Скачать презентацию
Идет загрузка презентации. Пожалуйста, подождите

1
Организация памяти

2
Применение: Desktops: один пользователь Серверы: много пользователей, удаленные Суперкомпьютеры: высокая производительность Встроенные компьютеры (embedded systems) (автомобили, навигаторы, сотовые телефоны …)
 (автомобили, навигаторы, сотовые телефоны …)")
3
Intel Processors Processor nameYearNumber of transistors Intel Intel Intel Pentium Pentium Pro Intel Pentium II Intel Pentium III Intel Pentium Intel Itanium Intel Itanium

4
Processor nameCoresYearNumber of transistors Intel Itanium (Montecito)Intel, HP Intel Core 2 Duo (Conroe)Intel TukwilaIntel,HP4(65nm) Open SPARC T1 Open SPARC T2 Sun Phenom X Phenom X AMD3 4(65nm) Core 2 Duo E8500 Intel2 (45nm) Core 2 Extreme QX9770 Intel42008 Xeon X7460Intel Processors
Intel, HP 220061 720 000 000 Intel Core 2 Duo (Conroe)Intel22006291 000 000 TukwilaIntel,HP4(65nm)20092 000 000 000 Open SPARC T1 Open SPARC T2 Sun 8 4 8 2005 2007 300 000 000 Phen")
5
Intel Processors Processor Name Cores/ Threads Tech. process nm GHzL2,L1 Cache Size L3 Cache MB Power W Year Xeon X5560 4/8452,8/3, K L1 32K/32 K Core 2 Quad Q9650 4/4453,0 2 6M L1 32K/32 K Phenom4/4453, L1 64/64 6M

6
Intel Processors NehalemCores/ Threads Tech. Process nm GHz L2 Cache Size KB L3 Cache size MB Power W Year Core i7 Exstreme Edition 4/8453, , november Core i /8452, , november Core i /8452, , november L1 32K/32K. Difference from Core 2 Duo : hyper-threading, L3 Cache Производительность растет от поколения к поколению

7
Процессор Nehalem Nehalem HT Sandy BridgeSandy Bridge HT Ivy BridgeIvy Bridge HT «Базовая» модель Core i7- 875K Core i7-2600K Core i K Технология пр-ва 45 нм 32 нм 22 нм Частота ядра, ГГц 2,4 Кол-во ядер/потоков вычисления 4/4 4/84/44/84/44/8 Кэш L1, I/D, КБ 32/32 Кэш L2, КБ4×256 Кэш L3, МиБ Частота UnCore, ГГц 2,4

8
Оценки производительности Основной критерий оценки производительности – скорость выполнения программ. Зависит от компилятора, набора машинных команд и аппаратуры. Одна из компонент общего времени – процессорное время (T). T=CPU clock cycles for a programClock cycle или T = (N S)/R, где N – количество машинных команд, которые будут реально выполнены, S – среднее количество тактов, необходимых для выполнения одной команды, R – тактовая частота. Для уменьшения T (увеличения производительности), нужно уменьшить N и S и увеличить R. N, S и R не независимы. N уменьшается, когда компилятор создает программу с меньшим числом команд. S уменьшается, когда выполнение команды содержит меньшее число тактов или команды выполняются параллельно. С повышением R сокращается время выполнения такта.
. T=CPU clock cycles for a pro")
9
Способы повышения производительности T = Tprocessor + Tmemory 1. Технология 2. Построение быстродействующих логических схем 3. Использование быстрых алгоритмов выполнения операций 4. Конвейеризация вычислений 5. Повышение производительности памяти 6. Параллелизм ILP TLP SIMD –обработка 7. Оптимизирующие компиляторы

10
Иерархическая структура ЗУ Основная (оперативная) память Внешняя память (магнитные диски) Архивная память По мере продвижения по структуре сверху вниз возрастают время, объем, убывает – стоимость одного бита. Регистры Кэш-память
 память Внешняя память (магнитные диски) Архивная память По мере продвижения по структуре сверху вниз возрастают время, объем, убывает – стоимость одного бита. Регистры Кэш-память")
11
Характеристики ЗУ 1. Емкость – размер слова, количество слов; 2. Передаваемая порция – размер блока, слово; 3. Метод доступа – последовательный, прямой, произвольный, ассоциативный; 4. Производительность – время доступа, время цикла, скорость передачи; 5. Физический тип – полупроводниковые микросхемы, магнитная среда, оптические ЗУ, магнитооптические. 6. Физические характеристики – энергозависимые/энергонезависимые, стираемые/нестираемые; 7. Организация Классификация ЗУ: по способу доступа, физическому принципу хранения информации, по расположению (внутренняя, внешняя).

