraksti; 3) sašķirotie saraksti. Tekošo elementu sarakstā iestata: 1) meklēšanas operācijas Findxxx, ja saraksts nav tukšs; 2) jauna elementa pievienošanas operācija Insert; 3) tekošā elementa dzēšanas operācija Delete. Neatkarīgi no saraksta attēlojuma modeļa, darbā ar sarakstiem paredzētas šādas operācijas: 1) apkalpošanas (servisa) operācijas: Create Terminate Size Full Empty CurPos First Last 2) meklēšanas operācijas: FindFirstFindLast FindNextFindPrior FindKeyFindith

71
G.Matisons - "Datu struktūras", Rīga ) pamatoperācijas: Insert InsertAfter InsertBefore Delete Retrieve Update VEKTORIĀLĀ FORMĀ ATTĒLOTS SARAKSTS ListInstance n current el[1] el[2]... el[current]... el[n] data L:List key Saraksta elements el[i] => StdElement : DataType : KeyType... el[MaxSize] i = 1, 2,..., n saraksts brīvās pozīcijas
StdElement : DataType : KeyType... el[MaxSize] i = 1, 2,..., n saraksts brīvās pozīcijas">

72
G.Matisons - "Datu struktūras", Rīga const MaxSize = 100; {maksimālais elementu skaits} type Position = 1.. MaxSize; {elementa pozīcijas tips} Count = 0.. MaxSize; {elementu skaita tips} Edit = 1.. 3; {labošanas variantu tips} DataType = string [20]; {datu lauka tips} KeyType = integer; {atslēgas lauka tips} StdElement = record {saraksta elementa tips} data: DataType; key: KeyType end; ListInstance = record {saraksta modeļa tips} n: Count; current: Count; el: array [Position] of StdElement end; List = ^ ListInstance; {saraksta rādītāja tips} procedure Create (var L: List; var created: boolean); {Izveido jaunu tukšu sarakstu L^} begin new(L); L^.n:= 0; L^.current:= 0; created:= true end;

73
G.Matisons - "Datu struktūras", Rīga procedure Terminate (var L: List; var created: boolean); {Likvidē sarakstu L^} begin if created then begin dispose (L); created:= false end end; function CurPos (L: List): Count; {Nosaka tekošā elementa pozīcijas numuru sarakstā L^} begin CurPos:= L^.current end; function Size (L: List): Count; {Nosaka elementu skaitu sarakstā L^} begn Size:= L^.n end; function Empty (L: List): boolean; {Pārbauda, vai saraksts L^ ir tukšs} begin Empty:= L^.n = 0 end; function Full (L: List): boolean; {Pārbauda, vai saraksts L^ ir pilns} begin Full:= L^.n = MaxSize end;

74
G.Matisons - "Datu struktūras", Rīga function First (L:List): boolean; {Pārbauda, vai pirmais elementa ir tekošais sarakstā L^} begin First:= L^.current = 1 end; function Last (L: List): boolean; {Pārbauda, vai pēdējais elementa ir tekošais sarakstā L^} begin Last:= L^.current = L^.n end; procedure FindNext (var L: List); {Sarakstā L^ meklē tekošā elementa pēcteci, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then L^.current:= L^.current + 1 end; procedure FindPrior (var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then L^.current:= L^.current -1 end; procedure FindFirst (var L: List); {Sarakstā L^ meklē pirmo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then L^.current:= 1 end;
Size(L) then L^.current:= L^.current + 1 end; procedure FindPrior (var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then L^.current:= L^.current -1 end; procedure FindFirst (var L: List); {Sarakstā L^ meklē pirmo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then L^.current:= 1 end;">

Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType;" title="G.Matisons - "Datu struktūras", Rīga 2003 75 procedure FindLast (var L:List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType;" class="link_thumb">
75
G.Matisons - "Datu struktūras", Rīga procedure FindLast (var L:List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType; var found: boolean); {Sarakstā L^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements klūst par tekošo elementu} var k: Position; done: boolean; begin found:= false; if not Empty (L) then with L^ do begin k:= 1; done:= false; while (not done) and (not found) do {meklē elementu} if tkey = el [k].key then begin {sekmīga meklēšana} current:= k; found:= true end else if k = n then done:= true else k:= k +1 end end;
Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType;">
Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType; var found: boolean); {Sarakstā L^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements klūst par tekošo elementu} var k: Position; done: boolean; begin found:= false; if not Empty (L) then with L^ do begin k:= 1; done:= false; while (not done) and (not found) do {meklē elementu} if tkey = el [k].key then begin {sekmīga meklēšana} current:= k; found:= true end else if k = n then done:= true else k:= k +1 end end;">
Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType;" title="G.Matisons - "Datu struktūras", Rīga 2003 75 procedure FindLast (var L:List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then L^.current:= L^.n end; procedure FindKey1 (var L: List; tkey: KeyType;">

76
G.Matisons - "Datu struktūras", Rīga procedure FindKey2 (var L: List; tkey: KeyType; var found: boolean); {Lineārā meklēšana, izmantojot robežmarķieri} var k: Position; begin found:= false; if not Empty (L) then with L^ do begin found:= true; el [n + 1].key:= tkey; {izvieto robežmarķieri} k:= 1; {meklē elementu} while el [k].key <> tkey do k:= k + 1; if k = n + 1 then found:= false else current:= k end end; procedure Findith (var L: List; i: Position); {Sarakstā L^ meklē elementu ar kārtas numuru i. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} begin if (not Empty(L)) and (i <= Size (L)) then L^. current:= i end;
tkey do k:= k + 1; if k = n + 1 then found:= false else current:= k end end; procedure Findith (var L: List; i: Position); {Sarakstā L^ meklē elementu ar kārtas numuru i. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} begin if (not Empty(L)) and (i <= Size (L)) then L^. current:= i end;">

77
G.Matisons - "Datu struktūras", Rīga procedure InsertAfter (var L:List; e: StdElement); {Sarakstā L^ aiz tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} var k: Position; begin if not Full (L) then with L^ do begin if not Last (L) then for k:= n downto current + 1 do el [k+1]:= el [k]; {atbrīvo vietu elementam} current:= current + 1; el [current]:= e; {izvieto elementu} n:= n + 1 end end; procedure InsertBefore (var L:List; e: StdElement); {Sarakstā L^ pirms tekošā elementā pievieno jaunu elementu e, kas kļūst par tekošo elementu} begin if not Empty(L) then L^.current:= L^.current -1; InsertAfter (L, e) end; procedure Retrieve (L: List; var e: StdElement); {Tekošā elementa izguve sarakstā L^} begin if not Empty (L) then e:= L ^. el [L ^. current] end;

78
G.Matisons - "Datu struktūras", Rīga procedure Delete (var L: List) {Sarakstā L^ dzēš tekošo elementu} var k: Position; begin if not Empty (L) then with L ^ do begin for k:= current +1 to n do {pārvieto elementus} el [k – 1]:= el [k]; if n = 1 then current:= 0 else if current = n then current:= n -1; n:= n -1 end end; procedure Update (var L: List; e: StdElement; k: Edit); {Sarakstā L^ labo tekošo elementu atbilstoši labošanas variantam k} begin if not Empty (L) then with L ^ do case k of 1: el [current].data:= e.data; 2: el [current].key:= e.key; 3: el [current]:= e end end;
79
G.Matisons - "Datu struktūras", Rīga type Node = record el: StdElement; next: NodePointer end; NodePointer = ^ Node; Saraksta elementa uzbūve: type StdElement = record data: DataType; key: KeyType end; Lai organizētu piekļuvi saistītam sarakstam, lieto šādus rādītājus: 1) L – kas norāda uz saistītā saraksta vadības struktūru; 2) head – kas vienmēr norāda uz pirmo elementu sarakstā, t.i., glabā saraksta sākumadresi; 3) current – kas norāda uz tekošo elementu sarakstā. Strādājot ar sarakstu, par tekošo var kļūt jebkurš saraksta elements. Saraksta apstrādes operācijas vienmēr tiek izpildītas attiecībā pret tekošo elementu; 4) tail – kas norāda uz pēdējo elementu sarakstā. Rādītājs tail nav obligāts, bez tā var iztikt, tomēr tā lietojums piekļuvi sarakstam padara ērtāku. Ja rādītāju tail nelieto, tad par saistīta saraksta beigu pazīmi izmanto pēdējā elementa rādītāja lauku next vērtību nil. Katram elementam sarakstā atbilst noteikts kārtas numurs, kas glabājas laukā icurrent. Informācija par elementu skaitu sarakstā glabājas laukā n. : StdElement : NodePointer VIENKĀRŠSAISTĪTS SARAKSTS Veidojot vienkāršsaistītu sarakstu, katram saraksta elementam papildus pievieno rādītāja lauku next, kurā glabājas nākamā elementa adrese: data key StdElement : DataType : KeyType el => el next Node
el next Node">

80
G.Matisons - "Datu struktūras", Rīga Rādītāju current iestata operācijas: 1) FindPrior, FindNext, FindFirst, FindLast, Findkey, Findith; 2) Insert; 3) Delete. Pirmā un pēdējā elementa sameklēšana sarakstā: current:= head; icurrent:= 1; current:= tail; icurrent:= n; Saraksta pēdējā elementa sameklēšana, ja rādītāju tail nelieto: while current^: next <> nil do current:= current^.next; Par tekošo kļūst nākamais elements: current:= current^.next; icurrent:= icurrent+1; Saraksta vadības struktūras lauku identifikācija un piekļuve: L ^. current, L ^. icurrent, L ^. n L ^. head, L ^. tail vai Saraksta tekošā elementa lauku identifikācija un piekļuve: current ^. el - elementa informatīvā lauka piekļuve, current ^. el. data - datu lauka piekļuve, current ^. el. key - atslēgas lauka piekļuve, current ^. next – rādītaja lauka piekļuve, current:= current^. next - rādītāja pārcelšana uz nākamo elementu, current:= current^. next ^. next – rādītāja pārcelšana uz aiznākamo elementu. el nex t nil
nil do current:= current^.next; Par tekošo kļūst nākamais elements: current:= current^.next; icurrent:= icurrent+1; Saraksta vadības struktūras lauku identifikācija un piekļuve: L ^. current, L ^. icurrent, L ^. n L ^. head, L ^. tail vai Saraksta tekošā elementa lauku identifikācija un piekļuve: current ^. el - elementa informatīvā lauka piekļuve, current ^. el. data - datu lauka piekļuve, current ^. el. key - atslēgas lauka piekļuve, current ^. next – rādītaja lauka piekļuve, current:= current^. next - rādītāja pārcelšana uz nākamo elementu, current:= current^. next ^. next – rādītāja pārcelšana uz aiznākamo elementu. el nex t nil">

81
G.Matisons - "Datu struktūras", Rīga const MaxSize = 100; type Count = 0.. MaxSize; DataType = string; KeyType = integer; Edit = 1.. 3; StdElement = record {datu lauki} data: DataType; key: KeyType end; Node = record {saraksta elements} el: StdElement; next: NodePointer end; NodePointer = ^ Node; {rādītāja tips} List = ^ ListInstance; ListInstance = record head, current: NodePointer; icurrent, n: Count end; VIENKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA

82
G.Matisons - "Datu struktūras", Rīga procedure Create (var L: List; var created: boolean); {Izveido jaunu tukšu sarakstu L^} begin new (L); with L^ do begin head:= nil; current:= nil; icurrent:= 0; n:= 0 end; created:= true end; procedure Terminate (var L: List; var created: boolean); {Likvidē sarakstu L^} var p: NodePointer; begin if created then begin if not Empty (L) then with L ^ do begin current:= head; {FindFirst (L);} repeat p:= current; current:= current ^. next; dispose (p); until current = nil end; dispose (L); created:= false end end; function Size (L: List): Count; {Nosaka elementu skaitu sarakstā L^} begin Size:= L^.n end;

83
G.Matisons - "Datu struktūras", Rīga function CurPos (L: List): Count; {Nosaka tekošā elementa kārtas numuru sarakstā L^} begin CurPos:= L^.icurrent end; function Empty (L: List): boolean; {Pārbauda, vai saraksts L^ ir tukšs} begin Empty:= L^.n = 0 end; function Full (L: List): boolean; {Pārbauda, vai saraksts L^ ir pilns} begin Full:= L^.n = MaxSize end; function First (L: List): boolean; {Pārbauda, vai pirmais elements ir tekošais sarakstā L^} begin First:= L^.icurrent = 1 end; function Last (L: List): boolean; {Pārbauda, vai pēdējais elements ir tekošais sarakstā L^} begin Last:= L^.icurrent = L^.n {Last:= L^.current^.next = nil} end;

1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (va" title="G.Matisons - "Datu struktūras", Rīga 2003 84 procedure FindFirst (var L: List); {Sarakstā L^ meklē pirmo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (va" class="link_thumb">
84
G.Matisons - "Datu struktūras", Rīga procedure FindFirst (var L: List); {Sarakstā L^ meklē pirmo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (var L: List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if CurPos (L) <> Size (L) then with L^ do begin while current^.next <> nil do {while not Last(L)} current:= current^.next; {FindNext (L)} icurrent:= n end end; procedure FindNext (var L: List); {Sarakstā L^ meklē tekošā elementa pēcteci, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then with L^ do begin current:= current^.next icurrent:= icurrent + 1 end end;
1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (va">
1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (var L: List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if CurPos (L) <> Size (L) then with L^ do begin while current^.next <> nil do {while not Last(L)} current:= current^.next; {FindNext (L)} icurrent:= n end end; procedure FindNext (var L: List); {Sarakstā L^ meklē tekošā elementa pēcteci, kas kļūst par tekošo elementu} begin if CurPos(L) <> Size(L) then with L^ do begin current:= current^.next icurrent:= icurrent + 1 end end;">
1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (va" title="G.Matisons - "Datu struktūras", Rīga 2003 84 procedure FindFirst (var L: List); {Sarakstā L^ meklē pirmo elementu, kas kļūst par tekošo elementu} begin if CurPos(L) > 1 then with L^ do begin curent:= head; icurrent:= 1 end end; procedure FindLast (va">

1 then with L^ do begin p:= head; q:= nil; while " title="G.Matisons - "Datu struktūras", Rīga 2003 85 procedure FindPrior(var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if CurPos(L) > 1 then with L^ do begin p:= head; q:= nil; while " class="link_thumb">
85
G.Matisons - "Datu struktūras", Rīga procedure FindPrior(var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if CurPos(L) > 1 then with L^ do begin p:= head; q:= nil; while p <> current do {meklē priekšteci} begin q:= p; p:= p^.next end; current:= q; icurrent:= icurrent -1 end end;
1 then with L^ do begin p:= head; q:= nil; while ">
1 then with L^ do begin p:= head; q:= nil; while p <> current do {meklē priekšteci} begin q:= p; p:= p^.next end; current:= q; icurrent:= icurrent -1 end end;">
1 then with L^ do begin p:= head; q:= nil; while " title="G.Matisons - "Datu struktūras", Rīga 2003 85 procedure FindPrior(var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if CurPos(L) > 1 then with L^ do begin p:= head; q:= nil; while ">

86
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var L: List; tkey: KeyType; var found: boolean); {Sarakstā L^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements klūst par tekošo elementu} var p: NodePointer; k: Count; begin found:= false; if not Empty(L) then with L^ do begin p:= head; k:= 1; while (p^.next <> nil) and (p^.el.key <> tkey) do begin {meklē elementu} p:= p^.next; k:= k + 1 end; if p^.el.key = tkey then begin {sekmīga meklēšana} current:= p; icurrent:= k; found:= true end end;
nil) and (p^.el.key <> tkey) do begin {meklē elementu} p:= p^.next; k:= k + 1 end; if p^.el.key = tkey then begin {sekmīga meklēšana} current:= p; icurrent:= k; found:= true end end;">

87
G.Matisons - "Datu struktūras", Rīga procedure FindIth (var L: List; i: Count); {Sarakstā L^ meklē elementu ar kārtas numuru i. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} begin if (not Empty(L)) and (i <= Size(L)) then with L^ do begin current:= head; icurrent:= 1; {FindFirst(L);} while i <> icurrent do begin current:= current^.next; {FindNext(L);} icurrent:= icurent + 1 end end; procedure Retrieve (L: List; var e: StdElement); {Tekošā elementa izguve sarakstā L^} begin if not Empty(L) then with L^ do e:= current^.el end; procedure Update(var L: List; k: Edit; e: StdElement); {Sarakstā L^ labo tekošo elementu atbilstoši labošanas variantam k} begin if not Empty(L) then with L^ do case k of 1: current^el.data:= e.data; 2: current^.el.key:= e.key; 3: current^.el:= e end end;
icurrent do begin current:= current^.next; {FindNext(L);} icurrent:= icurent + 1 end end; procedure Retrieve (L: List; var e: StdElement); {Tekošā elementa izguve sarakstā L^} begin if not Empty(L) then with L^ do e:= current^.el end; procedure Update(var L: List; k: Edit; e: StdElement); {Sarakstā L^ labo tekošo elementu atbilstoši labošanas variantam k} begin if not Empty(L) then with L^ do case k of 1: current^el.data:= e.data; 2: current^.el.key:= e.key; 3: current^.el:= e end end;">

88
G.Matisons - "Datu struktūras", Rīga procedure Insert (var L: List; e: StdElement); {Sarakstā L^ aiz tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do begin new(p); p^.el:= e; if Empty(L) then {saraksts ir tukšs} begin head:= p; p^.next:= nil end else {saraksts nav tukšs} begin {izkārto 2 saites} p^.next:= current^.next; current^.next:= p end; current:= p; icurrent:= icurrent + 1; n:= n + 1 end end;

89
G.Matisons - "Datu struktūras", Rīga new(p); p^.el:= e; head:= p; p^.next:= nil; Elementu dinamiski izveido: next n... 1 head if not Empty(L) then 1) p^.next := current^.next; 2) current^.next := p; current:=p; current next e p nil
; p^.el:= e; head:= p; p^.next:= nil; Elementu dinamiski izveido: next 2 1 2 3n... 1 head if not Empty(L) then 1) p^.next := current^.next; 2) current^.next := p; current:=p; current next e p nil")
90
G.Matisons - "Datu struktūras", Rīga procedure Delete (var L: List); {Sarakstā L^ dzēš tekošo elementu un vairumā gadījumu iepriekšējais elements kļūst par tekošo elementu} var p, q: NodePointer; begin if not Empty(L) then with L^ do begin p:= head; q:= nil; while p <> current do {meklē priekšteci} begin q:= p; p:= p^.next end; if q = nil then { dzēš 1. elementu} begin head:= current^.next; q:= head; if n = 1 then icurrent:= 0 end else {dzēš elementu, kas nav pirmais} begin q^.next:= current^.next; icurrent:= icurrent -1 end; dispose(current); current:= q; n:= n -1 end end;
current do {meklē priekšteci} begin q:= p; p:= p^.next end; if q = nil then { dzēš 1. elementu} begin head:= current^.next; q:= head; if n = 1 then icurrent:= 0 end else {dzēš elementu, kas nav pirmais} begin q^.next:= current^.next; icurrent:= icurrent -1 end; dispose(current); current:= q; n:= n -1 end end;">

