Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

2
Сдала : Тимофеева А. П. Проверила : Французова Г. Н.

4
Повышение производительности ВС непосредственно связано с увеличением быстродействия и емкости памяти. Емкость памяти наиболее крупных вычислительных систем возросла от 1000 байт до десятков терабайт, а время цикла уменьшилось с 20 мкс до 10 нс. Однако быстродействующие запоминающие устройства по прежнему остаются более дорогими, чем медленные. Следовательно, с целью уменьшения стоимости ВС при той же производительности эффективнее иметь иерархию памяти с небольшим по емкости запоминающим устройством, расположенным рядом с процессором и имеющим минимальное время доступа. Содержание

5
Двухуровневая система памяти : - Регистры процессора - Собственно оперативная память ( ОЗУ ) Многоуровневая иерархическая модель памяти : - Регистры - Кэш - память - Основная память - Вторичная / внешняя ( массовая ) память - Архивная память Содержание
 Многоуровневая иерархическая модель памяти : - Регистры - Кэш - память - Основная память - Вторичная / внешняя ( массовая ) память - Архивная память Содержан")
10
Кэш - память или cache memory представляет собой буферное ЗУ, работающее со скоростью, обеспечивающей функционирование ЦП без режимов ожидания. Необходимость в создании кэш - памяти возникла потому, что появились процессоры очень большого быстродействия. Между тем для выполнения сложных прикладных процессов нужна большая память. Использование же большой сверхскоростной памяти невыгодно. Поэтому между ОЗУ и процессором стали устанавливать меньший по размерам высокоскоростной буфер, названный кэш - память. Более того, последнюю разделили на встроенную в процессор (L1) и внешнюю (L2). Встроенная кэш - память по сравнению с внешней имеет более высокое быстродействие и, естественно, стоимость. Поэтому первая меньше второй по емкости. Содержание

15
Характеристика Типичное значение Размер блока ( строки ) байт Время попадания (hit time)1– 4 такта синхронизации ( обычно 1 такт ) Потери при промахе (miss penalty)8-32 такта синхронизации Время доступа (access time)6-10 тактов синхронизации Время пересылки (transfer time)2-22 такта синхронизации Доля промахов (miss rate)1-20% Размер кэш - памяти 4 Кбайт – 16 Мбайт Содержание
4 - 128 байт Время попадания (hit time)1– 4 такта синхронизации ( обычно 1 такт ) Потери при промахе (miss penalty)8-32 такта синхронизации Время доступа (access time)6-10 тактов синхронизации В")
17
При построении систем с иерархической памятью ставится цель получения максимальной производительности подсистемы памяти при ее минимальной стоимости. Эффективность той или иной системы кэш - памяти зависит от стратегий управления памятью. Существует три основных способа размещения блоков ( строк ) в кэш - памяти. По способу размещения блоков основной памяти в кэше различают : 1. Кэш - память с прямым отображением (direct-mapped cache) 2. Частично ассоциативную кэш - память ( или множественно ассоциативную, set-associative cache) 3. Полностью ассоциативную кэш - память (fully associative cache) Содержание

21
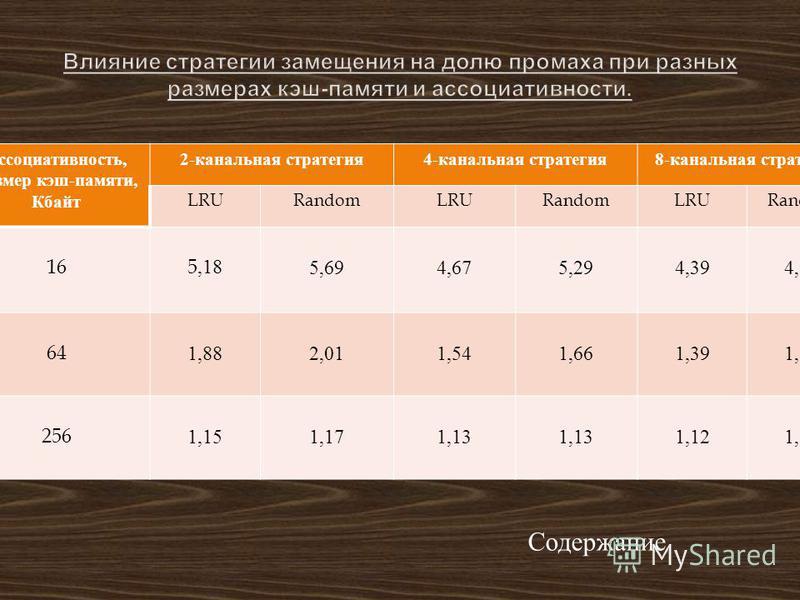
Ассоциативность, Размер кэш - памяти, Кбайт 2- канальная стратегия 4- канальная стратегия 8- канальная стратегия LRURandomLRURandomLRURandom 16 5,185,694,675,294,394,96 641,882,011,541,661,391, ,151,171,13 1,12 Содержание