12
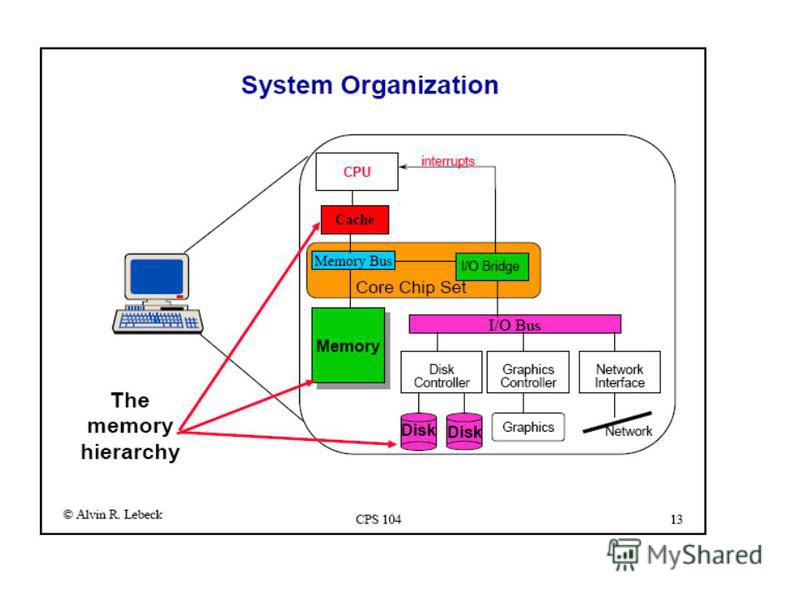
Иерархия памяти L1 DCache L1 ICache L2 Cache L3 Cache Main Memory Registers Disk (Swap) CPU is small part of system, most of system is memory hierarchy
 CPU is small part of system, most of system is memory hierarchy")
13
Memory Hierarchy Hierarchy levels can be grouped in different ways: by ISA visibility registers caches, memory, disk (swap): look like one thing disk (file system) by implementation technology registers, cache: SRAM (high speed circuits) main memory: DRAM (high density technology) disk: magnetic iron oxide (electrical/mechanical)
: look like one thing disk (file system) by implementation technology registers, cache: SRAM (high speed circuits) main memory:")
14
TypeCapacityTechnologyLatencyBandwith Registers<1 KBCustom memory with multiple ports, CMOS 1 ns150 GB/s L1 Cache<256 KBOn-chip CMOS SRAM 4 ns50 GB/s L2 Cache<16 MBOn-chip CMOS SRAM 10 ns25 GB/s L3 Cache8 MB, … 30 MB On-chip or off- chip CMOS SRAM 20 ns10 GB/s Memory<16 GBCMOS DRAM50ns4 GB/s Disk Storage< 3 ТBMagnetic disk2,5-16 ms MB/s Seagate Barracuda Momentus TBMagnetic disk3 – 12,5 ms

15
DDR RAM Частота шины Теоретическая способность GB/s 1-канальный режим пропускная 2-канальный DDR M Hz6.412,8 DDR M Hz8,5317,07 DDR M Hz10,6721,33 DDR M Hz12,825,6 DDR M Hz14,9329,87