1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent" title="G.Matisons - "Datu struktūras", Rīga 2003 91 el next p 1 head current nilIf (q = nil) and (n = 1) then icurrent:= 0; 2 23n... 1 head if (n > 1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent" class="link_thumb">
91
G.Matisons - "Datu struktūras", Rīga el next p 1 head current nilIf (q = nil) and (n = 1) then icurrent:= 0; 2 23n... 1 head if (n > 1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent := icurrent - 1; 3 e next p 1 head current q = nil head if q = nil then Node q 2 nil n head := current^.next q := head;... 1
1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent">
1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent := icurrent - 1; 3 e next p 1 head current q = nil head if q = nil then Node q 2 nil n head := current^.next q := head;... 1">
1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent" title="G.Matisons - "Datu struktūras", Rīga 2003 91 el next p 1 head current nilIf (q = nil) and (n = 1) then icurrent:= 0; 2 23n... 1 head if (n > 1) and (current <> head) then current next el current qp nil q^.next := current^.next; current := q; icurrent">
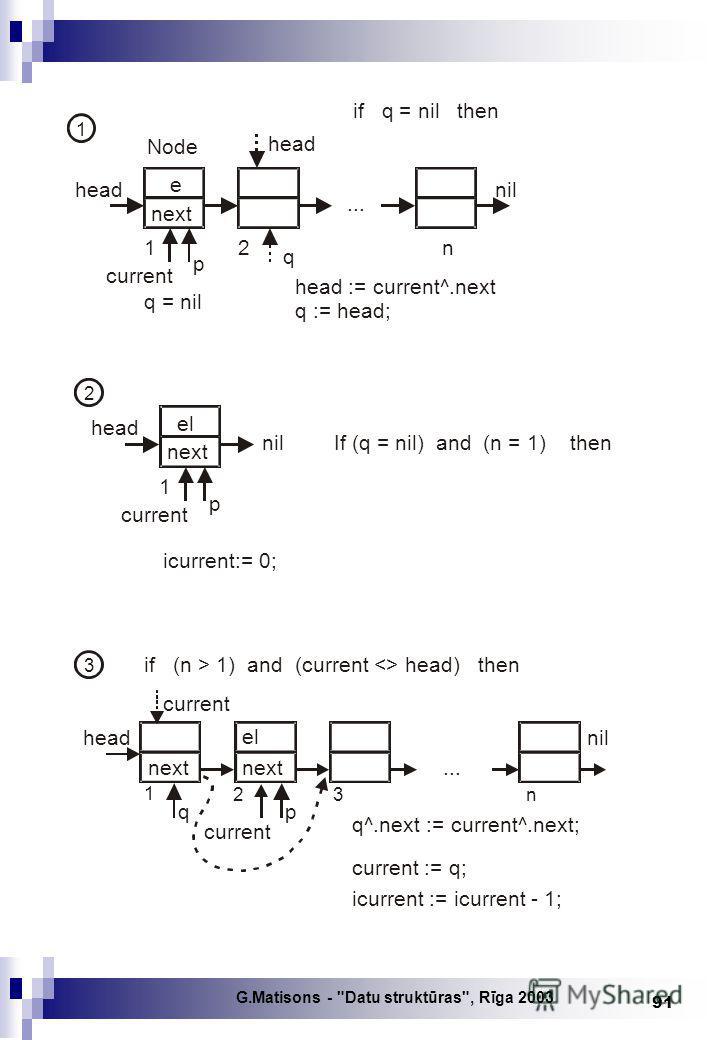
92
G.Matisons - "Datu struktūras", Rīga VIENKĀRŠSAISTĪTS SARAKSTS AR BEIGU RĀDĪTĀJU... List = ^ListInstance; ListInstance = record head: NodePointer; current: NodePointer; tail: NodePointer; icurrent: Count; n: Count; end; Salīdzinājumā ar vienkāršsaistītu sarakstu bez beigu rādītāja, atšķirības būs šādās operācijās: Create tail:= nil; Last Last:= L^.current = L^.tail; FindLast L^.current:= L^.tail; Insert Delete head tail el next Node el next 21 L: List n... nil current n ListInstance el next el next icurrent

93
G.Matisons - "Datu struktūras", Rīga procedure Create (var L: List; var created: boolean); {Izveido jaunu tukšu sarakstu L^} begin new(L); with L^ do begin current:= nil; head:= nil; tail:= nil; icurrent:= 0; n:= 0 end; created:= true end; procedure FindLast (var L: List); {Sarakstā L^ meklē pēdējo elementu, kas kļūst par tekošo elementu} begin if Size(L) <> CurPos (L) then with L^ do begin current:= tail; icurrent:= n end end; function Last(L: List): boolean; {Pārbauda, vai pēdējais elements ir tekošais sarakstā L^} begin Last::= L^.current = L^.tail end;
CurPos (L) then with L^ do begin current:= tail; icurrent:= n end end; function Last(L: List): boolean; {Pārbauda, vai pēdējais elements ir tekošais sarakstā L^} begin Last::= L^.current = L^.tail end;">

94
G.Matisons - "Datu struktūras", Rīga procedure Insert (var L: List; e: StdElement); {Sarakstā L^ aiz tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do begin new (p); p^.el:= e; if Empty(L) then {saraksts ir tukšs} begin head:= p; tail:= p; p^.next:= nil end else {saraksta nav tukšs} begin {izkārto divas saites} p^.next:= current^.next; current^.next:= p; if Last(L) then tail:= p end; current:= p; icurrent:= icurrent + 1; n:= n + 1 end end;

95
G.Matisons - "Datu struktūras", Rīga procedure Delete (var L: List); {Sarakstā L^ dzēš tekošo elementu un vairumā gadījumu iepriekšējais elements kļūst par tekošo elementu} var p, q: NodePointer; begin if not Empty(L) then with L^ do begin p:= head; q:= nil; while p <> current do {meklē priekšteci} begin q:= p; p:= p^.next end; if q = nil then {jādzēš 1. elements} begin head:= current^.next; q:= head; if n = 1 then begin icurrent:= 0; tail:= nil end else {jādzēš elements, kas nav pirmais} begin q^.next:= current^.next; {pārkārto saiti} icurrent:= icurrent – 1 end; if Last(L) then tail:= q; dispose (p); current:= q; n:= n – 1 end end;
current do {meklē priekšteci} begin q:= p; p:= p^.next end; if q = nil then {jādzēš 1. elements} begin head:= current^.next; q:= head; if n = 1 then begin icurrent:= 0; tail:= nil end else {jādzēš elements, kas nav pirmais} begin q^.next:= current^.next; {pārkārto saiti} icurrent:= icurrent – 1 end; if Last(L) then tail:= q; dispose (p); current:= q; n:= n – 1 end end;">

96
G.Matisons - "Datu struktūras", Rīga DIVKĀRŠSAISTĪTS SARAKSTS current- tekošā elementa rādītājs current:= current^.next; - rādītāju iestata uz nākamo elementu current:=current^.prior; - rādītāju iestata uz iepriekšējo elementu current^.next - norāde uz nākamo elementu current^.next^.prior - norāde uz tekošā elementa lauku prior current^.prior^.next - norāde uz tekošā elementa lauku next current^.prior - norāde uz iepriekšējo elementu current^.next^.next - norāde uz aiznākamo elementu current^.prior^.prior - norāde uz iepriekšiepriekšējo elementu i = 2, 3,..., n-1 Saraksta elementu uzbūve: Saraksta elementu sasaiste: prior : NodePointer el Node next : StdElement : NodePointer prior el next iepr.el. prior el next tek. el. prior el next nāk.el. i -1 i +1i current

current:= current^.prior; ic" title="G.Matisons - "Datu struktūras", Rīga 2003 97... Node = record el: StdElement; next: NodePointer; prior: NodePointer end; NodePointer = ^Node;... Tekošā elementa priekšteča meklēšana ir kļuvusi vienkāršāka: FindPrior(L) => current:= current^.prior; ic" class="link_thumb">
97
G.Matisons - "Datu struktūras", Rīga Node = record el: StdElement; next: NodePointer; prior: NodePointer end; NodePointer = ^Node;... Tekošā elementa priekšteča meklēšana ir kļuvusi vienkāršāka: FindPrior(L) => current:= current^.prior; icurrent:= icurrent – 1; No vienkāršsaistīta saraksta atšķiras tikai šādas piecas operācijas: FindPrior, Findith InsertAfter, InsertBefore Delete DIVKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA head icurrent nil prior el next Node prior el next 21 L: List n... nil current n ListInstance
current:= current^.prior; ic">
current:= current^.prior; icurrent:= icurrent – 1; No vienkāršsaistīta saraksta atšķiras tikai šādas piecas operācijas: FindPrior, Findith InsertAfter, InsertBefore Delete DIVKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA head icurrent nil prior el next Node prior el next 21 L: List n... nil current n ListInstance">
current:= current^.prior; ic" title="G.Matisons - "Datu struktūras", Rīga 2003 97... Node = record el: StdElement; next: NodePointer; prior: NodePointer end; NodePointer = ^Node;... Tekošā elementa priekšteča meklēšana ir kļuvusi vienkāršāka: FindPrior(L) => current:= current^.prior; ic">
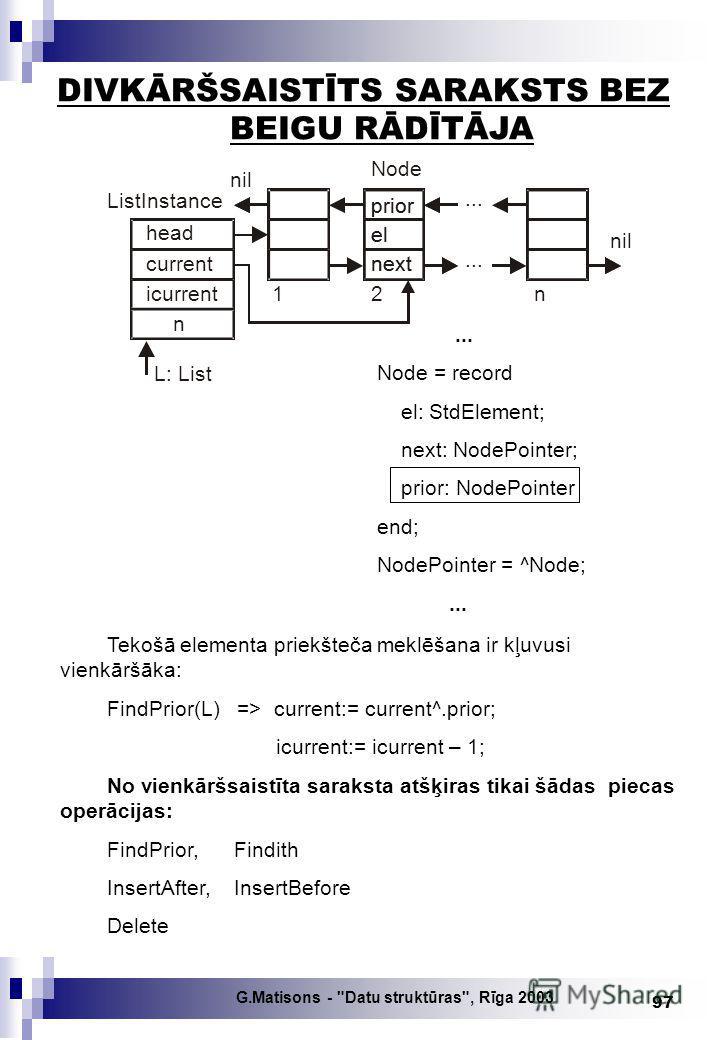
1 then with L^ do begi" title="G.Matisons - "Datu struktūras", Rīga 2003 98 DIVKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA procedure FindPrior (var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūs par jauno tekošo elementu} begin if CurPos(L) > 1 then with L^ do begi" class="link_thumb">
98
G.Matisons - "Datu struktūras", Rīga DIVKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA procedure FindPrior (var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūs par jauno tekošo elementu} begin if CurPos(L) > 1 then with L^ do begin current:= current^.prior; icurrent:= icurrent – 1 end end; procedure InserAfter (var L: List; e: StdElement); {Sarakstā L^ jaunu elementu e pievieno aiz tekošā elementa, un tas kļūst par jauno tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do begin new(p); p^.el:= e; if Empty(L) then {saraksts ir tukšs} begin head:= p; p^.next:= nil; p^.prior:= nil; end else {saraksts nav tukšs} begin {izkārto saites} p^.next:= current^.next; p^.prior:= current; if not Last(L) then current^.next^.prior:= p; current^.next:= p end; current:= p; icurrent:= icurrent + 1; n:= n + 1 end end;
1 then with L^ do begi">
1 then with L^ do begin current:= current^.prior; icurrent:= icurrent – 1 end end; procedure InserAfter (var L: List; e: StdElement); {Sarakstā L^ jaunu elementu e pievieno aiz tekošā elementa, un tas kļūst par jauno tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do begin new(p); p^.el:= e; if Empty(L) then {saraksts ir tukšs} begin head:= p; p^.next:= nil; p^.prior:= nil; end else {saraksts nav tukšs} begin {izkārto saites} p^.next:= current^.next; p^.prior:= current; if not Last(L) then current^.next^.prior:= p; current^.next:= p end; current:= p; icurrent:= icurrent + 1; n:= n + 1 end end;">
1 then with L^ do begi" title="G.Matisons - "Datu struktūras", Rīga 2003 98 DIVKĀRŠSAISTĪTS SARAKSTS BEZ BEIGU RĀDĪTĀJA procedure FindPrior (var L: List); {Sarakstā L^ meklē tekošā elementa priekšteci, kas kļūs par jauno tekošo elementu} begin if CurPos(L) > 1 then with L^ do begi">

99
G.Matisons - "Datu struktūras", Rīga Saišu izkārtošana, ja saraksts nav tukšs un tekošais ir vidējā posma elements: Saišu izkārtošana, ja tekošais ir pēdējais elements: prior el next Node n -1n current izkārto tikai 3 saites prior e next p nil current...

100
G.Matisons - "Datu struktūras", Rīga procedure InsertBefore (var L: List; e: StdElement); {Sarakstā L^ pirms tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do if not Empty(L) then if current = head then {pievieno pirms 1.elementa} begin new(p); p^.el:= e; head:= p; p^.prior:= nil; p^.next:= current; current^.prior:= p; current:= p; n:= n +1 end else begin {tekošais nav 1. elements} FindPrior(L); InsertAfter(L,e) end else InsertAfter (L, e) {saraksts ir tukšs} end; Jauna elementa pievienošana, ja tekošais ir pirmais elements: prior el next Node 2 current prior e next p nil current head 1...

101
G.Matisons - "Datu struktūras", Rīga procedure Delete (var L: List); {Sarakstā L^ dzēš tekošo elementu un vairumā gadījumu nākamais elements kļūst par tekošo elementu} var p: NodePointer; begin if not Empty(L) then with L^ do begin p:= current; if current = head then {dzēš 1. elementu} begin if n = 1 then {1. elements - vienīgais} begin head:= nil; current:= nil; icurrent:= 0 end else {1. elements sarakstā nav vienīgais} begin head:= current^.next; current^.next^.prior:= nil; current:= head end else if current^.next = nil then {Last(L) - dzēš pēdējo elementu} begin current^.prior^.next:= nil; current:= current^.prior; icurrent:= icurrent – 1 end else {dzēš vidējā posma elemetu} begin current^.prior^.next:= current^.next; current^.next^.prior:= current^.prior; current:= current^.next end; dispose (p); n:= n -1 {kopējais zars} end end;

102
G.Matisons - "Datu struktūras", Rīga Saišu izkārtošana: dzēš vidējā posma elementu prior el next Node i+1 p current i i-1 current... 2) current^.next^.prior:= current^.prior; 1) current^.prior^.next:= current^.next; prior el next Node current 2... nil p 1 head nil dzēš 1. elementu: head:=current^.next; current^.next^.prior:=nil; current:=head; prior el next Node current n... nil p n -1 nil dzēš pēdējo elementu: current^.prior^.next:=nil; current:=current^.prior; Icurrent:=icurrent-1; 3) current:=current^.next; :

103
G.Matisons - "Datu struktūras", Rīga procedure Findith (var L: List; i: Count); {Sarakstā L^ meklē elementu ar kārtas numuru i. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} var k: Count; begin if (not Empty(L)) and (i <= Size(L)) then with L^ do begin if i <= (n div 2) then {atrodas tuvāk sākumam} begin current:= head; for k:= 1 to i -1 do current:= current^.next end else {atrodas tuvāk beigām} begin FindLast(L); for k:= n downto i + 1 do current:= current^.prior end; icurrent:= i end end;

104
G.Matisons - "Datu struktūras", Rīga CIRKULĀRI SARAKSTI Operācijas divkāršsaistītā cirkulārā sarakstā: Create, *First, *FindFirst, InsertAfter, *Terminate, Last, FindLast, InsertBefore, *Size, FindNext, Delete, *CurPos, FindPrior, *Update *Empty, FindKey, *Retrieve, *Full, Findith * - tāda pati operācija kā VSSBBR tail icurrent Nor pirmais elements: tail^.next p ādes: ēdējais elements: tail tekošais elements: current el next Node 21 L: List n... current n ListInstance head icurrent Norādes:pirmais elements: head pēdējais elements: head^.prior tekošais elements: current el next Node 21 L: List n... current n ListInstance prior

