Скачать презентацию
1
Архитектуры с параллелизмом на уровне команд

2
Два класса Суперскалярные процессоры Процессоры с длинным командным словом

4
Динамическое исполнение команд в суперскалярном процессоре Предсказание ветвлений (переходов) ( branch prediction ). Переименование регистров, чтобы удалить зависимости между данными и регистрами, невидимые компилятору ( register renaming ). Спекулятивное исполнение предсказанных переходов ( speculative execution of predicted branches ) Исполнение команд вне порядка ( out-of- order instruction execution )
 ( branch prediction ). Переименование регистров, чтобы удалить зависимости между данными и регистрами, невидимые компилятору ( register renaming ). Спекулят")
5
Как реализован конвейер? Устройство предварительной обработки инструкций в порядке их следования в программном коде ( front end ). Исполнение вне порядка ( Out-Of-Order execution ) Блок упорядоченного завершения ( In- order retirement )
. Исполнение вне порядка ( Out-Of-Order execution ) Блок упорядоченного завершения ( In- order retirement )")
6
Устройство front end Предсказание следующей инструкции. Используются два алгоритма предсказания переходов. Динамический алгоритм работает на стадии выборки. Статический алгоритм работает на стадии декодирования, использует правила: безусловные переходы выполняются, условные переходы назад выполняются, переходы вперед не выполняются, это соответствует обычному циклу. Выборка потока инструкций. Декодирование инструкций в микрооперации. Переименование внешних регистров. Размещение (назначение) вычислительных устройств и запоминание статуса каждой микрооперации в переупорядочивающем буфере (Reorder buffer (ROB)) в исходном порядке инструкций

7
Пример переименования регистров (1)a = x + f;a = x + f; (2)b = a * z;b = a * z; (3)a = a + v;a1 = a + v; (4)d = a * b;d = a1 * b;
a = x + f;a = x + f; (2)b = a * z;b = a * z; (3)a = a + v;a1 = a + v; (4)d = a * b;d = a1 * b;")
8
Каждый МОП может проходить через следующие стадии: 1. находится в очереди планировщика, но ещё не готов к исполнению; 2. готов к исполнению (все аргументы операции вычислены); 3. запущен на исполнение (диспетчеризован); 4. исполнен и ждёт отставки либо отмены спекулятивной ветви; 5. находится в процессе отставки.
; 3. запущен на исполнение (диспетчеризован); 4. исполнен и ждёт отставки ли")
9
Устройство Out-Of-Order execution Планирование и распределение микроопераций Выполнение микроопераций и запоминание их результатов временно в буфере ROB.

10
Блок упорядоченного завершения Запись результатов обратно во внешние архитектурные регистры, постоянная запись данных, если это необходимо. Изъятие микроопераций из буфера ROB.

11
Упрощенная схема процессора

12
Pentium III

13
Alpha 21264

14
Athlon

15
Opteron

16
Гипертранспорт

17
Memory Cache memory Conveyer length Issue ports count Register count Functional units =16 TB L2 cache 1 MB 2 ALU 80 integer 72 float 833 MHz 4 instructions / cycle L1 cache 64KB 6 2 ME M 2 FPU =1 TB L2 cache 1 MB 3 ALU 120 integer 120 float 2,4 MHz 3 x86 instructions / cycle L1 cache 64 KB 8 3 ME M 3 FPU Alpha 21264Opteron бита 3,2 MB/sec 128 бит 6,4 MB/sec 1х128 2х64 Frequency Throughput Bus width

19
Pentium 4



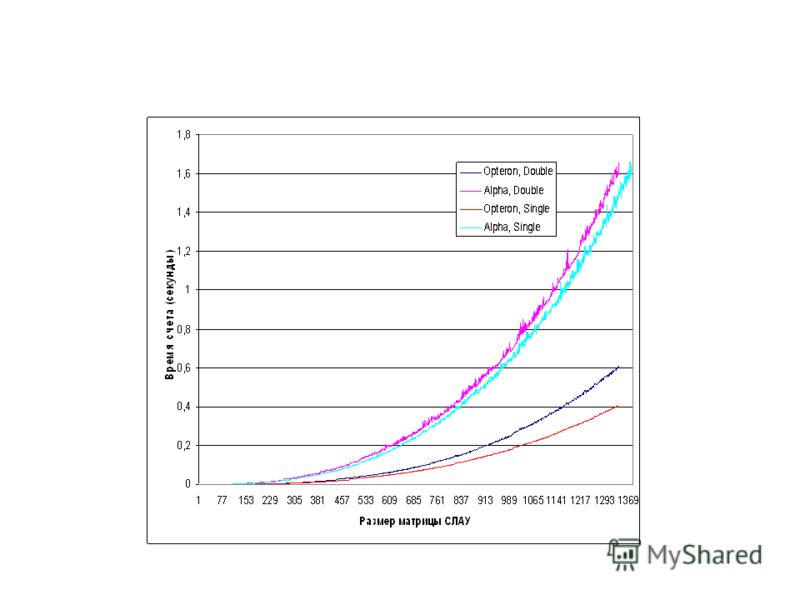

 Параллелизм команд (ILP – Instruction.")
. Шина AMD Athlon AMD Opteron.")



 организации памяти заключается в использовании на одном компьютере нескольких.")

.")
")



")


 Кафедра Параллельных вычислительных технологий Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru.")
 СуперскалярныеVLIW / EPIC RISCCISC Itanium2 Эльбрус.")
 Маркова Валентина Петровна, markova@ssd.sscc.rumarkova@ssd.sscc.ru Киреев Сергей Евгеньевич,")