17
Полупроводниковая память По способу доступа делятся на адресные (с произвольным доступом), последовательные и ассоциативные. Структура адресного ЗУ (RAM) Ре- гистр адреса Регистр данных m бит в слове 2 n слов
, последовательные и ассоциативные. Структура адресного ЗУ (RAM) Ре- гистр адреса Регистр данных m бит в слове 2 n слов")
18
Read-Write Memory Two types: SRAM and DRAM SRAM: memory cell – flip-flop DRAM: memory cell – capacity (drain – substrate of MOS- transistor). The kinds of IC memory organization: Linear-select (2D), two-dimensional (3D), compromise (2DM).
. The kinds of IC memory organization: Linear-select (2D), two-dimensional (3D), compromise (2DM).")
19
Semiconductor memory: typically RAM (access time is not depended on data location). RAM: Read-Write memory and ROM (Read-Only memory). Read-write random access memory Memory buffer register m bits per word 2 n words Address register Read Write n bits Random Access Memory (RAM)
. RAM: Read-Write memory and ROM (Read-Only memory). Read-write random access memory Memory buffer register m bits per word 2 n words Address register Read Write n bits")
20
Two types: SRAM and DRAM SRAM: memory cell – flip-flop DRAM: memory cell – capacity (drain – substrate of MOS- transistor). The different types of IC memory organization: Linear-select (2D) Two-dimensional (3D) Compromise (2DM) Read-Write Memory
. The different types of IC memory organization: Linear-select (2D) Two-dimensional (3D) Compromise (2DM) Read-Write Memory")
21
Store bits in flip-flops. Figure shows a basic memory cell consisting of a flip-flop with associated control circuitry. Select Input Write SRSR Out Basic cell for linear-select SRAM S I O W Static RAM

22
Four-address memory with 4 bits per word Linear Select SRAM

23
Select 1 Input Write S T R Out Select 2 S2 S1 I O W Two-dimensional memory cell Static RAM (2)
")
24
The linear-select organization is used for IC memory with small capacity. Address decoder is complicated because there are 2 n AND elements (with n inputs). Address decoder for two-dimensional IC organization is more simple: 2 2 n/2 AND elements (with n/2 inputs). Properties of SRAM: fast density is not very large – six transistors per bit doesnt need to be refreshed (data stays as long as power is on) basically used for cache memory Static RAM (3)
. Address decoder for two-dimensional IC organization is more simple: 2 2 n/2 AND elements (wit")
25
Трехстабильный буфер (Three State Buffer) A EN A Out 0 0 Z 0 1 Z EN Y Y Out A A EN=0 EN=1 module tristate (en, a, y); input a, en; output y; reg y; (a or en) begin if (en) y = a; else y = 1bz; end endmodule Или module tristate (en, a, y); input a, en; output y; assign y = en?a:1bz; endmodule
 A EN A Out 0 0 Z 0 1 Z 1 0 0 1 1 1 EN Y Y Out A A EN=0 EN=1 module tristate (en, a, y); input a, en; output y; reg y; always @ (a or en) begin if (en) y = a; else y = 1bz; end endmodule Или module tristate (e")
26
МОП – транзисторы (1) Действует как управляемый напряжением резистор Vin Сопротивление очень велико – транзистор закрыт. Сопротивление очень мало – транзистор открыт. 2 типа МОП-транзисторов: с n-каналом и с p-каналом n-канальный МОП-транзистор: С увеличением Vgs (когда Vgs>0) значение Rds уменьшается. Если Vgs=0, то сопротивление Rds очень большое - > 1 мегаома. Транзистор закрыт. В открытом состоянии транзистора – < 10 ом. затвор сток исток Vgs + -
 Действует как управляемый напряжением резистор Vin Сопротивление очень велико – транзистор закрыт. Сопротивление очень мало – транзистор открыт. 2 типа МОП-транзисторов: с n-каналом и с p-каналом n-канальный МОП-транзистор: С ув")
27
МОП – транзисторы (2) Затвор МОП-транзистора изолирован от истока и стока материалом с очень большим сопротивлением. Напряжение на затворе создает электрическое поле, которое уменьшает или увеличивает ток, текущий от истока к стоку – полевой эффект. От затвора к истоку или от затвора к стоку ток практически не течет. затвор исток сток Vgs - + p-канальный МОП-транзистор: С уменьшением Vgs (когда Vgs 0) значение Rds уменьшается. Транзистор открывается. Если Vgs=0, то сопротивление Rds очень велико (транзистор закрыт).
 Затвор МОП-транзистора изолирован от истока и стока материалом с очень большим сопротивлением. Напряжение на затворе создает электрическое поле, которое уменьшает или увеличивает ток, текущий от истока к стоку – полевой эффект.")
28
КМОП-инвертор Q2 Q1 p-канал n-канал Vout Vin Q1Q2Vout 0.0 (L) 5.0 (H) off on On off 5.0 (H) 0.0 (L) IN OUT Vdd = +5.0V
 5.0 (H) off on On off 5.0 (H) 0.0 (L) IN OUT Vdd = +5.0V")
29
Модель инвертора с ключами Vin=L Vout=H Vdd = +5.0V Vin=H Vout=L Vdd = +5.0V