105
G.Matisons - "Datu struktūras", Rīga procedure FindNext (var L: List); begin if not Empty(L) then with L^ do begin current:= curernt^.next; if icurrent = n then icurrent:= 1 else icurrent:= icurrent + 1; end end; procedure FindPrior (var L: List); begin if not Empty(L) then with L^ do begin current:= current^.prior; if icurrent = 1 then icurrent:= n else icurrent:= icurrent – 1; end end; procedure FindLast (var L: List); begin if CurPos(L) <> Size(L) then with L^ do begin current:= head^.prior; icurrent:= n end end; DIVKĀRŠSAISTĪTS CIRKULĀRS SARAKSTS
Size(L) then with L^ do begin current:= head^.prior; icurrent:= n end end; DIVKĀRŠSAISTĪTS CIRKULĀRS SARAKSTS">

106
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var L: List; tkey: KeyType; var found: boolean); {Cirkulārā sarakstā L^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} var p: NodePointer; k: Count; begin found:= false; if not Empty(L) then with L^ do begin k:= 1; p:= head; while (p^.next <> head ) and (p^.el.key <> tkey) do {meklē elementu} begin p:= p^.next; k:= k + 1 end; if p^.el^.key = tkey then begin {sekmīga meklēšana} current:= p; icurrent:= k; found:= true end end;
head ) and (p^.el.key <> tkey) do {meklē elementu} begin p:= p^.next; k:= k + 1 end; if p^.el^.key = tkey then begin {sekmīga meklēšana} current:= p; icurrent:= k; found:= true end end;">

107
G.Matisons - "Datu struktūras", Rīga procedure Findith(var L: List; i: Count); {Cirkulārā sarakstā L^ meklē elementu ar kārtas numuru i. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} var k: Count; begin if (i <= L^.n) and (not Empty(L)) then with L^ do begin if i <= (n div 2) then {tuvāk sākumam} begin current:= head; for k:= 1 to i – 1 do current:= current^.next end else {tuvāk saraksta beigām} begin current:= head^.prior; for k:= n downto i + 1 do current:= current^.prior end; icurrent:= i end end;

108
G.Matisons - "Datu struktūras", Rīga procedure InsertAfter (var L: List; e: StdElement); {Cirkulārā sarakstā L^ aiz tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} var p: NodePointer; begin if not Full(L) then with L^ do begin new(p); p^.el:= e; if Empty(L) then {saraksts ir tukšs} begin head:= p; p^.next:= p; p^.prior:= p end else {saraksts nav tukšs} begin {izkārto 4 saites} current^.next^.prior:= p; p^.next:= current^.next; p^prior:= current; current^.next:= p end; current:= p; icurrent:= icurrent + 1; n:= n + 1 end end;

109
G.Matisons - "Datu struktūras", Rīga Saišu izkārtošana: 1

110
G.Matisons - "Datu struktūras", Rīga procedure InsertBefore (var L: List; e: StdElement); {Cirkulārā sarakstā L^ pirms tekošā elementa pievieno jaunu elementu e, kas kļūst par tekošo elementu} begin if not Full(L) then with L^ do begin if not Empty(L) then begin {FindPrior(L)} current:= current^.prior; if icurrent = 1 then icurrent:= n else icurrent:= icurrent – 1 end; InsertAfter(L, e); if current^.next = head then {Last(L)} begin {pēdējais elements kļūst par pirmo} head:= current; icurrent:= 1 end end; function Last(L:List): boolean; {Cirkulārā sarakstā L^ pārbauda, vai pēdējais elements ir tekošais elements} begin Last:= L^.current = L^.head^.prior end;

111
G.Matisons - "Datu struktūras", Rīga procedure Delete (var L: List); {Cirkulārā sarakstā L^ dzēš tekošo elementu, tekošā elementa pēctecis kļūst par tekošo elementu} var p: NodePointer; begin if not Empty (L) then with L^ do begin p:= current; if n = 1 then {saraksts kļūs tukšs} begin head:= nil; current:= nil; icurrent:= 0; end else {sarakstā ir vairāki elementi} begin {izkārto 2 saites} current^.prior^.next:= current^.next; current^.next^.prior:= current^.prior; if current^.next = head then icurrent:= 1; {Last(L) – dzēš pēdējo elementu} current:= current^.next; if p = head then head:= current; end; dispose (p); n:= n – 1 end end; Saišu izkārtošana, ja dzēš vidējā posma elementu: el next 2 p current 1 3 prior 1) current^.prior^.next:= current^.next; 2) current^.next^.prior:= current^.prior; current:= current^.next; 1 2 current

112
G.Matisons - "Datu struktūras", Rīga DIVKĀRŠSAISTĪTS GREDZENS Gredzens ir cirkulārs saraksts, kuram nav ne sākuma, ne beigu. Reizēm lauku icurrent vadības struktūrā tomēr lieto Tādā gadījumā icurrent vērtība atbilst jaunā elementa izvietojuma secībai, gredzenu veidojot. Create FindNext Insert Delete Terminate FindPrior InsertAfter Retrieve Size FindKey InsertBefore Update Full Empty Nav paredzētas sādas operācijas: First FindFirst FindLast Findith Last Gredzena apstrādes operācijas:

" title="G.Matisons - "Datu struktūras", Rīga 2003 113 VIENKĀRŠSAISTĪTS GREDZENS Svarīgākās operācijas: procedure FindPrior (var R: Ring); {Gredzenā R^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if Size(R) > " class="link_thumb">
113
G.Matisons - "Datu struktūras", Rīga VIENKĀRŠSAISTĪTS GREDZENS Svarīgākās operācijas: procedure FindPrior (var R: Ring); {Gredzenā R^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if Size(R) > 1 then with R^ do begin p:= current^.next; q:= current; while p <> current do begin q:= p; p:= p^.next end; current:= q end end; el Node current n next... R: Ring current - tekošā elementa norāde current^.next - nākamā elementa norāde RingInstance
">
1 then with R^ do begin p:= current^.next; q:= current; while p <> current do begin q:= p; p:= p^.next end; current:= q end end; el Node current n next... R: Ring current - tekošā elementa norāde current^.next - nākamā elementa norāde RingInstance">
" title="G.Matisons - "Datu struktūras", Rīga 2003 113 VIENKĀRŠSAISTĪTS GREDZENS Svarīgākās operācijas: procedure FindPrior (var R: Ring); {Gredzenā R^ meklē tekošā elementa priekšteci, kas kļūst par tekošo elementu} var p, q: NodePointer; begin if Size(R) > ">
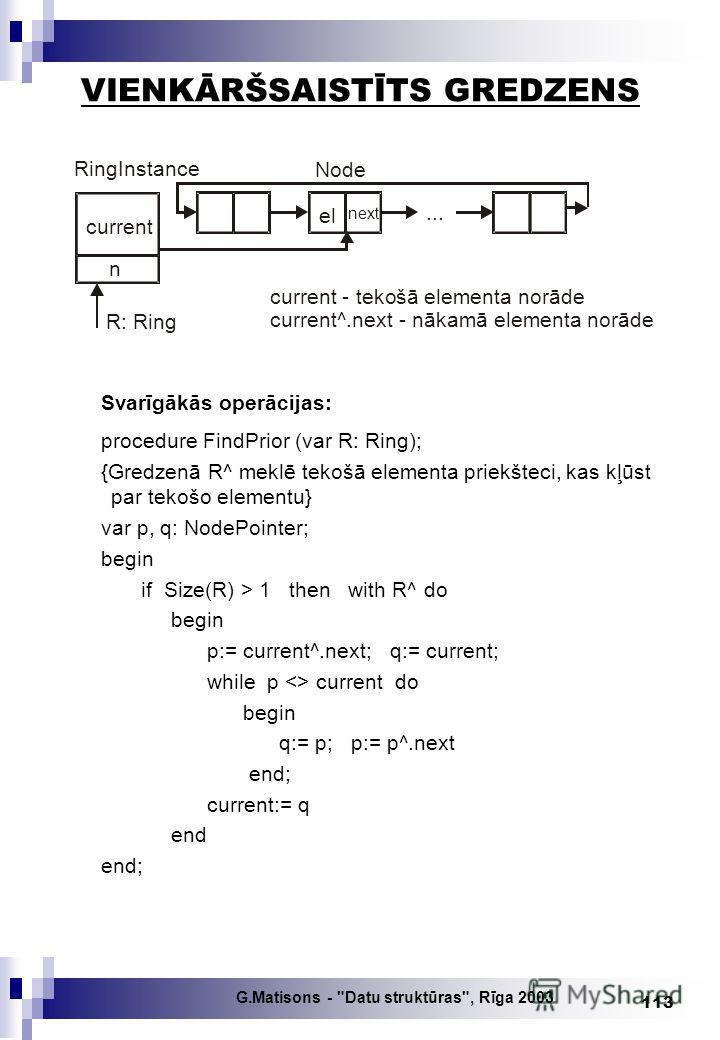
114
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var R:Ring; tkey: KeyType; var found: boolean); {Gredzenā R^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu} var p: NodePointer; begin found:= false; if not Empty(R) then with R^ do begin p:= current; while (p^.next <> current) and (p^.el.key <> tkey) do p:= p^.next; {meklē elementu} if p^.el.key = tkey then {sekmīga meklēšana} begin current:= p; found:= true end end;
current) and (p^.el.key <> tkey) do p:= p^.next; {meklē elementu} if p^.el.key = tkey then {sekmīga meklēšana} begin current:= p; found:= true end end;">

115
G.Matisons - "Datu struktūras", Rīga HRONOLOĢISKI SAKĀRTOTI SARAKSTI (HSS) (Chronologically ordered lists) Kārtojuma kritērijs: elementa pievienošanas laiks. Jaunus elementu pievieno saraksta beigās. Operācija Delete neietekmē hronoloģisko kārtību. Ja tekošo elemetu dzēš, tad operācija Insert to pievienos saraksta beigās. VEKTORIĀLĀ FORMĀ ATTĒLOTS HSS const MaxSize = 500; type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string; KeyType = integer; Edit = 1.. 3; StdElement = record; data: DataType; key: KeyType end; ChronListInstance = record current, n: Count; el: array[Position] of StdElement end; ChronList = ^ChronListInstance; Atšķirīga ir tikai operācija Insert ChronListInstance current n el[1] el[2]... el[current]... brīvā atmiņa CL:ChronList el[n]... el[MaxSize] saraksts

116
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTS HSS procedure Insert (CL: ChronList; e: StdElement); {Saraksta CL^ beigās pievieno jaunu elementu e} begin if not Full(CL) then with CL^ do begin n:= n + 1; el[n]:= e; current:= n end end; const MaxSize = 500; type Count = 0.. MaxSize; Edit = 1.. 3; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Node = record el: StdElement; next, prior: NodePointer end; NodePointer = ^Node; ChronListInstance = record head, current: NodePointer; icurrent, n: Count end; ChronList = ^ChronListInstance; el next prior current n CL: ChronList... Node n head icurrent Izvēlas divkāršsaistītu cirkulāru sarakstu HSS veidošanai: ChronListInstance

117
G.Matisons - "Datu struktūras", Rīga procedure Insert (var CL: ChronList; e: StdElement); {Hronoloģiski sakārtotā saraksta CL^ beigās pievieno jaunu elementu e} var p: NodePointer; begin if not Full(CL) then with CL^ do begin new (p); p^.el:= e; if Empty(CL) then {saraksts ir tukšs} begin head:= p; p^.next:= p; p^.prior:= p end else {saraksts nav tukšs} begin [izkārto 4 saites} p^.next:= head; head^.prior^.next:= p; p^.prior:= head^.prior; head^.prior:= p end; n:= n + 1; icurrent:= n; current:= p end end;

118
G.Matisons - "Datu struktūras", Rīga DIVKĀRŠSAISTĪTS CIRKULĀRS HSS VIENKĀRŠSAISTĪTS CIRKULĀRS HSS Saišu izkārtošana, pievienojot jaunu elementu: 1) p^.next:= head; 2) head^.prior^.next:= p; 3) p^prior:= head^.prior; 4) head^.prior:= p; el next prior head current p (1) (4) (3) (2) current:= p; n-1n current prior el next prior el next elnext 1) p^.next:= tail^.next; 2) tail^.next:= p; current:= p; tail:= p; el next currenttail p (2) (1) n-1 n tailcurrent elnext

119
G.Matisons - "Datu struktūras", Rīga Steka operācijaHSS operācijas Push (CL, e) Pop (CL, e) LIFO Insert (CL, e) FindLast (CL) Retrieve (CL, e) Delete (CL) Rindas operācijaHSS operācijas Enqueue (CL, e) Serve (CL, e) FIFO Insert (CL, e) FindFirst (CL) Retrieve (CL, e) Delete (CL) HSS var izmantot arī kā steku vai rindu:

120
G.Matisons - "Datu struktūras", Rīga SAŠĶIROTI SARAKSTI (sorted lists) Elementi sarakstā sakārtoti pēc atslēgas lauku vērtībam: key i-1 < key i < key i+1, i = 2,3,...., n-1. Saraksta veidošana: 1) ar operāciju Insert – sākot no saraksta sākuma, sameklē pirmo elementu, kura current^.el.key > e.key, un jauno elementu pievieno sarakstā pirms tā; 2) jaunu elementu sarakstam pievieno kā parasti un laiku pa laikam ar šķirošanas operāciju Sort saraksta elementus sašķiro augošā secībā; 3) meklēšanas operācijai FindKey ir divi algoritmi atbilstoši diviem saraksta attēlojuma modeļiem: a) vektoriālais - FindKey algoritmi: lineārā meklēšana O(n), binārā meklēšana O(log 2 n), interpolatīvā meklēšana O(log 2 n) b) saistītais - FindKey algoritms: lineārā meklēšana O(n); 4) atšķirīgas operācijas: BinSearch, FindKey, Insert, Update. Priekšroka – vektoriālā formā attēlotam sašķirotam sarakstam. SortedListInstance current n el [1] el [2]... el [current]... SL:SortedList el [n]... el [MaxSize] MaxSize = 500; type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Edit = 1.. 3; SortedListInstance = record current: Count; n: Count; el: array [Position] of StdElement end; SortedList = ^SortedListInstance;
e.key, un jauno elementu pievieno sarakstā pirms tā; 2) jaunu elementu sarakstam pievieno kā parasti un laiku pa laikam ar šķirošanas operāciju Sort saraksta elementus sašķiro augošā secībā; 3) meklēšanas operācijai FindKey ir divi algoritmi atbilstoši diviem saraksta attēlojuma modeļiem: a) vektoriālais - FindKey algoritmi: lineārā meklēšana O(n), binārā meklēšana O(log 2 n), interpolatīvā meklēšana O(log 2 n) b) saistītais - FindKey algoritms: lineārā meklēšana O(n); 4) atšķirīgas operācijas: BinSearch, FindKey, Insert, Update. Priekšroka – vektoriālā formā attēlotam sašķirotam sarakstam. SortedListInstance current n el [1] el [2]... el [current]... SL:SortedList el [n]... el [MaxSize] MaxSize = 500; type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Edit = 1.. 3; SortedListInstance = record current: Count; n: Count; el: array [Position] of StdElement end; SortedList = ^SortedListInstance;">

121
G.Matisons - "Datu struktūras", Rīga Uzlabotais (Bottenbruch) binārās meklēšanas algoritms: procedure BinSearch (SL: SortedList; tkey: KeyType; var lo, hi: Count); var mid: Count; begin with SL^ do while lo < hi do begin mid:= (lo + hi + 1) div 2; if el[mid].key > tkey then hi:= mid – 1 else lo:= mid end end; Binārās meklēšanas algoritma darbības princips: hi = mid - 1 lo = mid mid - 1 mid + 1..n mid lo = 1 hi = n if el[mid].key>tkey then hi:= mid - 1; if el[mid].key < tkey then lo:= mid + 1; mid:= (lo + hi) div 2; if el[mid].key = tkey then found:= true; if mid = 1 then found:= false;
tkey then hi:= mid – 1 else lo:= mid end end; Binārās meklēšanas algoritma darbības princips: hi = mid - 1 lo = mid + 1 1..mid - 1 mid + 1..n mid lo = 1 hi = n if el[mid].key>tkey then hi:= mid - 1; if el[mid].key < tkey then lo:= mid + 1; mid:= (lo + hi) div 2; if el[mid].key = tkey then found:= true; if mid = 1 then found:= false;">

122
G.Matisons - "Datu struktūras", Rīga procedure FindKey (SL: SortedList; tkey: KeyType; var found:boolean); {Binārās meklēšanas algoritms. Sašķirotajā sarakstā SL^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements kļūst par tekošo elementu.} var lo, hi: Count; begin found:= false; if not Empty(SL) then with SL^ do begin lo:= 0; hi:= n; {meklēšanas diapazons} BinSearch (SL, tkey, lo, hi); {meklē elementu} if (hi <> 0) and (el[hi].key = tkey) then begin {sekmīga meklēšana} current:= hi; found:= true end end;
0) and (el[hi].key = tkey) then begin {sekmīga meklēšana} current:= hi; found:= true end end;">

123
G.Matisons - "Datu struktūras", Rīga procedure Insert (var SL: SortedList; e: StdElement); {Sašķirotajā sarakstā SL^ jaunajam elementam e sameklē vietu un to izvieto pozīcijā hi+1} var hi, lo k: Count; begin if not Full(SL) then with SL^ do begin if Empty(SL) then current:= 1 {saraksts ir tukšs} else {meklē vietu} begin lo:= 0; hi:= n; BinSearch (SL, e.key, lo, hi); {sameklēto pozīciju hi+1 atbrīvo} for k:= n downto hi + 1 do el[k+1]:= el[k]; current:= hi + 1 end el[current]:= e; {elementu izvieto pozīcijā hi+1} n:= n + 1 end end;