22
Однопроцессорные ВС были первыми вычислительными системами, в которых была реализована иерархическая структура памяти. Как правило, однопроцессорные ВС представляют собой совокупность процессора, памяти и внешних устройств ( ВНУ ), соединенных с помощью общей шины. Содержание
, соединенных с помо")
24
Это самый простой алгоритм свопинга. Каждый раз при появлении запроса на запись по некоторому адресу обновляется содержимое области по этому адресу как в быстрой, так и в основной памяти, даже если копия содержимого по этому адресу находится в быстром буфере. Такое постоянное обновление содержимого основной памяти, как и буфера, при каждом запросе на запись позволяет постоянно поддерживать информацию, находящуюся в основной памяти, в обновленном состоянии. Поэтому, когда возникает запрос на запись по адресу, относящемуся к области, содержимое которой не находится в данный момент в быстром буфере, новая информация записывается просто на место блока, которое предполагается переслать в основную память ( без необходимости пересылки этого слова в основную память ), так Как в основной памяти уже находится его достоверная копия. Данный алгоритм несложен для реализации и понимания, поэтому он был широко распространен в системах с кэш - памятью. Данный алгоритм также просто позволяет реализовать когерентность данных для мультипроцессорных систем с раздельными кэшами и общей памятью. Содержание

25
Обратной стороной простоты алгоритма является его малая эффективность : в нем не заложена тенденция к минимизации доли обращений к основной памяти. При увеличении объема кэш - памяти доля обращений к основной памяти асимптоматический приближается к доле обращений для записи в основную память ( а не к нулю ). На рис 3.36 приведена блок - схема алгоритма сквозной записи. Содержание

27
Данный алгоритм не сложнее алгоритма сквозной записи. Обращения к основной памяти имеют место в тех случаях, когда в быстром буфере не обнаруживается нужное слово. Эта схема свопинга повышает производительность системы памяти, так как в ней обращения к основной памяти не происходят при каждом запросе на запись, что имеет место при использовании алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти не поддерживается в постоянно обновленном состоянии, если необходимого слова в быстром буфере не обнаруживается, из буфера в основную память надо возвратить какое - либо устаревшее слово, чтобы освободить место для нового необходимого слова. Поэтому из буфера в основную память сначала пересылается какое - то слово, место которого занимает в буфере нужное слово. Таким образом, происходят две пересылки между быстрым буфером и основной памятью. Данный алгоритм не сложнее алгоритма сквозной записи. Обращения к основной памяти имеют место в тех случаях, когда в быстром буфере не обнаруживается нужное слово. Эта схема свопинга повышает производительность системы памяти, так как в ней обращения к основной памяти не происходят при каждом запросе на запись, что имеет место при использовании алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти не поддерживается в постоянно обновленном состоянии, если необходимого слова в быстром буфере не обнаруживается, из буфера в основную память надо возвратить какое - либо устаревшее слово, чтобы освободить место для нового необходимого слова. Поэтому из буфера в основную память сначала пересылается какое - то слово, место которого занимает в буфере нужное слово. Таким образом, происходят две пересылки между быстрым буфером и основной памятью. Содержание

28
Данный алгоритм является улучшением алгоритма простого свопинга. В алгоритме простого свопинга, когда в кэш - памяти не обнаруживается нужное слово, происходит два обращения к основной памяти запись удаляемого значения из кэша и чтение нового значения в кэш. Если слово с того момента, как оно попало в буфер из основной памяти, не подвергалось изменениям, т. е. по его адресу не производилась запись ( оно использовалось только для чтения ), то нет необходимости пересылать его обратно в основную память, потому что в ней и так имеется достоверная его копия ; это обстоятельство позволяет в ряде случаев обойтись без обращений к основной памяти. Если, однако, слово подвергалось изменениям с тех пор, когда его копия была в последний раз записана обратно в основную память, то приходится перемещать его в основную память. Отслеживать изменения слова можно, пометив слово ( блок ) дополнительным флаговым битом. Изменяя значение флагового бита при изменении слова, можно сформировать информацию о состоянии слова ; пересылать в основную память необходимо лишь те слова, флаги которых оказываются в установленном состоянии. Содержание