30
ЗЭ статического типа (CMOS) Линии записи/чтения DjDj DjDj Select V DD T1 T2 T3 T4 T5 T6
 Линии записи/чтения DjDj DjDj Select V DD T1 T2 T3 T4 T5 T6")
31
SRAM Cell Word Line ~ Bit LineBit Line

32
SRAM Cell При чтении ячейка выдаёт прямой и инверсный сигналы на двойную битовую шину. Но при перезаписи (когда состояние должно смениться либо 01, либо 10) заранее поданные на шину сигналы на мгновение приводят к двум коротким замыканиям в ячейке, которая выдаёт своё содержимое, противоположное записываемому значению. Только после переключения инверторов равенство состояния ячейки и подаваемого сигнала восстанавливается. В результате при перезаписи происходит частичное проседание напряжения на шине питания в районе записываемой строки или слова, что хоть и не сможет повредить хранящимся в округе данным, но явно ограничивает максимальную частоту срабатывания, не говоря уже об энергопотреблении.
 заранее поданные на шину сигналы на мгновение приводят к двум коротким замыканиям в ячейке, к")
33
Структура ЗУ типа 3D DC Y Data Address n/2 DC X n/2 Address

34
Структура ЗУ с селекторами Dout (m bits) A k A n-1 Memory array 2 n-k m2 k Data buffers (column I/O) Row deco- der m 2 k bits Din (m bits) A 0... A k-1 Column decoder WR/RD CS Compromise
 A k A n-1 Memory array 2 n-k m2 k Data buffers (column I/O) Row deco- der m 2 k bits Din (m bits) A 0... A k-1 Column decoder WR/RD CS Compromise")
35
Static RAM The linear-select organization is used for IC memory with small capacity. Address decoder is complicated: 2 n AND elements (with n inputs). Address decoder for two-dimensional IC organization is more simple: 2 2 n/2 AND elements (with n/2 inputs). Properties of SRAM: fast density is not very large – six transistors per bit doesnt need to be refreshed (data stays as long as power is on). basically is used for cache memory
. Address decoder for two-dimensional IC organization is more simple: 2 2 n/2 AND elements (with n/2")
36
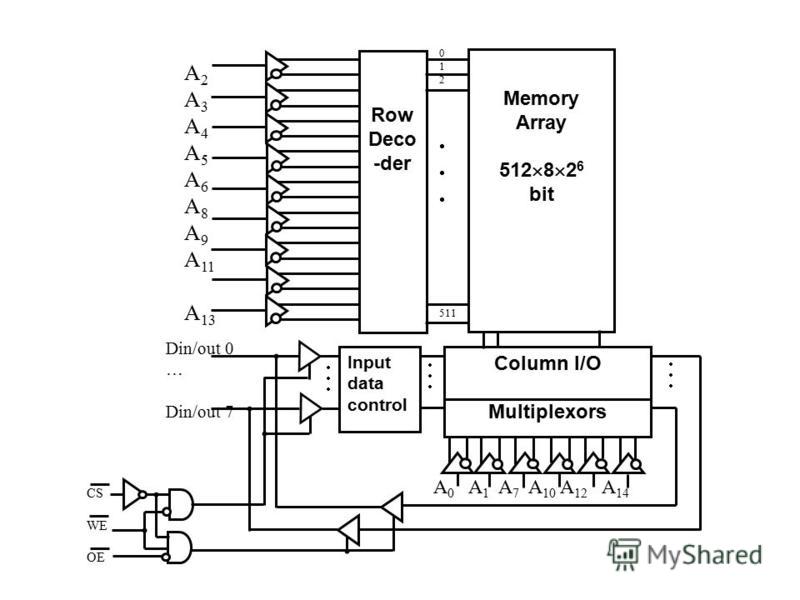
Микросхема статической памяти A 0 A 1 A14 WE OE CS 0 1 RAM W 5 6 OE 7 CS.:...:.. CSOEWEI/OpinsMode 1xxzNot selected 011zOutput disable 001DoutRead 0x0DinWrite