124
G.Matisons - "Datu struktūras", Rīga procedure Update (var SL: SortedList; e: StdElement; k: Edit); {Sašķirotā sarakstā SL^ labo tekošā elementa saturu atbilstoši labošanas variantam k} var temp: StdElement; begin if not Empty(SL) then with SL^ do begin case k of 1: el[current].data:= e.data; 2: el[current].key:= e.key; 3: el[current]:= e; end; if k>1 then {labots atslēgas lauka saturs} begin temp:= el[current; {izlaboto elementu saglabā} Delete(SL); {un tad sarakstā dzēš} Insert(Sl,temp) {un no jauna izvieto sarakstā} end; end end; Šis operācijas Update algoritms ir īss un viegli saprotams. Taču tam piemīt arī trūkums. Sašķirotā sarakstā elementa dzēšana tiek izpildīta kā elementu pārsūtīšanas operācija, kuras izpildes efektivitātes kārta ir O(n). Jauna elementa pievienošana sašķirotam sarakstam ir saistīta ar vietas meklēšanu jaunajam elementam un, lai šo sameklēto vietu pēc tam atbrīvotu, atkal nepieciešama elementu pārsūtīsana, kuras izpildes efektivitātes kārta atkal ir O(n). Var izveidot arī tādu operācijas Update algoritmu, kas tiks izpildīts divreiz ātrāk.
1 then {labots atslēgas lauka saturs} begin temp:= el[current; {izlaboto elementu saglabā} Delete(SL); {un tad sarakstā dzēš} Insert(Sl,temp) {un no jauna izvieto sarakstā} end; end end; Šis operācijas Update algoritms ir īss un viegli saprotams. Taču tam piemīt arī trūkums. Sašķirotā sarakstā elementa dzēšana tiek izpildīta kā elementu pārsūtīšanas operācija, kuras izpildes efektivitātes kārta ir O(n). Jauna elementa pievienošana sašķirotam sarakstam ir saistīta ar vietas meklēšanu jaunajam elementam un, lai šo sameklēto vietu pēc tam atbrīvotu, atkal nepieciešama elementu pārsūtīsana, kuras izpildes efektivitātes kārta atkal ir O(n). Var izveidot arī tādu operācijas Update algoritmu, kas tiks izpildīts divreiz ātrāk.">

125
G.Matisons - "Datu struktūras", Rīga procedure Update (var SL: SortedList; e: StdElement; k: Edit); {Sašķirotā sarakstā SL^ labo tekošā elementa saturu atbilstoši labošanas variantam k} var lo, hi, i:Count: x: StdElement; oldkey: KeyType; begin if not Empty(SL) then with SL^ do begin oldkey:= el[current].key; {fiksē veco atslēgas lauka vērtību} case k of 1: el[current].data:= e.data; 2: el[current].key:= e.key; 3: el[current]:= e; end; if k>1 then {labots atslēgas lauka saturs} begin x: el[current]; {saglabā izlaboto elementu} {uzdod meklēšanas diapazonu un meklē elementa vietu} if el[current].key < oldkey then begin lo:=0; hi: current end else begin lo:= current: hi:= n end; BinarySearch(Sl, e.key, lo, hi); {elementam atbrīvo vietu un izvieto attiecīgajā pozīcijā} if el[cuurrent].key < oldkey then begin for i:= current-1 downto hi+1 do el[i+1]:= el[i]; el[hi+1]:= x end else begin for i:= current+1 to hi do el[i-1]:= el[i]; el[hi]:= x end end end;
1 then {labots atslēgas lauka saturs} begin x: el[current]; {saglabā izlaboto elementu} {uzdod meklēšanas diapazonu un meklē elementa vietu} if el[current].key < oldkey then begin lo:=0; hi: current end else begin lo:= current: hi:= n end; BinarySearch(Sl, e.key, lo, hi); {elementam atbrīvo vietu un izvieto attiecīgajā pozīcijā} if el[cuurrent].key < oldkey then begin for i:= current-1 downto hi+1 do el[i+1]:= el[i]; el[hi+1]:= x end else begin for i:= current+1 to hi do el[i-1]:= el[i]; el[hi]:= x end end end;">

tkey t" title="G.Matisons - "Datu struktūras", Rīga 2003 126 REKURSĪVS BINĀRĀS MEKLĒŠANAS ALGORITMS procedure BinSearch(SL: SortedList; tkey: KeyType; var lo, hi: Count); var mid: Count; begin if lo < hi then begin mid:= (lo + hi + 1) div 2; if el[mid].key > tkey t" class="link_thumb">
126
G.Matisons - "Datu struktūras", Rīga REKURSĪVS BINĀRĀS MEKLĒŠANAS ALGORITMS procedure BinSearch(SL: SortedList; tkey: KeyType; var lo, hi: Count); var mid: Count; begin if lo < hi then begin mid:= (lo + hi + 1) div 2; if el[mid].key > tkey then BinSearch(SL, tkey, lo, mid-1) else BinSearch(SL, tkey, mid, hi) end end;
tkey t">
tkey then BinSearch(SL, tkey, lo, mid-1) else BinSearch(SL, tkey, mid, hi) end end;">
tkey t" title="G.Matisons - "Datu struktūras", Rīga 2003 126 REKURSĪVS BINĀRĀS MEKLĒŠANAS ALGORITMS procedure BinSearch(SL: SortedList; tkey: KeyType; var lo, hi: Count); var mid: Count; begin if lo < hi then begin mid:= (lo + hi + 1) div 2; if el[mid].key > tkey t">

127
G.Matisons - "Datu struktūras", Rīga INTERPOLATĪVĀ MEKLĒŠANA Meklēšanas procesā sarakstu dala noteiktā proporcijā, bet nevis uz pusēm. Piemērs: n = 50; el[lo].key = 101; el[hi].key = 200; tkey = 180
![G.Matisons - Datu struktūras, Rīga 2003 127 INTERPOLATĪVĀ MEKLĒŠANA Meklēšanas procesā sarakstu dala noteiktā proporcijā, bet nevis uz pusēm. Piemērs: n = 50; el[lo].key = 101; el[hi].key = 200; tkey = 180](http://images.myshared.ru/19/1234678/slide_127.jpg "G.Matisons - Datu struktūras, Rīga 2003 127 INTERPOLATĪVĀ MEKLĒŠANA Meklēšanas procesā sarakstu dala noteiktā proporcijā, bet nevis uz pusēm. Piemērs: n = 50; el[lo].key = 101; el[hi].key = 200; tkey = 180")
128
G.Matisons - "Datu struktūras", Rīga MULTIPLIKATĪVĀ MEKLĒŠANA (Standish, 1980). Sarakstu dala 2 daļās pēc Fibonači skaitļu principa: F 0 = 0; F 1 = 1; F i = F i-1 + F i-2, i = 2,3,..., n. Piemērs: n = 13; Fibonači skaitļu virkne: 0, 1, 1, 2, 3, 5, 8, 13 Pamatā tas ir binārās meklēšanas paveids:

129
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTS SAŠĶIROTS SARAKSTS Operācija FindKey – lieto lineārās meklēšanas algoritmu. Ja lietotu binārās meklēšanas algoritmu, tad saraksta viduspunkts mid būtu jāmeklē, tā meklēšana ir O(n) kārtas operācija, kurā tiek izpildītas darbības ar rādītājiem, visā meklēšanas procesā būtu nepieciešamas n šādas manipulācijas. Šī iemesla dēļ no binārās meklēšanas algoritma izmantošanas atsakās. Operācija Insert – sākot no saraksta sākuma, meklē vietu jaunajam elementam. Meklēšanas procesa darbības: current:=head; icurrent:=1; {sāk vietas meklēšanu} while current^.el.key < e.key do {meklēšana nosacījums} begin current:=current^.next; {iestata nākamo elementu} icurrent:=icurrent+1 end; Jauno elementu izvieto pirms tā elementa, uz ko norāda rādītājs current. Kad vietas sameklēta un jaunais elements sarakstā izvietots, tas klūst par tekošo elementu sašķirotajā sarakstā. Operācija Update – ja tiek labots atslēgas lauks key, tad elementam sarakstā sameklē jaunu vietu līdzīgi tam, kā tas tika darīts operācijā Insert. Vecajā vietā izlaboto elementu dzēš un izvieto jaunajā vietā pirms tā elementa, uz ko norāda rādītājs current. Vietas meklēšanu pabeidzot, attiecīgi izkārto arī elementu saites un precizē norādes.

130
G.Matisons - "Datu struktūras", Rīga PĒC LIETOJUMA BIEŽUMA SAKĀRTOTI SARAKSTI (Frequency ordered lists) Elementu kārtojuma kritērijs: to lietojuma biežums. Visbiežāk lietotais elemets atrodas saraksta saraksta sākumā, bet visretāk lietotais elements – saraksta beigās. Katram elementam sarakstā būtu jāpievieno tā lietojuma varbūtība (probability). Praktiski tā nav zināma. Reizēm lietojuma varbūtību cenšas iepriekš prognozēt vai noteikt citādi (piemēram, pēc likuma). Pēc lietojuma biežuma sakārtota saraksta elementa uzbūve: Izmanto pēc lietojuma biežuma sakārtota saraksta paveidu: pašorganizētu sarakstu (self organizing list). Ir 3 paņēmieni pašorganizēta saraksta veidošanai. Katram pašorganizēta saraksta veidošanas paņēmienam ir sava būtība un tās realizācijas metode. 1.paņēmiena būtība: ja ar kādu pašorganizēta saraksta elementu strādā, tad tas strauji pārvietojas virzienā uz saraksta sākumu, apejot visus elementus, kuriem ir mazāks lietojuma biežums. 2.paņēmiena būtība: ja ar kādu pašorganizēta saraksta elementu strādā, tad tas lēni (par vienu vietu) pārvietojas virzienā uz saraksta sākumu. 3.paņēmiena būtība: ja kāds pašorganizēta saraksta elements netiek lietots, tad tas pārvietojas virzienā uz saraksta beigām. Lauka prob varbūtība grūti nosakāma vai arī nav zināma, Lauka prob varbūtība ar laiku mainās.

131
G.Matisons - "Datu struktūras", Rīga metode 1) katram elementam saistītā sarakstā pievieno papildus lauku freq, kurā ieraksta elementa lietojuma biežumu: Dažas atšķirības, definējot elementu divkāršsaistītā sarakstā:... type FreqType = integer; {parasti vesels pozitīvs skaitlis}... StdElement = record data: DataType; key: KeyType end; AugElement = record el: StdElement; freq: FreqType {papildus lietojuma biežuma lauks} end; Node = record elem: AugElement; {ieraksts ar tipu AugElement} next, prior: NodePointer end; NodePointer = ^Node; elem prior next current elementa un tā lauku piekļuve un norādes: current^.elem current^.elem.el current^.elem.el.data current^.elem.el.key current^.elem.freq current^.next current^.prior

132
G.Matisons - "Datu struktūras", Rīga ) izpildot operācijas FindKey, Findith, Retrieve, Update, izmainās elementa ietojuma biežums: inc(elem[current].freq) – vektorālā sarakstā un inc(current^.elem.freq) – saistītā sarakstā. Tekošais elements tiek pārvietots tuvāk saraksta sākumam, apejot visus elementus, kuriem mazāka freq vērtība, t.i., virzienā uz saraksta sākumu tiek sameklēts pirmais elements, kuram ir vienāda vai lielāka lietojuma biežuma freq vērtība. Tas elements, kurš atrodas aiz sameklētā elementa, tiek apmainīts vietām ar tekošo elementu, tādējādi tekošais elements tiek pārvietots tuvāk saraksta sākumam; 3) ar operāciju Insert jaunu elementu vienmēr pievieno saraksta beigās. Jaunam elementam freq = metodes realizācija 1) elementam sarakstā papildus lauku freq nepievieno; 2) izpildot operācijas FindKey, Findith, Retrieve, Update, elements sarakstā tiek apmainīts vietām ar iepriekšējo elementu; 3) jaunu elementu, izpildot operāciju Insert, pievieno saraksta beigās. n current elem [1] SOL: SelfOrgList... type AugElement = record el: StdElement ; freq: FreqType end;... SelfOrgListInstance = record current, n: Count; e lem:array[Position] of AugElement end; SelfOrgList = ^SelfOrgListInstance; Elementa un tā lauku piekļuve: elem [current].el elem [current].el.data elem [current].el.key elem [current].freq Atšķirības, definējot vektoriālā formā attēlotu pašorganizētu sarakstu: elem [current]... elem [MaxSize] n SelfOrgListInstance

1) and (not First(SOL))" title="G.Matisons - "Datu struktūras", Rīga 2003 133 2. METODE (saistīts saraksts) procedure Swap(var SOL: SelfOrgList); {Saistītā sarakstā SOL^ tekošo un iepriekšējo elementu apmaina vietām} var temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL))" class="link_thumb">
133
G.Matisons - "Datu struktūras", Rīga METODE (saistīts saraksts) procedure Swap(var SOL: SelfOrgList); {Saistītā sarakstā SOL^ tekošo un iepriekšējo elementu apmaina vietām} var temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL)) then with SOL^ do begin temp:= current^.el; current^.el:= current^.prior^.el; current^.prior^.el:= temp; current:= current^.prior; icurrent:= icurrent – 1 end end; 2. METODE (vektoriālā formā attēlots saraksts) procedure Swap (var SOL: SefOrgList); {Vektoriālā formā attēlotā sarakstā SOL^ tekošo un iepriekšējo elementu apmaina vietām} var temp: StdElement; begin if (Size (SOL)>1) and (not First(SOL)) then with SOL^ do begin temp:= el[current]; el[current]:= el[current – 1]; el[current - 1]:= temp; current:= curent – 1 end end;
1) and (not First(SOL))">
1) and (not First(SOL)) then with SOL^ do begin temp:= current^.el; current^.el:= current^.prior^.el; current^.prior^.el:= temp; current:= current^.prior; icurrent:= icurrent – 1 end end; 2. METODE (vektoriālā formā attēlots saraksts) procedure Swap (var SOL: SefOrgList); {Vektoriālā formā attēlotā sarakstā SOL^ tekošo un iepriekšējo elementu apmaina vietām} var temp: StdElement; begin if (Size (SOL)>1) and (not First(SOL)) then with SOL^ do begin temp:= el[current]; el[current]:= el[current – 1]; el[current - 1]:= temp; current:= curent – 1 end end;">
1) and (not First(SOL))" title="G.Matisons - "Datu struktūras", Rīga 2003 133 2. METODE (saistīts saraksts) procedure Swap(var SOL: SelfOrgList); {Saistītā sarakstā SOL^ tekošo un iepriekšējo elementu apmaina vietām} var temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL))">

134
G.Matisons - "Datu struktūras", Rīga APMAIŅAS OPERĀCIJA 3. metodei Vektoriālā formā attēlots saraksts procedure Swap (var SOL: SelfOrgList); {Tekošajā pozīcijā current esošo elementu dzēš un izvieto pirmajā pozīcijā} var k: Position; temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL)) then with SOL^ do begin temp:= el[current]; for k:= current-1 downto 1 do el[k]:= el [k+1]; {elementu dzēš} el[1]:= temp; {elementu izvieto 1.pozīcijā} current:= 1 end end; Divkāršsaistīts cirkulārs pašorganizēts saraksts procedure Swap(var SOL: SelfOrgList); var p: NodePointer; temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL)) then with SOL^ do begin p:= current; temp:= current^.el; {elementu dzēš} current^.prior^.next:= current^.next; current^.next^.prior:= curent^.prior; dispose (p); new(p); {un tad izvieto saraksta sākumā} p^.el:= temp; p^.next:= head; p^.prior:= head^.prior; head^.prior:= p; head^.prior^.next:= p; head:= p; current:= p; icurrent:= 1 end end;
1) and (not First(SOL)) then with SOL^ do begin temp:= el[current]; for k:= current-1 downto 1 do el[k]:= el [k+1]; {elementu dzēš} el[1]:= temp; {elementu izvieto 1.pozīcijā} current:= 1 end end; Divkāršsaistīts cirkulārs pašorganizēts saraksts procedure Swap(var SOL: SelfOrgList); var p: NodePointer; temp: StdElement; begin if (Size(SOL)>1) and (not First(SOL)) then with SOL^ do begin p:= current; temp:= current^.el; {elementu dzēš} current^.prior^.next:= current^.next; current^.next^.prior:= curent^.prior; dispose (p); new(p); {un tad izvieto saraksta sākumā} p^.el:= temp; p^.next:= head; p^.prior:= head^.prior; head^.prior:= p; head^.prior^.next:= p; head:= p; current:= p; icurrent:= 1 end end;">

135
G.Matisons - "Datu struktūras", Rīga APMAIŅAS OPERĀCIJA 1.metodei Vektoriālā formā attēlots saraksts procedure Swap(var SOL: SelfOrgList); {Pašorganizētā sarakstā SOL^, sākot ar tekošo pozīciju current, virzienā uz saraksta sākumu meklē elementu, kuram ir mazāks lietojuma biežums freq, un apmaino to vietām ar tekošo elementu} var k: Position; temp: AugElement; begin with SOL^ do begin {palielina lietojuma biežumu par 1} elem[current].freq:= elem[current].freq+1; if (Size(SOL)>1) and (not First(SOL)) then begin {meklē apmaināmo elementu – 3 gadījumi} if elem[current].freq <= elem[current-1].freq then exit; if elem[current].freq > elem[1].freq then k:= 1 else begin k:= current-1; while elem[current].freq > elem[k].freq do k:= k-1; k:= k+1 end; temp:= elem[current]; {elementu mainīšana vietām} elem[current]:= elem[k]; elem[k]:= temp; current:= k end end;
1) and (not First(SOL)) then begin {meklē apmaināmo elementu – 3 gadījumi} if elem[current].freq <= elem[current-1].freq then exit; if elem[current].freq > elem[1].freq then k:= 1 else begin k:= current-1; while elem[current].freq > elem[k].freq do k:= k-1; k:= k+1 end; temp:= elem[current]; {elementu mainīšana vietām} elem[current]:= elem[k]; elem[k]:= temp; current:= k end end;">

136
G.Matisons - "Datu struktūras", Rīga METODE Divkāršsaistīts cirkulārs pašorganizēts saraksts procedure Swap(var SOL: SelfOrgList); {Pašorganizētā sarakstā SOL^, sākot ar tekošo elementu current, virzienā uz saraksta sākumu meklē elementu, kuram ir mazāks lietojuma biežums freq, un apmaino to vietām ar tekošo elementu} var p: NodePointer; k: Count; temp: AugElement; begin with SOL^ do begin {palielina lietojuma biežumu par 1} current^.elem.freq:= current^.elem.freq+1; if (Size(SOL)>1) and (not First(SOL)) then begin if current^.elem.freq <= current^.prior^.elem.freq then exit; {nav jāvirza uz priekšu} if current^.elem.freq > head^.elem.freq then begin p:= head; k:= 1 end else begin {meklē samaināmo elementu} p:= current^.prior; k:= icurrent -1; while (current^.elem.freq > p^.elem.freq) do begin p:= p^.prior; k:= k – 1 end; p:= p^.next; k:= k+1 end; temp:= current^.elem; current^.elem:= p^.elem; p^.elem:= temp; current:= p; icurrent:= k end end;
1) and (not First(SOL)) then begin if current^.elem.freq <= current^.prior^.elem.freq then exit; {nav jāvirza uz priekšu} if current^.elem.freq > head^.elem.freq then begin p:= head; k:= 1 end else begin {meklē samaināmo elementu} p:= current^.prior; k:= icurrent -1; while (current^.elem.freq > p^.elem.freq) do begin p:= p^.prior; k:= k – 1 end; p:= p^.next; k:= k+1 end; temp:= current^.elem; current^.elem:= p^.elem; p^.elem:= temp; current:= p; icurrent:= k end end;">