29
Повышение эффективности алгоритма свопинга с флагами возможно за счет уменьшения эффективного времени цикла, что можно получить при введении регистра ( регистров ) временного хранения между кэш - памятью и основной памятью. Теперь, если данные должны быть переданы из быстрого буфера в основную память, они сначала пересылаются в регистр ( регистры ) временного хранения ; новое слово сразу же пересылается в буфер из основной памяти, а уже потом слово, временно хранившееся в регистре, записывается в основную память. Действия в ЦП начинают опять выполняться, как только для этого возникает возможность. Алгоритм обеспечивает совмещение операций записи в основную память с обычными операциями над буфером, что обеспечивает еще большее повышение производительности. Содержание
 временного хранения между кэш - памятью и основной памятью. Теперь, если данные должны")
30
Прежде всего, эффективное быстродействие кэша должно быть примерно равно быстродействию процессора. Если полное эффективное время обращения к системе памяти с использованием буфера превышает время базового цикла процессора, то для уравнивания ее быстродействия с быстродействием процессора можно прибегнуть к конвейерной организации процесса обработки информации. Когда кэш - память работает с такой же скоростью, как процессор, никакой необходимости в конвейерной работе процессора нет. Делать быстродействие кэш - памяти более высоким, чем быстродействие процессора, не имеет смысла, так как процессор ( или процессоры ) требует обслуживания со стороны памяти с интервалом, не меньшим чем время его рабочего цикла. Современные процессоры выполняют команды со скоростью от нескольких команд в такт до нескольких десятков тактов на команду. Кроме того, используется конвейерная обработка команд. Для увеличения своей производительности процессоры обычно вначале производят выборку предполагаемо необходимых данных и команд, а затем исполняют их. Исходя из таких положений, необходимо добиваться того, чтобы кэш - память действовала со скоростью тактовой частоты процессора. Содержание

31
На производительность памяти очень сильно влияет алгоритм свопинга. Как отмечалось выше, наиболее эффективным алгоритмом для однопроцессорных ВС является регистровый свопинг с флагами. При увеличении размера кэш - памяти стратегия замещения данных не имеет значения, поэтому можно применять наиболее простую случайную стратегию. Необходимо также использовать совмещение работы буферной и основной памяти. Большой класс задач, решаемых на ЭВМ, имеет дело с большими объемами данных, хранимых в массивах. Для улучшения производительности ВС на таких задачах можно применять многомодульную систему основной памяти с горизонтальным расслоением ( рис. 3.37). Содержание

34
В структурной организации многопроцессорной системы наиболее существенен способ связи между процессорами и памятью системы. Как известно, параллельные вычислительные системы делятся на два больших класса : SIMD и MIMD. В настоящее время осваиваются супервычисления на системах из микропроцессоров с кэш - памятью и разделяемой - логически общей и физически распределенной основной памятью. Существующие параллельные вычислительные средства класса MIMD образуют три подкласса : симметричные мультипроцессоры (SMP), кластеры и массово - параллельные системы ( МРР ). Однако степень масштабируемости SMP- систем ограничена в пределах технической реализуемости одинакового для всех процессоров доступа в память со скоростью, характерной для однопроцессорных компьютеров. На данный момент SMP- структура наиболее распространена в классе профессиональных рабочих станций на базе RISC- процессоров. Содержание

37
Общий вид такой многопроцессорной ВС представлен на рис Здесь ВМ вычислительный модуль ( процессор ), всего п штук, ВНУ внешние устройства, всего k штук. В качестве основной памяти может использоваться память с горизонтальным расслоением или же для повышения надежности блочно - модульная память. Основными проблемами в данной архитектуре являются следующие : скорость работы кэш - памяти, блокировка при совместном доступе нескольких процессоров на одновременную запись или запись / чтение данных по одному и тому же адресу. Кэш - память должна работать с тактовой частотой в п раз большей тактовой частоты процессора, так как она должна обеспечивать данными процессоры с частотой один раз в такт. В противном случае каждый процессор должен быть блокирован до момента получения ( или записи ) им требуемых данных, что снижает производительность многопроцессорной ВС. Вообще такая структура сходна с однопроцессорной ВС с кэшем. Она недостаточно эффективна и, как правило, практически не применяется. Содержание
, всего п штук, ВНУ внешние устройства, всего k штук. В качестве основной памяти может использоваться память с горизонтальным расслоением или ж")
39
Данная модель мультипроцессорной системы наиболее распространена в настоящее время. Структурная схема многопроцессорной ВС с раздельными кэшами и общей памятью представлена на рис Каждый ВМ имеет собственную локальную кэш - память, имеется общая разделяемая основная память, все вычислительные модули ( ВМ ) подсоединены к основной памяти посредством шины. К шине подключены также внешние устройства. Все действия с использованием транзакций шины, производимые ВМ и внешними устройствами, с копиями строк, как в каждой кэш - памяти, так и в основной памяти, доступны для отслеживания всем ВМ. Это является следствием того, что в каждый момент на шине передает только один, а воспринимают все абоненты, подключенные к шине. По сравнению с многопроцессорными ВС с общим кэшам и общей памятью в данной системе наряду с проблемой пропускной способности шины возникает еще и проблема когерентности кэш - памяти. Содержание

40
Содержание

Еще похожие презентации в нашем архиве:
























 организации памяти заключается в использовании на одном компьютере нескольких.")



")




, является МИКРОПРОЦЕССОР или.")





 Быстродействие - зависит.")