38
Временные диаграммы микросхемы статической памяти Цикл чтения Цикл записи 1 Цикл записи 2 (CS Controlled) (WE Controlled) ÀDDR CS OE WE DATA Dout Din
 (WE Controlled) ÀDDR CS OE WE DATA Dout Din")
39
Logic Symbols for SRAMs 128 KB HM A0 A1 A2 A16 WE CS1 CS1 OE IQ0 IQ1 IQ2 IQ3 IQ4 IQ5 IQ6 IQ KB A0 A1 A2. A17 A18 WE CS OE IQ0 IQ1 IQ2 IQ3 IQ4 IQ5 IQ6 IQ7 HM

40
Design of SRAM Module (Example1) Data bus Implement a 1M×8 SRAM module using 512K×8 IC Signal MEM – memory request. Signal ~WR/RD specify operation A0 A18 WE CS OE IQ0 IQ IQ1 A0 A18 WE CS OE IQ0 IQ IQ1 A0 A18 A0 A18 D0 D1 D7 D1 D0... D1 D0 D7 A0 A1 A18 A19 MEM ~WR ~CS0 ~WR ~CS1 ~CS0 ~WR/RD ~CS Address bus Control signals ~WR ~RD
 Data bus Implement a 1M×8 SRAM module using 512K×8 IC Signal MEM – memory request. Signal ~WR/RD specify operation A0 A18 WE CS OE IQ0 IQ7...... IQ1 A0 A18 WE CS OE IQ0 IQ7...... IQ1 A0 A18 A0 A18 D0 D1 D7 D1 D0... D1")
41
~WR Example 2 Implement a 512K ×16 SRAM module using 128 K×8 IC A0 A1 A16 CS A0 A1 A16 CS A0 A1 A16 CS A0 A1 A16 CS WE OE WE OE A0 A1 A16 CS WE OE A0 A1 A16 CS WE OE A0 A1 A16 CS WE OE A0 A1 A16 WE CS A0 A1 A2 A16 A17 A18 A17 A EN MEM ~WR/ RD ~MEM ~RD ~WR A0 A1 A16 A1 A0 A16 A0 A1 A16 A0 A1 A0 A1 A16 CS0 CS1 CS2 CS3 ~WR ~RD D0 D1 D7 D1 D0 D1 D7 D0 D1 D7 D8 D9 D15 D0 D1 D15