137
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var SOL: SelfOrgList; tkey: KeyType; var found: boolean); {Pašorganizētā sarakstā SOL^ meklē elementu, kura atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētais elements pavirzās uz saraksta sākumu un kļūst par tekošo elementu} var p: NodePointer; k: Count; begin found:= false if not Empty(SOL) then with SOL^ do begin k:= 1; p:= head; while (p^.next <> head) and (p^.elem.el.key <> tkey) do begin p:= p^.next; k:= k+1 end; if p^.elem.el.key = tkey then begin found:= true; curent:= p; icurrent:= k; Swap(SOL) {izsauc apmaiņas operāciju} end end; Lineārās meklēšanas operācija divkāršsaistītā cirkulārā pašorganizētā sarakstā
head) and (p^.elem.el.key <> tkey) do begin p:= p^.next; k:= k+1 end; if p^.elem.el.key = tkey then begin found:= true; curent:= p; icurrent:= k; Swap(SOL) {izsauc apmaiņas operāciju} end end; Lineārās meklēšanas operācija divkāršsaistītā cirkulārā pašorganizētā sarakstā">

138
G.Matisons - "Datu struktūras", Rīga DAUDZKĀRŠSAISTĪTS SARAKSTS (multilinked list) Prasība, ka divkāršsaistītā sarakstā elementu otrā sasaiste ar rādītājiem prior ir loģiski pretēja elementu pirmajai sasaistei ar rādītājiem next, nav obligāta. Elementus sarakstā var sasaistīt ar rādītājiem, izmantojot jebkuru kārtošanas vai sasaistes principu. Pat tad, ja pēc būtības saraksts ir divkāršsaistīts, bet elementu divkāršā sasaiste nav loģiski pretēja, šādu sarakstu sauc par otrās kārtas daudzkāršsaistītu sarakstu (multilinked list of order two). Apskatīsim sarakstu, kurā elementu datu laukā data izvietota kāda rakstzīme, bet atslēgas laukā key uzdoti veseli pozitīvi skaitļi. Katram elementam papildus pievienots rādītāja lauks dataptr, kas paredzēts, lai datu laukus sasaistītu alfabētiskā secībā, un rādītāja lauks keyptr, lai atslēgas laukus sasaistītu augošā secībā. Vienkāršibas labad rādītāju lauki next un prior netiek apskatīti, bet tie ir iespējami. dataptr key data keypt r : NodePointer NodePointer : Daudzkāršsaistīta saraksta elementa uzbūve: StdElement: : DataType : KeyType Tātad katram elementam varētu pievienot vēl divus rādītāju laukus: next un prior.

139
G.Matisons - "Datu struktūras", Rīga Piemērā 3. elements ir tekošais, tātad icurrent=3. Sarakstā ir tikai 4 elementi. Jebkurā brīdī sarakstam var pievienot jaunus elementus vai tekošo elementu dzēst, attiecīgi pārkārtojot elementu sasaisti abos rādītāju kontūros un precizējot norādes. Saraksts nodrošina plašas elementu meklēšanas iespējas. Otrās kārtas daudzkāršsaistīta saraksta elementu un attiecīgo lauku piekļuves nodrošināšanai paredzēti divi sākumrādītāji: headint un headchar. Rādītājs headchar norāda uz 1.elementu datu lauku sasaistē, bet radītājs headint uz 1.elementu atslēgas lauku sasaistē. Abās sasaistēs pēdējā atslēgas lauka vērtība ir nil. Var paredzēt arī vēl attiecīgi divus beigu rādītājus tailint un tailchar. Tātad katram sasaistes kontūram obligāti jāparedz savs sākumrādītājs head un ieteicams arī attiecīga rādītāja tail lietojums. Var veidot arī cirkulāru sarakstu. Strādājot ar daudzkāršsaistītu sarakstu, kāds no saraksta elementiem vienmēr ir tekošais elements un uz to norāda rādītājs current. headchar headint current icurrent n L: List ListInstance dataptrkeyptrC(data)4 (key) Node nilF8 A7 H2 Otrās kārtas divkāršsaistīta saraksta piemērs:

140
G.Matisons - "Datu struktūras", Rīga STEKS (stack) Steks ir lineāra datu struktūra, kas darbojas pēc principa LIFO (Last-in / First-out – Pēdējais iekšā / Pirmais ārā). Steka virsotnē top, izpildot operāciju Push, nepārtraukti var pievienot jaunus elementus. No steka var nolasīt tikai to elementu, kas pēdējais pievienots stekam. Šim nolūkam paredzēta operācija Pop. Pēc nolasīšanas elements stekā tiek dzēsts un iepriekšējais elements nokļūst steka virsotnē top. Pamatoperācijas: Push, Pop. Servisa operācijas: Size, Empty, Full, Create, Terminate Papildoperācijas: Retrieve, Top, u.c. Steka elementu tips: StdElement. Steka tips: Stack.. VEKTORIĀLĀ FORMĀ ATTĒLOTS STEKS el[1] steka rādītājs el[2] S: Stack const MaxSize = 500; {uzdod liet.} type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string; {uzd.liet.} KeyType = integer; StdElement = record data: DataType; key: KeyType end ; StackInstance = record top: Count ; el: array [Position] of StdElement end ; Stack = ^StackInstance ; el[n]... StackInstance top 1. pozīcija 2. pozīcija... virsotne brīvās pozīcijas } el[MaxSize]

141
G.Matisons - "Datu struktūras", Rīga procedure Create (var S: Stack; var created: boolean); {Izveido jaunu tukšu steku S^} begin new(S); S^.top:= 0; created:= true; end; procedure Terminate (var S: Stack; var created: boolean); {Likvidē steku S^} begin if created then begin dispose (S); created:= false end end; function Size (var S: Stack): Count; {Nosaka elementu skaitu stekā S^} begin Size:= S^.top end; function Empty (S: Stack): boolean; {Pārbauda, vai steks S^ ir tukšs} begin Empty:= S^.top = 0; end; function Full (S: Stack): boolean; {Pārbauda, vai steks S^ ir pilns} begin Full:= S^.top = MaxSize end;

142
G.Matisons - "Datu struktūras", Rīga procedure Push (var S: Stack, e: StdElement); {Stekam S^ pievieno elementu e} begin if not Full(S) then with S^ do begin top:= top + 1; el[top]:= e end end; procedure Pop (var S: Stack; var e: StdElement); {No steka S^ nolasa elementu e} begin if not Empty (S) then with S^ do begin e:= el[top]; top:= top – 1 end end; Vektoriālā formā attēlotā steka liela priekšrocība ir tā, ka steka apstrādes operāciju algoritmi ir īsi un vienkārši Vektoriālā formā attēlotā steka galvenais trūkums - visai neefektīva pamatatmiņas izmantošana. Maksimālais elementu skaits stekā iepriekš ir grūti prognozējams. Steka laukā ir jāparedz pietiekami liels brīvs atmiņas apgabals, lai nepieļautu steksa pārpildi. Šo trūkumu var novērst, steka brīvajā atmiņas apgabalā organizējot vēl vienu steku, t.i., parastā steka vietā izveidojot steka pāri. Vienlaicīgi var strādāt ar abiem stekiem vai arī tikai ar vienu no tiem.

143
G.Matisons - "Datu struktūras", Rīga STEKA PĀRIS (stack pair) procedure Create (var SP: StackPair; var created: boolean); {Izveido jaunu tukšu steka pāri SP^} begin new(SP); SP^.top[1]:= 0; SP^.top[2]:= MaxPlusOne; created:= true end; procedure Terminate (var SP: StackPair; var created: boolean); {Likvidē steka pāri SP^} begin if created then begin dispose (SP); created:= false end end; 1. steks 1 2. steks brīvā atmiņa top[1]top[2]MaxSize StackPairInstance SP: StackPair const MaxSize = 500; MaxPlusOne = MaxSize +1; type StackTop = 0.. MaxPlusOne ; StackNo = 1.. 2; {steka numurs } Position = 1.. MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; StackPairInstance = record top: array[StackNo] of StackTop; el: array[Position] of StdElement end; StackPair = ^StackPairInstance;

144
G.Matisons - "Datu struktūras", Rīga function Size (SP: StackPair; SNo: StackNo): StackTop; {Nosaka elementu skaitu steka pāra SP^ pirmajā vai otrajā stekā SNo} begin case SNo of 1: Size:= SP^.top[1]; 2: Size:= MaxSize - SP^.top[2] +1 end end; function Full (SP: StackPair): boolean; {Pārbauda, vai steka pāris SP^ ir pilns} begin Full:= SP^.top[1] + 1 = SP^.top[2] end; function Empty(SP: StackPair; SNo: StackNo): boolean; {Pārbauda, vai steka pārī SP^ steks SNo ir tukšs} begin case SNo of 1: Empty:= SP^.top[1] = 0; 2: Empty:= SP^.top[2] = MaxPlusOne end end;

145
G.Matisons - "Datu struktūras", Rīga procedure Push (var SP: StackPair; SNo: StackNo; e: Stdelement); {Steka pāra SP^ stekā SNo izvieto jaunu elementu e} begin if not Full(SP) then with SP^ do begin case SNo of 1: top[1]:= top[1] +1; 2: top[2]:= top[2] – 1 end; el[top[SNo]]:= e end end; procedure Pop (SP: StackPair; SNo: StackNo; var e: StdElement); {No steka pāra SP^ steka SNo nolasa elementu e} begin if not Empty (SP, SNo) then with SP^ do begin e:= el[top[SNo]]; case SNo of 1: top[1]:= top[1] -1 2: top[2]:= top[2] +1 end end;

146
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTS STEKS n top next el StackInstance S: Stack next elnext el Node n n nil const MaxSize = 500; type Count = 0.. MaxSize; Data Type = string; KeyType = integer; Stdelement = record data: DataType; key: KeyType end; Node = record el: StdElement; next: NodePointer end; NodePointer = ^Node; StackInstance = record top: NodePointer; n: Count end; Stack = ^StackInstance;

147
G.Matisons - "Datu struktūras", Rīga procedure Create (var S: Stack; var created: boolean); {Izveido jaunu tukšu steku S^} begin new(S); S^.top:= nil; S^.n:= 0; created:= true end; procedure Terminate (var S: Stack; var created: boolean); {Likvidē steku S^} var p: NodePointer; begin if created then with S^ do begin if not Empty(S) then while top <> nil do begin p:= top; top:= top^.next; dispose (p) end; dispose (S); created:= false end end; function Size (S: Stack): Count; {Nosaka elementu skaitu stekā S^} begin Size:= S^.n end;
nil do begin p:= top; top:= top^.next; dispose (p) end; dispose (S); created:= false end end; function Size (S: Stack): Count; {Nosaka elementu skaitu stekā S^} begin Size:= S^.n end;">

148
G.Matisons - "Datu struktūras", Rīga function Empty (S: Stack): boolean; {Pārbauda, vai steks S^ ir tukšs} begin Empty:= S^.top = nil {Empty:= S^.n = 0} end; function Full (S: Stack): boolean; {Pārbauda, vai steks S^ ir pilns} begin Full:= S^.n = MaxSize end; procedure Push (var S: Stack; e: StdElement); {Stekā S^ izvieto jaunu elementu e} var p: NodePointer; begin if not Full(S) then with S^ do begin new(p); p^.el:= e; if Empty(S) then {steks ir tukšs} begin top:= p; p^.next:= nil end else {steks nav tukšs} begin {izkārto saites} p^.next:= top; top:= p end; n:= n + 1 end end;

149
G.Matisons - "Datu struktūras", Rīga RINDA (Queue) procedure Pop (var S:Stack; var e: StdElement); {No steka S^ nolasa elementu e} var p: NodePointer; begin if not Empty(S) then with S^ do begin e:= top^.el; p:= top; top:= top^.next; dispose (p); n:= n -1 end Rinda ir lineāra datu struktūra, kas strādā pēc principa: FIFO – First-In / First-Out (Pirmais iekšā / Pirmais ārā) vai HPIFO – High Priority-In / First-Out. Parastajā rindā elementu apstrāde atkarīga no pievienošanas laika, prioritātes rindā – no elementa prioritātes lieluma. Rindu nepārtraukti var papildināt ar jauniem elementiem. Jaunu elementu pievieno rindas beigās (vai meklē elementam vietu prioritātes rindas gadījumā). No rindas nolasa to elementu, kas atrodas rindas sākumā. Pēc nolasīšanas elements rindā tiek dzēsts. Servisa operācijas: Create, Terminate, Size, Empty, Full. Pamatoperācijas: Enqueue, Serve (Dequeue). Rindas elementa tips: StdElement. Rindas tips: Queue. Rādītāji: head – norāda uz rindas sākumu (uz 1.elementu), tail – norāda uz rindas beigām (uz pēdējo elementu). Katram rindas elementam, izņemot pēdējo, ir pēctecis, kas kļūst par apkalpojamo rindā, ja tiek izpildīta operācija Serve.

150
G.Matisons - "Datu struktūras", Rīga VEKTORIĀLĀ FORMĀ ATTĒLOTA RINDA procedure Create (var Q: Queue; var created: boolean); {Izveido jaunu tukšu rindu Q^} begin new (Q); Q^.head:= 0; Q^.tail:= 0; Q^.n:= 0; created:= true; end; procedure Terminate (var Q: Queue; var created:boolean); {Likvidē rindu Q^} begin if created then begin dispose (Q); created:= false end end; el[1] el[2] Q: Queue const MaxSize = 500; {uzdod lietotājs} type Position = 1..MaxSize ; Count = 0..MaxSize; DataType = string; {uzdod lietotājs} KeyType = integer; StdElement = record data: DataType; key: KeyType end; QueueInstance = record head, tail, n: Count; el: array [Position] of StdElement end; Queue = ^QueueInstance ; el[n ]... QueueInstance head brīvās pozīcijas } tail n el[MaxSize]

151
G.Matisons - "Datu struktūras", Rīga function Size (Q: Queue): Count; {Nosaka elementu skaitu rindā Q^} begin Size:= Q^.n end; function Empty (Q: Queue): boolean; {Pārbauda, vai rinda Q^ ir tukša} begin Empty:= Q^.n = 0 {Q^.head = 0} end; function Full (Q: Queue): boolean; {Pārbauda, vai rinda Q^ ir pilna} begin Full:= Q^.n = MaxSize end; procedure Enqueue (var Q: Queue; e: StdElement); {Rindā Q^ izvieto jaunu elementu e} begin if not Full(Q) then wih Q^ do begin tail:= tail+1; {jaunā elementa pozīcija tail} el[tail]:= e; {elementu e izvieto rindā} if Empty(Q) then head:= 1; n:= n+1 end end;

0 then head:= head -1 {nolasīto el" title="G.Matisons - "Datu struktūras", Rīga 2003 152 procedure Serve (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} if not Empty(Q) then with Q^ do begin e:= el[head]; n:= n-1; {nolasa elementu} if n > 0 then head:= head -1 {nolasīto el" class="link_thumb">
152
G.Matisons - "Datu struktūras", Rīga procedure Serve (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} if not Empty(Q) then with Q^ do begin e:= el[head]; n:= n-1; {nolasa elementu} if n > 0 then head:= head -1 {nolasīto elementu dzēš} else {rinda kļuvusi tukša} begin head:= 0; tail:=0 end end; Operācijas Serve(Q,e) algoritma priekšrocība ir tā vienkāršība un efektivitāte. Būtisks trūkums ir tas, ka vektorā veidojas brīvas pozīcijas rindas sākumā. Ir divi paņēmieni šī trūkuma novēršanai: 1) nolasīto elementu rindā dzēst, visus elementus, sākot ar otro, pārsūtot pa vienu pozīciju virzienā un rindas sākumu: procedure Serve1 (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} var i: Position; begin if not Empty(Q) then with Q^ do begin e:= el[head]; {nolasa elementu} for i:= 2 to n do {nolasīto elementu dzēš} el[i-1]:= el[i]; n:= n -1; tail:= n; if tail = 0 then head:= 0 {rinda kļuvusi tukša} end end; 2) veidot cirkulāru rindu.
0 then head:= head -1 {nolasīto el">
0 then head:= head -1 {nolasīto elementu dzēš} else {rinda kļuvusi tukša} begin head:= 0; tail:=0 end end; Operācijas Serve(Q,e) algoritma priekšrocība ir tā vienkāršība un efektivitāte. Būtisks trūkums ir tas, ka vektorā veidojas brīvas pozīcijas rindas sākumā. Ir divi paņēmieni šī trūkuma novēršanai: 1) nolasīto elementu rindā dzēst, visus elementus, sākot ar otro, pārsūtot pa vienu pozīciju virzienā un rindas sākumu: procedure Serve1 (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} var i: Position; begin if not Empty(Q) then with Q^ do begin e:= el[head]; {nolasa elementu} for i:= 2 to n do {nolasīto elementu dzēš} el[i-1]:= el[i]; n:= n -1; tail:= n; if tail = 0 then head:= 0 {rinda kļuvusi tukša} end end; 2) veidot cirkulāru rindu.">
0 then head:= head -1 {nolasīto el" title="G.Matisons - "Datu struktūras", Rīga 2003 152 procedure Serve (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} if not Empty(Q) then with Q^ do begin e:= el[head]; n:= n-1; {nolasa elementu} if n > 0 then head:= head -1 {nolasīto el">

153
G.Matisons - "Datu struktūras", Rīga CIRKULĀRA RINDA Var atzīmēt, ka 1) ja strādā ar rindu, tā vektorā virzās no zemākas pozīcijas uz augstāku pozīciju; 2) rindai virzoties uz priekšu, tās paplašināšanās vai samazināšanās ir atkarīga no operāciju Enqueue un Serve izpildes skaita un secības. Rinda pēc kāda laika, kad operācija Serve izpildīta daudz biežāk nekā operācija Enqueue: Situācija, kad rinda aizvirzījusies līdz vektora beigām – rinda ir pilna, bet faktiski brīvā atmiņa izveidojusies vektora sākumā: Rinda Brīvās pozīcijas 1. pozīcija head šeit nolasa tail šeit pievieno MaxSize Rinda pēc tās izveidošanas: Brīvās pozīcijas Rinda head1. pozīcijatailMaxSize Brīvās pozīcijas Rinda 1. pozīcijahead tail MaxSize

154
G.Matisons - "Datu struktūras", Rīga Rindas pārpildes novēršana: 1) rindas pārbīde uz vektora sākumu. Tā ir 0(n) kārtas operācija. Neefektīvs paņēmiens, pārbīde var būt bieži nepieciešama; 2) veidot cirkulāru rindu, kurā rindas gals pārvietojas uz vektora sākumu (tail atrodas zemāko pozīciju rajonā): Šai gadījumā rindai iedalītais atmiņas apgabals kļūst cirkulārs – rinda pārvietojas pa noslēgtu cirkulāru atmiņas apgabalu: Cirkulārai rindai ir tāds pats modelis un modeļa apraksts kā parastai vektoriālā formā attēlotai rindai. Rindas cirkulārumu realizē nevis ar rindas aprakstu, bet gan ar operācijām Create, Enqueue, Serve. Pārējās operācijas ir tādas pašas kā parastai vektoriālā formā attēlotai rindai. Rindas beigu daļaRindas sākumdaļa Brīvās pozīcijas head1. pozīcijatail MaxSize R i n d a B r ī v ā s p o z ī c i j a s head tail MaxSize1. pozīcija

155
G.Matisons - "Datu struktūras", Rīga procedure Create (var Q: Queue; var created: boolean); {izveido jaunu tukšu cirkulāru rindu Q^} begin new (Q); with Q^ do begin head:= 1; tail:= MaxSize; n:= 0 end; created:= true end; procedure Enqueue (var Q: Queue; e: StdElement); {Cirkulārā rindā Q^ izvieto jaunu elementu e} begin if not Full(Q) then with Q^ do begin tail:= (tail mod MaxSize) + 1; {pozīcija tail} el[tail]:= e; {izvieto elementu pozīcijā tail} if Empty(Q) then head:= 1; n:= n +1 end end; procedure Serve (var Q: Queue; var e: StdElement); {No cirkulāras rindas Q^ nolasa elementu e} begin if not Empty(Q) then with Q^ do begin e:= el[head]; {nolasa elementu} head:= (head mod MaxSize) +1; {pozīcija head} n:= n -1; if Empty(Q) then tail:= MaxSize end end;

156
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTA RINDA const MaxSize = 500; type Count = 0.. MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Node = record el: StdElement; next: NodePointer end; NodePointer = ^Node; QueueInstance = record head: NodePointer; tail: NodePointer; n: Count end; Queue = ^QueueInstance; el next nil head Node n 1 n 2... Q: Queue QueueInstance tail

157
G.Matisons - "Datu struktūras", Rīga procedure Create (var Q: Queue; var created: boolean); {Izveido jaunu tukšu rindu Q^} begin new(Q); with Q^ do begin head:= nil; tail:= nil; n:=0 end; created:= true end; procedure Terminate (var Q: Queue; var created: boolean); {Likvidē rindu Q^} var p: NodePointer; begin if created then begin if not Empty(Q) then with Q^ do while head <> nil do begin p:= head; head:= head.^next; dispose (p) end; dispose(Q); created:= false end end; function Size (var Q: Queue): Count; {Nosaka elementu skaitu rindā Q^} begin Size:= Q^.n end;
nil do begin p:= head; head:= head.^next; dispose (p) end; dispose(Q); created:= false end end; function Size (var Q: Queue): Count; {Nosaka elementu skaitu rindā Q^} begin Size:= Q^.n end;">

158
G.Matisons - "Datu struktūras", Rīga function Empty (Q: Queue): boolean; {Pārbauda, vai rinda Q^ ir tukša} begin Empty:= Q^.n = 0; {Q^.head = nil} end; function Full (Q: Queue): boolean; {Pārbauda, vai rinda Q^ ir pilna} begin Full:= Q^.n = MaxSize end; procedure Enqueue (var Q: Queue; e: StdElement); {Rindā Q^ izvieto jaunu elementu e} var p: NodePointer; begin if not Full(Q) then with Q^ do begin new(p); p^.el:= e; if Empty(Q) then {rinda ir tukša} begin head:= p; tail:= p; p^.next:= nil end else {rinda nav tukša} begin {izkārto 2 saites} p^.next:= tail^.next; tail^.next:= p; tail:=p end; n:= n +1 end end;

159
G.Matisons - "Datu struktūras", Rīga procedure Serve (var Q: Queue; var e: StdElement); {No rindas Q^ nolasa elementu e} var p: NodePointer; begin if not Empty(Q) then with Q^ do begin p:= head; e:= head^.el; {nolasa elementu} head:= head^.next; {pārstata radītāju head} if n = 1 then tail:= nil; dispose (p); {dzēš nolasīto elementu} n:= n -1 end end;

160
G.Matisons - "Datu struktūras", Rīga PRIORITĀTES RINDA Darbības princips: HPIFO - High Priority In / First Out (ar Augstu prioritāti iekšā / Pirmais ārā). Prioritātes rindas galvenokārt izmanto notikumu reģistrēšanas un apkalpošanas sistēmās. VEKTORIĀLĀ FORMĀ ATTĒLOTA PRIORITĀTES RINDA Priority: integer; data key prty : Priority : KeyType : DataType el[i] => StdElement Elementa uzbūve: i = 1, 2,..., n el [1] el [2] PQ: PriorityQueue const MaxSize = 500; {uzdod liet.} type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string ; KeyType = integer; StdElement = record data: DataType ; key: KeyType end; head, tail, n: Count ; el: array [Position] of StdElement end; prty: Priority PriorityQueue = record PriorityQueue = ^PriorityQueueInstance; el [n]... PriorityQueueInstance head tail n el [MaxSize]
StdElement Elementa uzbūve: i = 1, 2,..., n el [1] el [2] PQ: PriorityQueue const MaxSize = 500; {uzdod liet.} type Position = 1.. MaxSize; Count = 0.. MaxSize; DataType = string ; KeyType = integer; StdElement = record data: DataType ; key: KeyType end; head, tail, n: Count ; el: array [Position] of StdElement end; prty: Priority PriorityQueue = record PriorityQueue = ^PriorityQueueInstance; el [n]... PriorityQueueInstance head tail n el [MaxSize]">

161
G.Matisons - "Datu struktūras", Rīga procedure Enqueue (var PQ: PriorityQueue; e: StdElement); {Prioritātes rindā PQ^ izvieto jaunu elementu e} var i, k: Position; begin if not Full(PQ) then with PQ^ do begin if Empty(PQ) then {prioritātes rinda ir tukša} begin head:= 1; el[head]:= e; tail:= head end else {elementam meklē vietu} for i:= n downto 1 do if el[i].prty > e.prty then begin {izvieto aiz i-tā elementa} for k:= n downto i + 1 do el[k+1]:= el[k]; el[i+1]:= e; break end; if i = n then tail:= tail +1; n:= n +1 end end;
e.prty then begin {izvieto aiz i-tā elementa} for k:= n downto i + 1 do el[k+1]:= el[k]; el[i+1]:= e; break end; if i = n then tail:= tail +1; n:= n +1 end end;">

162
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTA PRIORITĀTES RINDA procedure Serve (var PQ: PriorityQueue; var e: StdElement); {No prioritātes rindas PQ^ nolasa elementu e} var i: Position; begin if not Empty(PQ) then with PQ^ do begin e:= el[head]; {nolasa elementu} for i:= 2 to n do el[i-1]:= el[i]; {nolasīto elementu dzēš} n:= n -1; tail:= n; if tail = 0 then head:= 0 end end; const MaxSize = 500 ; type Count = 0..MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType Priority = integer; end; Node = record el: StdElement; prty: Priority; next: NodePointer; prior: NodePointer end; NodePointer = ^Node; PriorityQueueInstance = record head: NodePointer tail: NodePointer; n: Count end; PriorityQueue = ^PriorityQueueInstance; el prty prior tail PQ: PriorityQueue PriorityQueueInstance... Node 1 2 n head n nil next nil

163
G.Matisons - "Datu struktūras", Rīga procedure Enqueue(var PQ: PriorityQueue; pr: Priority; e: StdElement); {Prioritātes rindā PQ^ izvieto jaunu elementu e} var p, q: NodePointer; begin if not Full(PQ) then with PQ^ do begin new(p); p^.el:= e; p^.prty:= pr; if Empty(PQ) then {prioritātes rinda ir tukša} begin head:= p; tail:=p; p^.next:= nil; p^.prior:= nil end else {elementam meklē vietu} if head^.prty < pr then {izvieto pirms 1.elementa} begin p^.next:= head; p^.prior:= nil; head^.prior:= p; head:= p end else begin {izvieto vidusposmā aiz pirmā elementa} q:= tail; while (q^.prty nil) do q:= q^.prior; p^.next:= q^.next; p^.prior:= q; if q <> tail then q^.next^.prior:= p else tail:= p; q^.next:= p end; n:= n +1 end end;
tail then q^.next^.prior:= p else tail:= p; q^.next:= p end; n:= n +1 end end;">
164
G.Matisons - "Datu struktūras", Rīga procedure Serve (var PQ: PriorityQueue; var pr: Priority; var e: StdElement); {No prioritātes rindas PQ^ nolasa elementu e} var p: NodePointer; begin if not Empty(PQ) then with PQ^ do begin p:= head; e:= head^.el; pr:= head^.prty; {nolasa elementu} if n = 1 then {prioritātes rinda kļūs tukša} begin head:= nil; tail:= nil end else {prioritātes rindā ir vairāki elementi} begin {nolasīto elementu dzēš} head^.next^.prior:= nil; head:= head^.next end; dispose (p); n:= n -1 end end;
165
G.Matisons - "Datu struktūras", Rīga DEKS – RINDA AR DIVIEM GALIEM VEKTORIĀLĀ FORMĀ ATTĒLOTS DEKS Push Pop... Steks : Enqueue... Rinda: Serve Enqueue... Deks : Serve Enqueue Serve Svarīgs parametrs - rindas gala numurs el [1] el [2] D: Deque const MaxSize = 500; type Position = 1.. MaxSize; Count = 0.. MaxSize; No StdElement = record data: DataType; key: KeyType end; DequeInstance = record head, tail, n: Count; el: array [Position] of StdElement end; Deque = ^DequeInstance; DataType = string; KeyType = integer; = 1.. 2; ; el [n]... DequeInstance head tail n el [MaxSize]

166
G.Matisons - "Datu struktūras", Rīga procedure Enqueue (var D: Deque; e: StdElement; DNo: No); {Dekā D^ izvieto jaunu elementu e} var i: Position; begin if not Full(D) then with D^ do if Empty(D) then {vienalga, kurā galā izvietot} begin head:= 1; tail:= 1; el[head]:= e; n:= n+1 end else case DNo of 1: begin {elementu izvieto deka sākumā} for i:= tail downto head do el[i+1]:= el[i]; el[head]:= e; n:= n +1; tail:= n; end; 2: begin {elementu izvieto deka galā} n:= n +1; tail:= n; el[tail]:= e end end;

167
G.Matisons - "Datu struktūras", Rīga procedure Serve (var D: Deque; var e: StdElement; DNo: No); {No deka D^ nolasa elementu e) var i: Position; begin if not Empty(D) then with D^ do if n = 1 then begin e:= el[head]; {nolasa elementu} head:= 0; tail:= 0; {deks kļūs tukšs} n:= 0 end else case DNo of 1: begin {elementu nolasa deka sākumā} e:= el[head]; for i:= 2 to n do {nolasīto elementu dzēš} el[i-1]:= el[i]; n:= n -1; tail:= n end; 2: begin {elementu nolasa deka galā} e:= el[tail]; n:= n -1; tail:= n {nolasīto elementu dzēš} end end;
168
G.Matisons - "Datu struktūras", Rīga SAISTĪTĀ FORMĀ ATTĒLOTS DEKS el next prior tail D: Deque... Node 1 2 n head n nil DequeInstance const MaxSize = 500; type Count = 0.. MaxSize; DataType = string; KeyType = integer; No = 1..2; StdElement = record data: DataType; key: KeyType; end; Node = record el: StdElement; next: NodePointer; prior: NodePointer end; NodePointer = ^Node; DequeInstance = record head: NodePointer; tail: NodePointer; n: Count end; Deque = ^DequeInstance;
169
G.Matisons - "Datu struktūras", Rīga procedure Enqueue (var D: Deque; e: StdElement; DNo: No); {Dekā D^ izvieto jaunu elementu e} var p: NodePointer; begin if not Full(D) then with D^ do begin new (p); p^.el:= e; if Empty(D) then {vienalga, kurā galā izvietot} begin p^.next:= nil; p^.prior:= nil; head:= p; tail:= p end else begin case DNo of 1: begin {elementu izvieto deka sākumā} p^.prior:= nil; p^.next:= head; head^.prior:= p; head:=p end; 2: begin {elementu izvieto deka galā} p^.next:= nil; p^.prior:= tail; tail^.next:= p; tail:= p end end; n:= n +1 end end;

170
G.Matisons - "Datu struktūras", Rīga procedure Serve (var D: Deque; var e: StdElement; DNo: No); {No deka D^ nolasa elementu e} var p: NodePointer; begin if not Empty(D) then with D^ do begin if n = 1 then {deks kļūs tukšs} begin p:= head; head:= nil; tail:= nil end else case DNo of 1: begin {elements tiks nolasīts deka sākumā} p:= head; {izkārto saites} head^.next^.prior:= nil; head:= head^.next end; 2: begin {elements tiks nolasīts deka galā} p:= tail; {izkārto saites} tail^.prior^.next:= nil; tail:= tail^.prior end; e:= p^.el; {nolasa elementu} dispose (p); {nolasīto elementu dzēš} n:= n – 1 end end;

171
G.Matisons - "Datu struktūras", Rīga KOKS (tree) JEB HIERARHISKA DATU STRUKTŪRA Koks ir nelineāra struktūra, kurā elementu sasaistes raksturs ir viens-ar-vairākiem (one-to-many). Elementu tips: StdElement Termini: kreisais bērns – left child labais bērns – right child vecāks – parient brāļi – siblings sencis – ancestor pēcnācējs – descendant vienkāršais ceļš – simple path A B C DE F G šķautne ( edge) saknes virsotne (root node) lapas (leaves) lapa (leaf)

172
G.Matisons - "Datu struktūras", Rīga Ja virsotņu skaits ir n, tad šķautņu skaits q = n – 1. Ceļa garums (path length) katram vienkāršajam ceļam ir vienāds ar virsotņu skaitu šai ceļā. vienkāršais ceļš: A-B-C-E, tā garums ir 4; vienkāršais ceļš: A-B-D-G- I, tā garums ir 5; vienkāršais ceļš: G-I, tā garums ir 2. Kāda virsotne kopā ar visiem tās pēcnācējiem veido apakškoku (subtree): Viena virsotne kokā vienmēr ir tekošā (current). Koku klasifikācija: 1) binārie koki: a) binārās meklēšanas koki; b) sabalansētie koki (AVL koki, sarkanmelnie koki u.c.); c) kaudzes (heap). 2) B - koki. A D F G C E B H I D F G G C E H H I I

173
G.Matisons - "Datu struktūras", Rīga Koka raksturlielumi: 1) virsotņu skaits (size); 2) virsotnes pakāpe (height) ir tās pēcteču skaits; 3) virsotnes līmenis jeb dziļums (level). Saknes līmenis ir 1, katra bērna līmenis ir par 1 lielāks kā vecāka līmenis; 4) vidējā ceļa garums (avePath).

174
G.Matisons - "Datu struktūras", Rīga Operācijas: 1) apkalpošanas operācijas: Create, Terminate, TreeDispose, Characteristics, Empty, Full; 2) meklēšanas operācijas: Find, FindParient, FindKey; 3) pamatoperācijas: Traverse, Insert, Delete, DeleteSub, Retrieve, Update. Binārais koks: 1) katrai virsotnei nevar būt vairāk kā 2 apakškoki un tādējādi – ne vairāk kā 2 pēcnācēji; 2) katrs apakškoks ir identificējams kā vecāka virsotnes kreisais apakškoks vai kā labais apakškoks; 3) koks var būt tukšs. Rekursīvā binārā koka definīcija: Binārais koks ir vai nu tukšs, vai arī to veido saknes virsotne un divi neatkarīgi binārie koki. Tie ir savā savā nesaistīti, un tos sauc par kreiso un labo apakškoku. Operācijā Characteristics tiek noteikti 3 binārā koka raksturlielumi, izmantojot inorderālo apgaitu: 1) virsotņu skaits binārajā kokā (size); 2) binārā koka pakāpe (height); 3) vidējā ceļa garums (avePath) – visu ceļu summa no saknes virsotnes līdz citai virsotnei, dalīta ar šādu ceļu kopskaitu binārajā kokā.

175
G.Matisons - "Datu struktūras", Rīga Binārā KOKA ATTĒLOJUMS SAISTĪTĀ FORMĀ const MaxSize = 500; type Count = 0.. MaxSize; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Status = record size: Count; height: Count; avePath: real end; Edit = 1.. 3; Order = (preOrder, inOrder, postOrder); Relative = (leftCild, rightChild, root, parient); Node = record el: StdElement; left, right: NodePointer end; NodePointer = ^Node; BinaryTreeInstance = record treeRoot: NodePointer; current: NodePointer; St: Status end; BinaryTree = ^BinaryTreeInstance; left nil elright nil treeRoot current St: Status BT: BinaryTree BinaryTreeInstanceNode

176
G.Matisons - "Datu struktūras", Rīga Binārie koki ar 3 virsotnēm: 5 dažādas konfigurācijas Virsotņu skaits 1234 Bināro koku skaits Virsotņu skaits Bināro koku skaits Binārā koka apgaita Binārā koka apgaita (traverse – apgaita, traverss) ir tāda binārā koka virsotņu secība, kurā katra virsotne sastopama tikai vienu reizi. Ja binārajā kokā ir n virsotnes, tad iespējamo apgaitu skaits ir n! Visbiežāk lieto tikai 3 dabiskāko apgaitu algoritmus: preorderālo, postorderālo un inorderālo binārā koka virsotņu apgaitu.

177
G.Matisons - "Datu struktūras", Rīga A CB D E F Preorderālā apgaita: A, B, D, C, E, F. Inorderālā apgaita: B, D, A, E, C, F. Postorderālā apgaita: D, B, E, F, C, A. Apskatīsim, kāds būtu izteiksmes (a+b) * (c-d) attēlojums binārā koka veidā un kāda virsotņu apgaita būtu jāizvēlas, izteiksmi izskaitļojot. * -+ b c d a Preorderālā apgaita: *, +, a, b, -, c, d. Inorderālā apgaita: a, +, b, *, c, -, d. Postorderālā apgaita: a, b, +, c, d, -, *. Šāda veida bināros kokus sauc par izteiksmju kokiem. Kompilatori ģenerē sintaktiskās analīzes kokus izteiksmju vērtību aprēķināšanai, izmantojot postorderālo apgaitu un stekus.

178
G.Matisons - "Datu struktūras", Rīga Binārā koka virsotņu apgaitas operāciju Traverse visērtāk realizēt rekursīvi, izmantojot iekšējās procedūras PreOrd, InOrd un PostOrd un ārējas procedūras Proc izsaukumu. Procedūra Proc paredzēta viena virsotnes elementa apstrādei, piemēram, lauku data un key izvadei ekrānā koka apgaitas procesā. procedure Traverse ( BT: BinaryTree; ord:Order); {Binārā koka virsotņu apgaita, izvēloties apgaitas paņēmienu} procedure PreOrd (p: NodePointer; level: Count); begin if p <> nil then begin Proc(p^.el, level); PreOrd(p^.left, level+1); PreOrd(p^.right, level+1) end end; procedure InOrd (p: NodePointer; level: Count); begin if p <> nil then begin InOrd(p^.left, level+1); Proc(p^.el, level); InOrd(p^.right, level+1) end end; procedure PostOrd (p: NodePointer; level: Count); begin if p <> nil then begin PostOrd(p^.left, level+1); PostOrd(p^.right, level+1 Proc(p^.el, level) end end; begin {darbības sfēra} case ord of: preOrd: PreOrd(BT^.treeRoot, 1); inOrd: InOrd(BT^.treeRoot, 1); postOrd: PostOrd(BT^.treeRoot, 1) end {case} end;
nil then begin Proc(p^.el, level); PreOrd(p^.left, level+1); PreOrd(p^.right, level+1) end end; procedure InOrd (p: NodePointer; level: Count); begin if p <> nil then begin InOrd(p^.left, level+1); Proc(p^.el, level); InOrd(p^.right, level+1) end end; procedure PostOrd (p: NodePointer; level: Count); begin if p <> nil then begin PostOrd(p^.left, level+1); PostOrd(p^.right, level+1 Proc(p^.el, level) end end; begin {darbības sfēra} case ord of: preOrd: PreOrd(BT^.treeRoot, 1); inOrd: InOrd(BT^.treeRoot, 1); postOrd: PostOrd(BT^.treeRoot, 1) end {case} end;">

179
G.Matisons - "Datu struktūras", Rīga procedure Create (var BT: BinaryTree; var created: boolean); {Izveido jaunu un tukšu bināro koku BT^} begin new(BT); with BT^ do begin treeRoot:= nil; current:=nil; St.size:= 0; St.height:= 0; St.avePath:= 0 end; created:= true end; procedure Terminate (var BT: BinaryTree; var created: boolean); {Likvidē bināro koku BT^} begin if created then begin TreeDispose(BT, BT^.treeRoot); dispose(BT); created:= false end end; function Empty (BT: BinaryTree): boolean; {Pārbauda, vai binārais koks BT^ ir tukšs} begin Empty:= BT^.treeRoot=nil end; functionFull (BT: BinaryTree): boolean; {Pārbauda, vai binārais koks BT^ ir pilns} begin Full:= BT^.ST.size=MaxSize end;

nil then begin InOrde" title="G.Matisons - "Datu struktūras", Rīga 2003 180 procedure Characteristics (BT: BinaryTree); {Nosaka binārā koka BT^ raksturlielumus} var ht, sz: Count; ap, tpl: real: procedure InOrder (p: NodePointer; level: Count); begin if p <> nil then begin InOrde" class="link_thumb">
180
G.Matisons - "Datu struktūras", Rīga procedure Characteristics (BT: BinaryTree); {Nosaka binārā koka BT^ raksturlielumus} var ht, sz: Count; ap, tpl: real: procedure InOrder (p: NodePointer; level: Count); begin if p <> nil then begin InOrder(p^.left, level+1); sz:= sz+1; tpl:= tpl+level; if ht < level then ht:= level; InOrder(p^.right, level+1) end end; begin sz:= 0; ht:=0; tpl:= 0; with BT^ do begin if not Empty(BT) then begin InOrd(treeRoot, 1); ap:= tpl / sz end else ap:= 0; St.size:= sz; St.height:= ht; St.avePath := ap end end;
nil then begin InOrde">
nil then begin InOrder(p^.left, level+1); sz:= sz+1; tpl:= tpl+level; if ht < level then ht:= level; InOrder(p^.right, level+1) end end; begin sz:= 0; ht:=0; tpl:= 0; with BT^ do begin if not Empty(BT) then begin InOrd(treeRoot, 1); ap:= tpl / sz end else ap:= 0; St.size:= sz; St.height:= ht; St.avePath := ap end end;">
nil then begin InOrde" title="G.Matisons - "Datu struktūras", Rīga 2003 180 procedure Characteristics (BT: BinaryTree); {Nosaka binārā koka BT^ raksturlielumus} var ht, sz: Count; ap, tpl: real: procedure InOrder (p: NodePointer; level: Count); begin if p <> nil then begin InOrde">

181
G.Matisons - "Datu struktūras", Rīga procedure FindParent (BT: BinaryTree); {Binārajā kokā BT^ sameklē tekošās virsotnes vecāku, kas kļūst par tekošo virsotni} var p: NodePointer; S: Stack; ok: boolean; begin if (not Empty(BT)) and (BT^. current <> BT^.treeRoot) then begin StackCreate(S, ok); {izveido steku nerekursīvai apgaitai} with BT^ do {nerekursīva apgaita} begin p:= treeRoot; while (p^.left <. current) and (p^.right <. current) do begin if p^.right <> nil then Push(S, p^.right); if p^.left <> nil then p:= p^.left else Pop(S, p) end; current:= p end; StackTerminate(S, ok) end end;
BT^.treeRoot) then begin StackCreate(S, ok); {izveido steku nerekursīvai apgaitai} with BT^ do {nerekursīva apgaita} begin p:= treeRoot; while (p^.left <. current) and (p^.right <. current) do begin if p^.right <> nil then Push(S, p^.right); if p^.left <> nil then p:= p^.left else Pop(S, p) end; current:= p end; StackTerminate(S, ok) end end;">

182
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var BT: BinaryTree; tkey: KeyType; { var found: boolean); {Binārajā kokā BT^ meklē virsotni, kuras atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētā virsotne kļūst par tekošo} var p: NodePointer; procedure PreOrd (p: NodePointer; level: Count); begin if (p <> nil) and (not found) then begin if p^.el.key = tkey then begin current:= p; found:= true end PreOrd(p^.left, level+1); PreOrd(p^.right, level+1) end end end; begin {darbības sfēra} found:=false; if not Empty(BT) then with BT^ do begin p := treeRoot; PreOrd(p,1) end;
nil) and (not found) then begin if p^.el.key = tkey then begin current:= p; found:= true end PreOrd(p^.left, level+1); PreOrd(p^.right, level+1) end end end; begin {darbības sfēra} found:=false; if not Empty(BT) then with BT^ do begin p := treeRoot; PreOrd(p,1) end;">

183
G.Matisons - "Datu struktūras", Rīga procedure Find (var BT: BinaryTree; rel: Relative; var found: boolean); {Binārajā kokā BT^ meklē tekošās virsotnes radinieku rel. Ja meklēšana ir sekmīga, sameklētā virsotne kļūst par tekošo} begin found:= true; IF NOT Empty(BT^) then with BT^ do begin case rel of root: current:= treeRoot; leftChild: if current^.left <> nil then current:= current^.left else found:= false; rightChild: if current^.right <> nil then current:= current^.right else found:= false; parent: if current <> treeRoot then FindParent(BT) else found:= false end {case} end end; procedure TreeDispose(var BT: BinaryTree; p: NodePointer); {Apakškokā ar sakni p^ dzēš visas virsotnes, izmantojot postorderālo apgaitu} begin if p <> nil then {ja p norāda uz kādu virsotni} begin TreeDispose(BT, p^.left); {dzēš kreiso apakškoku} TreeDispose(BT, p^.right); {dzēš labo apakškoku} dispose(p) {dzēš pašu virsotni p^} end end;
nil then current:= current^.left else found:= false; rightChild: if current^.right <> nil then current:= current^.right else found:= false; parent: if current <> treeRoot then FindParent(BT) else found:= false end {case} end end; procedure TreeDispose(var BT: BinaryTree; p: NodePointer); {Apakškokā ar sakni p^ dzēš visas virsotnes, izmantojot postorderālo apgaitu} begin if p <> nil then {ja p norāda uz kādu virsotni} begin TreeDispose(BT, p^.left); {dzēš kreiso apakškoku} TreeDispose(BT, p^.right); {dzēš labo apakškoku} dispose(p) {dzēš pašu virsotni p^} end end;">

184
G.Matisons - "Datu struktūras", Rīga procedure Insert (var BT: BinaryTree; e: StdElement; rel: Relative; var inserted: boolean); {Binārajā kokā BT^ aiz tekošās virsotnes radinieka izvieto jaunu virsotni e, kas kļūst par tekošo virsotni} var p: NodePointer; begin if not Full(BT) then with BT^ do begin if (rel = leftChild) and current^.left <> nil) then inserted:= false else begin new(p); inserted:= true; p^.el:= e; p^.left:= nil; p^.right:= nil; case rel of root: if Empty(BT) then treeRoot:= p else inserted:= false; leftChild: current^.left:= p; rightChild: current^.right:= p end {case}; current:= p; Characteristics(BT) end end; procedure Retrieve (BT: BinaryTree; var e: Stdelement); {Binārajā kokā BT^ nolasa tekošās virsotnes saturu} begin if not Empty(BT) then e:= BT^.current^.el end;
nil) then inserted:= false else begin new(p); inserted:= true; p^.el:= e; p^.left:= nil; p^.right:= nil; case rel of root: if Empty(BT) then treeRoot:= p else inserted:= false; leftChild: current^.left:= p; rightChild: current^.right:= p end {case}; current:= p; Characteristics(BT) end end; procedure Retrieve (BT: BinaryTree; var e: Stdelement); {Binārajā kokā BT^ nolasa tekošās virsotnes saturu} begin if not Empty(BT) then e:= BT^.current^.el end;">

185
G.Matisons - "Datu struktūras", Rīga procedure DeleteSub (var BT: BinaryTree); {Bināraja kokā BT^ dzēš tekošās virsotnes apakškoku un saknes virsotne kļūst par tekošo virsotni} var p: NodePointer; ok: boolean; begin if not Empty(BT) then with BT^ do begin if current = treeRoot then {koks kļūs tukšs} begin TreeDispose(BT, current); treeRoot:= nil; current:= nil; St.size:=0; St.height:=0; St.avePath:=0 end else { saknes virsotne nav tekošā} begin p:= current; Find(BT, parent, ok); {sameklē vecāku} if current^.left = p then current^.left:= nil else current^right:= nil end; TreeDispose(BT, p); {dzēš apakškoku p^} current:= treeRoot; Characteristics(BT) end

186
G.Matisons - "Datu struktūras", Rīga procedure Update (var BT: BinaryTree; e: Stdelement; k:Edit); {Binārajā kokā BT^ labo tekošās virsotnes elementa saturu saskaņā ar labošanas variantu k} begin if not Empty(BT) then with BT^ do case k of 1: current^.el.data:= e.data; 2: urrent^.el.key:= e.key; 3: current^.el:= e end {case} end; BINĀRĀ KOKA ATTĒLOJUMS VEKTORIĀLĀ FORMĀ Attēlojums vektoriālā formā ir saistīts ar vairākiem trūkumiem, kas piemīt šim attēlojuma paņēmienam;: 1) tā ka iepriekš grūti paredzēt virsotņu skaitu binārajā kokā, strādājot ar to, tad jārezervē pietiekami liels brīvās atmiņas apgabals vektora beigās jaunu virsotņu pievienošanai, tādējādi pamatatmiņas izmantošana nav ekonomiska un efektīva; 2) operāciju Insert un Delete izpilde saistīta ar elementu pārvietošanu vektorā, kas operācijas izpildes laiku paildzina un mazina veiktspēju. Šo iemeslu dēļ parasti bināros kokus attēlo saistītā formā. Attēlojot bināros kokus vektoriālā formā, sķautnes attēlo ar indeksu vērtībām nevis ar rādītājiem. Ir 3 pamatpaņēmieni, kā bināro koku attēlot vektoriālā formā.

187
G.Matisons - "Datu struktūras", Rīga const MaxSize = 500; type Position = 1.. MaxSize; Count = 0.. MaxSize; Edge = Count; DataType = string; KeyType = integer; StdElement = record data: DataType; key: KeyType end; Status = record size: Count; height: Count; avePath: real end; Edit = 1.. 3; Order = (preOrder, inOrder, postOrder); Relative = (leftCild, rightChild, root, parient); Node = record el: StdElement; left, right: Edge end; NodePointer = ^Node; BinaryTreeInstance = record el: array [Position] of Node; current: Edge; St: Status end; BinaryTree = ^BinaryTreeInstance; Piemēram:

188
G.Matisons - "Datu struktūras", Rīga IndekssVirsotneKreisāLabā 1A23 2B45 3C00 4D00 5E60 6F70 7G00 Binārā koka vektors BinaryTree^.el: Otrā metode paredz, ka binārā koka virsotnes vektorā tiek izvietas atbilstoši kādai virsotņu apgaitas secībai. Lai to ilustrētu, visvienkāršāk izvēlēties preorderālo apgaitu, kura sākas ar saknes virsotni. Katram virsotnes elementam papildis tiek pievienoti tikai 2 baiti loģiskās informācijas: vērtība true uzdod, ka kārtējā virsotne ir kāda vecāka kreisais bērns, bet vērtība false, ka tā ir labais bērns. Binārā koka attēlojuma modeļa apraksts tāds pats kā pirmajā paņēmienā, izņemot virsotnes aprakstu:... Node = record el: StdElement; left, right: boolean end; NodePointer = ^Node;...

189
G.Matisons - "Datu struktūras", Rīga IndekssVirsotneKreisāLabā 1Atrue 2B 3Dfalse 4Etruefalse 5Ftruefalse 6G 7C Binārā koka vektors BinaryTree^.el: Trešā metode paredz, ka binārā kokā šķautnes tiek attēlotas netieši. Katrai virsotnei tiek piešķirta pozīcija pēc tā paša paņēmiena, kā veidojot kaudzi. Binārā koka i-tās virsotnes kreisā bērna pozīcijas numurs ir 2i, bet labā bērna pozīcijas numurs ir 2i+1. Ja kāds no šiem bērniem attiecīgajā līmenī kokā nav, vieta vektorā paliek tukša.

190
G.Matisons - "Datu struktūras", Rīga BINĀRĀS MEKLĒŠANAS KOKS (binary search tree) Par binārās meklēšanas koku sauc tādu bināro koku, kurā katrai virsotnei V ir spēkā šādi nosacījumi: 1) ja virsotne L ir virsotnes V kreisā apakškoka virsotne, tad L < V; 2) ja virsotne R ir virsotnes V labā apakškoka virsotne, tad R > V. Ja V ir binārās meklēšanas koka virsotne, tad visas virsotnes tā kreisajā apakškokā ir mazākas par V, bet visas virsotnes tā labajā apakškokā ir lielākas par V
V. Ja V ir binārās meklēšanas koka virsotne, tad visas virsotnes tā kreisajā apakškokā ir mazākas par V, bet visas virsotnes tā labajā apakškokā ir lielākas par V. 35 50 7020 10 30 45 60 55 65">

191
G.Matisons - "Datu struktūras", Rīga Virsotnes binārajā meklēšanas kokā ir sakārtotas pēc virsotnes atslēgas lauka key vērtībām. Viena no virsotnēm binārajā meklēšanas kokā, ja tas nav tukšs, vienmēr ir tekošā virsotne. Tekošo virsotni iestata meklēšanas operācijas FindKey, Find un FindParent, kā arī pamatoperācijas Insert un Delete. Bināro meklēšanas koku parati attēlo saistītā formā. Binārās meklēšanas koka modeļa apraksts ir tāds pats kā parastajā binārajā kokā, mainīts tiek tikai binārā meklēšanas koka tipa nosaukums Binary SearchTree:... BinarySearchTreeInstance = record treeRoot: NodePointer; current: NodePointer; St: Status end; BinarySearchTree = ^BinarySearchTreeInstance; Salīdzinājumā ar parasto bināro koku, atšķirīgi būs tikai operāciju FindKey, Insert, Delete un Update algoritmi. Binārā meklēšanas koka konfigurācija ir atkarīga no tā, kādā secībā un ar kādām jaunās virsotnes atslēgas lauka vērtībām tiek izpildīta operācija Insert.

192
G.Matisons - "Datu struktūras", Rīga Create(BST, created); Insert(BST, 10, inserted); Insert(BST, 20, inserted); Insert(BST, 30, inserted); Insert(BST, 40, inserted); Insert(BST, 50, inserted); Insert(BST, 60, inserted); Piemēram: Create(BST, created); Insert(BST, 40, inserted); Insert(BST, 20, inserted); Insert(BST, 50, inserted); Insert(BST, 10, inserted); Insert(BST, 30, inserted); Insert(BST, 60, inserted);

193
G.Matisons - "Datu struktūras", Rīga procedure FindKey (var BST: Binary SearchTree; tkey:KeyType; var found: boolean); {Binārās meklēšanas algoritms. Binārajā kokā BST^ meklē virsotni, kuras atslēgas lauka vērtība ir tkey. Ja meklēšana ir sekmīga, sameklētā virsotne kļūst par tekošo. Ja meklēšana ir nesekmīga, par tekošo virsotni kļūst tā vecāka virsotne, aiz kuras būtu bijis jāatrodas virsotnei ar atslēgas lauka vērtību tkey} var p, prior: NodePointer; begin found:= false; if not Empty(BST) then with BST^ do begin p:= treeRoot; {meklēšanu sāk no saknes} repeat {virsotnes meklēšana} prior:= p; {saglabā vecāku} if p^.el.key = tkey then {sekmīga meklēšana} begin current = p; found:= true end else if tkey then {virzās pa kreisi} p:= p^.left else p:= p^.right {virzās pa labi} until found or (p = nil); if not found then {nesekmīga meklēšana} current:= prior end end;

194
G.Matisons - "Datu struktūras", Rīga Operācijas FindKey izpildes efektivitāte ir O(log 2 (n), kur n – virsotņu skaits binārās meklēšanas kokā. Virsotnes vienkāršajā ceļā veido lineāru datu struktūru, kuras elementu skaits ir vienāds ar binārās meklēšanas koka pakāpi, bet koka pakāpe vienmēr ir mazāka par virsotņu skaitu kokā. procedure Insert (var BST: BinarySearchTree; e: Stdelement; var inserted: boolean); {Binārajā meklēšanas kokā BST^ vecāka virsotnei, ja tā ir tekošā, pievieno jaunu virsotni e, kas kļūst par tekošo visotni} var p, psave: NodePointer; found: boolean; begin inserted:= false; if not Full(BST) then with BST^ do begin psave:=current; {saglabā iepriekšējo stāvokli} FindKey(BST, e.key, found); {pārbaude kokā} if found then current:=psave else {kokā nav virsotnes ar atslēgu e.key} begin new(p); p^.el:=e; {veido lapas virsotni} p^.left:= nil; p^.right:= nil; if Empty(BST) then treeRoot:= p else if e.key < current^.el.key then current^.left:= p {kreisā lapa} else current^.right:= p; {labā lapa} current:= p; inserted:= true end end;

195
G.Matisons - "Datu struktūras", Rīga Operācija Delete ir paredzēta, lai binārās meklēšanas kokā dzēstu tekošo virsotni. Ir svarīgi noskaidrot atšķirību starp jēdzieniem dzēst (delete) un aizvākt (remove). Aizvākt nozīmē likvidēt virsotni binārās meklēšanas kokā. Dzēst nozīmē likvidēt virsotnes elementu el. Aizvākšana ir dzēšanas sastāvdaļa. Rezultātā vai nu virsotne, vai virsotnes elements el binārās meklēšanas kokā vairs nav, tiek izmainīta arī binārās meklēšanas koka uzbūve. Atkarībā no tā, kāda virsotne binārās meklēšanas kokā ir jādzēš, reizēm dzēšana ir tekošās virsotnes aizvākšana, citos gadījumos dzēšamās virsotnes elements tiek aizstāts ar citas virsotnes elementu un tad šī cita virsotne ir jāaizvāc. procedure Delete (var BST: BinarySearchTree; tkey: KeyType; var deleted: boolean); {Binārās meklēšanas kokā BST^ dzēš virsotni, kuras atslēgas lauka vērtība ir tkey. Saknes virsotne kļūst par tekošo virsotni} var remove: NodePointer; procedure SubDel ( var q: NodePointer); {Virsotnes dzēšana vai aizvākšana} begin if q^.right <> nil then {labā vistālākā elementa rekursīva} SubDel(q^.right); {meklēšana kreisajā apakškokā} else {dzēšamā elementa aizstāšana ar citu} begin remove^.el:= q^.el; remove:= q; q:= q^.left {dzēš vienu virsotni} end end;
nil then {labā vistālākā elementa rekursīva} SubDel(q^.right); {meklēšana kreisajā apakškokā} else {dzēšamā elementa aizstāšana ar citu} begin remove^.el:= q^.el; remove:= q; q:= q^.left {dzēš vienu virsotni} end end;">

196
G.Matisons - "Datu struktūras", Rīga procedure Del (tkey: KeyType; var p: NodePointer; var found: boolean); begin if Empty(BST) then found:= false else with BST^ do if tkey < el.key then Del(tkey, left, found) {rekursīva meklēšana pa kreisi} else if tkey > el.key then Del(tkey, right, found) {rekursīva meklēšana pa labi} else {atslēga tkey ir atrasta kokā} begin remove:= p; if p^.left = nil then p:= right {virsotnei p^ nav kreisā bērna} else if p^.right = nil then p:= left {virsotnei p^ nav labā bērna} else SubDel(left); {virsotnei p^ ir abi bērni} dispose(remove); found:= true end end; begin {procedūras Delete darbības sfēra} Del(tkey, BST^treeRoot, deleted); if not Empty(BST) then current:= treeRoot end;
el.key then Del(tkey, right, found) {rekursīva meklēšana pa labi} else {atslēga tkey ir atrasta kokā} begin remove:= p; if p^.left = nil then p:= right {virsotnei p^ nav kreisā bērna} else if p^.right = nil then p:= left {virsotnei p^ nav labā bērna} else SubDel(left); {virsotnei p^ ir abi bērni} dispose(remove); found:= true end end; begin {procedūras Delete darbības sfēra} Del(tkey, BST^treeRoot, deleted); if not Empty(BST) then current:= treeRoot end;">

197
G.Matisons - "Datu struktūras", Rīga Ja operācijā Update tiek labota tekošās virsotnes atslēgas lauka key vērtība, tad jaunās atslēgas vērtībai e.key jābūt lielākai par atslēgas vērtību tekošās virsotnes kreisajā apakškokā un mazākai par atslēgas vērtību tekošās virsotnes labajā apakškokā. Ja šādu prasību nevar nodrošināt, tad jāatsakās no labošanas operācijas vai arī pēc tās izpildes binārās meklēšanas koks jārestrukturē. Viens no paņēmieniem, kā to izdarīt, ir vispirms labojamo virsotni binārās meklēšanas kokā dzēst un pēc tam ar izlabotās atslēgas vērtību to pievienot atkal. procedure Update (var BST: Binary SearchTree; e: Stdelement; k: Edit); {Binārās meklēšanas kokā BST^ labo tekošās virsotnes elementu atbilstoši labošanas variantam k} var ok: boolean; begin if not Empty(BST) then with BST^ do if k = 1 then current^.el.data:= e.data else {jālabo atslēgas laiks} begin Delete(BST, current^.key, ok); Insert(BST, e, ok) end end;

198
G.Matisons - "Datu struktūras", Rīga AVL KOKI AVL (Adelson – Velsky - Landis) koki ir speciāli pēc pakāpes sabalansētu bināro koku paveids, kurā jebkuras virsotnes kreisā apakškoka pakāpe atsķiras no labā apakškoka pakāpes ne vairāk kā par vienu. Piemēram: Vispārējā gadījumā katrai virsotnei divu apakškoku pakāpju starpība ir p (p>0). Virsotni pievienojot vai dzēšot, AVL koks kļūst nesabalansēts, un, lai to novērstu, AVL koks tiek restukturēts, lai iegūtu sabalansētību. Sādu restrukturizāciju AVL kokā sauc par rotāciju. Izpildot operācijas Insert vai Delete, iespējamas trīs dažādas rotācijas atkarībā no AVL koka konfigurācijas. Katram AVL kokam ir minimāla pakāpe, un, kā pierādīja Knuts, AVL koka pakāpe nekad nepārsniedz 1,45log 2 (n), aptuveni vētējot log 2 (n), kur n – virsotņu skaits. AVL koki tiek attēloti saistītā formā, lietojot modeli, kas līdzīgs tam, kādu lieto, attēlojot parastos bināros kokus. Atšķirība ir tai ziņā, ka katrai virsotnei pievieno papildus lauku bal, kurā attēlo attiecīgās virsotnes divu apakškoku sabalansētību.
0). Virsotni pievienojot vai dzēšot, AVL koks kļūst nesabalansēts, un, lai to novērstu, AVL koks tiek restukturēts, lai iegūtu sabalansētību. Sādu restrukturizāciju AVL kokā sauc par rotāciju. Izpildot operācijas Insert vai Delete, iespējamas trīs dažādas rotācijas atkarībā no AVL koka konfigurācijas. Katram AVL kokam ir minimāla pakāpe, un, kā pierādīja Knuts, AVL koka pakāpe nekad nepārsniedz 1,45log 2 (n), aptuveni vētējot log 2 (n), kur n – virsotņu skaits. AVL koki tiek attēloti saistītā formā, lietojot modeli, kas līdzīgs tam, kādu lieto, attēlojot parastos bināros kokus. Atšķirība ir tai ziņā, ka katrai virsotnei pievieno papildus lauku bal, kurā attēlo attiecīgās virsotnes divu apakškoku sabalansētību.">

199
G.Matisons - "Datu struktūras", Rīga Ja kādas virsotnes kreisā apakškoka pakāpe ir par vienu lielāka nekā labā apakškoka pakāpe, tad lauka bal vērtība ir tall.left. Ja kādas virsotnes labā apakškoka pakāpe ir par vienu lielāka nekā kreisā apakškoka pakāpe, tad lauka bal vērtība ir tall.right. Ja abu apakškoku pakāpes ir vienādas, tad virsotne ir sabalansēta un lauka bal vērtība ir equalHt. AVL koku attēlos šīs vērtības tiks parādītas ar rakstzīmēm -, 0 un +. Piemēram: AVL koka modeļa apraksts visumā ir tāds pats, ka parastam binārajam kokam, ar to atšķirību, ka papildus tiek definēts salalansētības tips Balance un lauks bal koka virsotnē: const MaxSize = 500; type Count = 0.. MaxSize; Balance = (tallLeft, equalHt, tallRight);... Node = record el: StdElement; left, right: NodePointer; bal: Balance end;....

200
G.Matisons - "Datu struktūras", Rīga Kaudze (heap) Kaudze ir speciālā veidā organizēts binārais koks ar secīgu virsotņu izvietojumu, to parasti attēlo vektoriālā formā. Kaudze ir efektīvi izmantojama prioritātes rindas veidošanai. Ja r[1], r[2],..., r[n] ir elementu secība, tad tā būs kaudze, ja r[i] < r[2i] un r[i] < r[2i+1] visām i vērtībām. Šīs abas nevienādības sauc par kaudzes nosacījumiem. Piemērā dotas trīs kaudzes, ievērojot kaudzes nosacījumus: [1] [2] [3] [4] [5] [6] [7] [8] [9] Sašķirotu elementu secība vienmēr ir kaudze. Kaudzi var definēt arī kā pabeigto bināro koku, kurā katra vecāka virsotnes prioritāte ir lielāka, lielāka vai vienāda, mazāka, mazāka vai vienāda par katra bērna prioritāti. Ja vecāka virsotne ir mazāka kā tās bērni, tad tas nozīmē, ka vecāka virsotnes prioritāte ir mazāka par katra bērna virsotnes prioritāti. Virsotnes kaudzes binārajā kokā tiek pievienotas saskaņā ar kaudzes elementu secību, sākot ar sakni un aizpildot līmeni pēc līmeņa. Katrā līmenī virsotnes tiek izvietotas no kreisās uz labo pusi. Kaudzes binārā koka konfigurācija ir pabeigtais (complete) binārais koks.

201
G.Matisons - "Datu struktūras", Rīga Attēlā katrai kaudzes virsotnei pievienoti arī virsotņu secības numuri. Šajā kaudzes binārajā kokā katra vecāka virsotne ir mazāka par tās bērnu virsotnēm. Katrā vienkāršajā ceļā no saknes līdz kādai no lapām visas virsotnes veido augošu virsotnes elementu secību. Saknes elements ir vismazākais. Ja kaudzei grib pievienot jaunu virsotni vai kāda virsotne jādzēš vai jālabo, tad kaudze tiek rekonfigurēta tā, lai atkal visas virsotnes atbilstu kaudzes nosacījumiem. Šim nolūkam paredzētas speciālas operācijas SiftUp un SiftDown, ar kurām virsotņu elementus izvieto modeļa vektora vajadzīgajās pozīcijās.

202
G.Matisons - "Datu struktūras", Rīga const MaxSize = 500; type Count = 0.. MaxSize; Edge = Cont; DataType = string; KeyType = integer; Priority = integer; StdElement = record data: DataType; key: KeyType; end; Edit = 1.. 3; Relative = (leftCild, rightChild, root, parient); Node = record el: StdElement; pty: Priority end; NodePointer = ^Node; HeapInstance = record el: array [Count] of Node; n: count end; Heap = ^HeapInstance; procedure SiftUp (var H: Heap); {Kaudzē H^ n-to elementu pārvieto virzienā uz sākumu, nodrošinot kaudzes nosacījumu izpildi} var child, parent: Count; begin if not Empty(H) then with H^ do begin el[0]:= el[n]; child:= n; parent:= n div 2; while el[parent].pty > el[0].pty do begin el[child]:= parent; parent:= parent div 2 end; el[chil]:= el[0] end end;
el[0].pty do begin el[child]:= parent; parent:= parent div 2 end; el[chil]:= el[0] end end;">

203
G.Matisons - "Datu struktūras", Rīga procedure SiftDown (var H:Heap; k: Count); {Kaudzē H^ k-to elementu izsijā lejupvirzienā, nodrošinot kaudzes nosacījumu izpildi} var child, parent: Count; begin if not Empty(H) then with H^ do begin el[0]:= el[k]; {izsijāmo elementu saglabā} parent:= k; child:= k+k; while child <= n do {kamēr ir vismaz viens bērns} begin if child < n then {ja ir divi bērni} if el[child].pty > el[child+1].pty {izvēlas vienu} then child:= child+1; {ar mazāko prioritāti} if el[0].pty > el[child].pty then {meklē vietu} begin el[parent]:= el[child]; parent:= child; child:= parent+parent end else {ja vieta ir atrasta} begin el[parent]:= el[0]; leave end end end; procedure HeapCreate (H: Heap); {Rekonfigurē kaudzi H^} var k: Count; begin k:= (n div 2) +1; while k > 1 do begin k:= k -1; SiftDown(H, k) end end;
el[child+1].pty {izvēlas vienu} then child:= child+1; {ar mazāko prioritāti} if el[0].pty > el[child].pty then {meklē vietu} begin el[parent]:= el[child]; parent:= child; child:= parent+parent end else {ja vieta ir atrasta} begin el[parent]:= el[0]; leave end end end; procedure HeapCreate (H: Heap); {Rekonfigurē kaudzi H^} var k: Count; begin k:= (n div 2) +1; while k > 1 do begin k:= k -1; SiftDown(H, k) end end;">

204
G.Matisons - "Datu struktūras", Rīga B-KOKI B-koks ir speciāls koka veids apjomīgas informācijas glābāšanai un efektīvai sameklēšanai. Koka nosaukuma rašanās hipotēze – firmā Boeing izstrādātā datu struktūra. Katra B-koka virsotne satur vairākus elementus un tai var būt daudz bērnu. Šo īpašību dēļ un arī tāpēc, ka B-koki ir labi sabalansēti (līdzīgi kā AVL-koki), tie nodrošina īsu vienkāršo ceļu, kurā pieeejams visai liels virsotņu sakopojums. Operācijās Insert un Delete ir garantēts, ka garākais ceļš no saknes uz lapu ir O(log 2 n). Par n-tās kārtas B-koku sauc tādu stipri sazarotu koku ar pakāpi 2n+1, kuram piemīt šādas īpašības: 1) katra virsotne, izņemot sakni, satur ne mazāk kā n un ne vairāk kā 2n atslēgas (n ir B-koka kārta); 2) sakne satur vismaz 1 un ne vairāk kā 2n atslēgas; 3) visas lapas izvietotas vienā līmenī; 4) katrā virsotnē rādītāju skaits ir par 1 lielāks nekā atslēgu skaits; 5) katra virsotne satur 2 sarakstus: augošā secībā pēc atslēgām sakārtotu elementu el sarakstu un atslēgas lauku vērtībām key atbilstošu rādītāju ptr sarakstu. Lapām rādītāju saraksta nav. Stipri sazarota koka pakāpe ir vismaz 3. No virsotnes izejošo šķautņu skaits ir mazāks vai vienāds ar n, kur n ir B-koka kārta. Jebkurā momentā, strādājot ar B-koku, attālums no saknes līdz jebkurai lapai ir vienāds ar fiksētu lielumu d.

205
G.Matisons - "Datu struktūras", Rīga Kādas virsotnes bērnu skaits ir ir 0 vai par vienu lielāks kā elementu skaits šai virsotnē. Apskatīsim B-koku ar kārtu n=2. To sauc arī par otrās kārtas B-koku. Praksē visai parasti ir B-koki ar kārtu n=100 vai lielāku. Ja n=2, tad 1) atslēgu skaits saknē: 1 – 4; 2) atslēgu skaits pārējās virsotnēs: 2 – 4; 3) iespējamo bērnu skaits: 0 – 5; 4) pieņemsim, ka atslēgu vērtību diapazons: 1 – 31. Kreisajā apakškokā atrodas visas virsotnes ar atslēgām, kuras mazākas par saknes atslēgas vērtību 20, bet labajā apkškokā – visas virsotnes ar atslēgām, kuras lielākas par saknes atslēgas vērtību 20. Operāciju Insert un Delete algortmi ir sarežģīti ar vairākiem alternatīviem risinājumiem.

206
G.Matisons - "Datu struktūras", Rīga const MaxSize = 500; {uzdod B-koka lietotājs} Order = 2; {B-koka kārta} NodeSize = 4; {maksimālais elementu skaits B-kokā}... type Nodepointer= ^ Node; Node = record parent: NodePointer; el: array [1.. NodeSize] of StdElement; ptr: array [ 1.. NodeSize] of NodePointer end;... Tabulā sniegta informācija par sakarībām starp virsotņu līmeni un virsotņu un elementa skaitu B-kokā. Līmenis Minimālais virsotņu skaits Minimālais elementu skaits Maksimālais virsotņu skaits Maksimālais elementu skaits 11112n 22 2n+12n(2n+1) 32(n+1)2n(2n+1)(2n+1) 2 2n(2n+1) 2 42(n+1) 2 2n(2n+1) 2 (2n+1) 3 2n(2n+1) 3... k2(n+1) k-2 2n(2n+1) k-2 (2n+1) k-1 2n(2n+1) k-1

Еще похожие презентации в нашем архиве:




; new(q); {2} p^:=7; q^:=p^-2; {3} q:=p; {4} dispose(p);")






 прописные и заглавные буквы русского алфавита; 2) 26 латинских строчных и 26.")

 izstrādātajiem materiāliem Enterprise Knowledge Development (EKD) Modelēšanas metode.")

IPM sprieguma avota invertors ar nevadāmu.")


. Click New…")
 in Java Tutorial for students of universities Author: Oxana Dudnik.")

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}