42
SRAM in Verilog RAM inputs & outputs are separate module memory (mem_req, address, data_in, data_out, read_write); input mem_req, read_write; input [3:0 ] data_in; input [5:0] address; output reg [3:0] data_out; reg [3:0] mem[0:63]; // 64 4 memory ) if (mem_req) if (!read_write) mem[address] = data_in; // write else data_out = mem[address]; // read else data_out = 4bz; // high impedance state endmodule
![SRAM in Verilog RAM inputs & outputs are separate module memory (mem_req, address, data_in, data_out, read_write); input mem_req, read_write; input [3:0 ] data_in; input [5:0] address; output reg [3:0] data_out; reg [3:0] mem[0:63]; // 64 4 memory al](http://images.myshared.ru/18/1063375/slide_42.jpg "SRAM in Verilog RAM inputs & outputs are separate module memory (mem_req, address, data_in, data_out, read_write); input mem_req, read_write; input [3:0 ] data_in; input [5:0] address; output reg [3:0] data_out; reg [3:0] mem[0:63]; // 64 4 memory al")
43
SRAM in Verilog Bidirectional data bus module memory (mem_req, addr, d_q, read_write); input mem_req, read_write; inout [7:0 ] d_q; input [7:0] addr; reg [7:0] mem[0:255]; // memory assign d_q = mem_req?(read_write ? data[addr] : 8bz): 8z; or read_write) if(mem_req) if(!read_write) data[addr]=d_q; always (mem_req or data) if(!read_write) data[addr]=d_q; end endmodule
![SRAM in Verilog Bidirectional data bus module memory (mem_req, addr, d_q, read_write); input mem_req, read_write; inout [7:0 ] d_q; input [7:0] addr; reg [7:0] mem[0:255]; // 256 8 memory assign d_q = mem_req?(read_write ? data[addr] : 8bz): 8z; alwa](http://images.myshared.ru/18/1063375/slide_43.jpg "SRAM in Verilog Bidirectional data bus module memory (mem_req, addr, d_q, read_write); input mem_req, read_write; inout [7:0 ] d_q; input [7:0] addr; reg [7:0] mem[0:255]; // 256 8 memory assign d_q = mem_req?(read_write ? data[addr] : 8bz): 8z; alwa")
44
Динамическая память Линия записи/считывания Линия выборки (Select) Cç Rн Cл n+n+ n+n+ CcCc Поликремний ЛЗС Select Конструкция ЗЭ DRAM SiO 2 bit stored as charge in capacitor C c high density (1 transistor for DRAM vs 6 transistors for SRAM) destructive read (capacitor discharge on a read) read is automatically followed by a write (to restore) charge leaks away over time (need to refresh)
 Cç Rн Cл n+n+ n+n+ CcCc Поликремний ЛЗС Select Конструкция ЗЭ DRAM SiO 2 bit stored as charge in capacitor C c high density (1 transistor for DRAM vs 6 transistors for SRAM) destructi")
45
Dynamic Random Access Memory (DRAM) n+n+ n+n+ CcCc Polysilicon wordline Select DRAM memory cell construction SiO 2 Bitline (Data in/out ) wordline (select) Cc Rн Cl bit stored as charge in capacitor C c high density (1 transistor for DRAM vs 6 transistors for SRAM) destructive read (capacitor discharge on a read) read is automatically followed by a write (to restore) charge leaks away over time (need to refresh)
 n+n+ n+n+ CcCc Polysilicon wordline Select DRAM memory cell construction SiO 2 Bitline (Data in/out ) wordline (select) Cc Rн Cl bit stored as charge in capacitor C c high density (1 transistor for DRAM vs 6 transi")
46
n+n+ n+n+ CcCc Поликремний SiO 2 ЛЗС Select Ucc A B T2T2 T1T1 T3T3 T4T4 Усилитель- регенератор ЛЗС а ЛЗС в C Л /2 A B Включение усилителя-регенератора в разрыв ЛЗС Конструкция ЗЭ DRAM

47
Матрица динамических ЗЭ Column 0Column 1 Column 2 Column 3 Row 0 Row 3

49
Пример микросхемы динамической памяти Mикросхема имеет 24-разрядный адрес. Мульти- плексирование сокращает число адресных линий на 12. A0 DRAM A1. A11 DI RAS CAS WR/ RD MA А0 DRAM А1. А10 WR/ RD RAS CAS D in/out MA МА – мультиплексированные линии адреса. Во время спада сигнала RAS на этих линиях присутствует адрес строки, во время спада сигнала CAS – адрес столбца. Адрес должен устанавливаться до спада соответствующего строба и удерживаться после него еще некоторое время. Микросхемы с объемом 4М могут быть симметричными (11+11) и асимметричными (12+10).

50
DRAM Chip Organization Memory Array (square matrix) Column decoder Column I/O Column address buffer Row address buffer Din Dout Row decoder A0... An-1 CAS RAS WE MUX Address row buffer MUX
 Column decoder Column I/O Column address buffer Row address buffer Din Dout Row decoder A0... An-1 CAS RAS WE MUX Address row buffer MUX")
51
DRAM multiplexed address lines internal row buffer to perform the operation next five cycles are needed: put row address on lines set row address strobe (RAS) read row into row buffer put column address on line (to switch external multiplexer) set column address strobe (CAS) read column bits out of row buffer write row bits content to row return RAS and CAS to inactive state
 read row into row buffer put column address on line (to switch external multiplexer) set co")
52
Временные диаграммы DRAM IC CAS

53
Временные параметры микросхем DRAM Время доступа trac –задержка появления действительных данных на выходе относительно спада RAS. Для современных микросхем – нс. tRC- время цикла чтения или записи данных – минимальный период между началами соседних циклов обращения (75 – 125 нс). tPC - период следования CAS в страничном режиме. tRAS, tCAS - минимальная длительность активной части (низкого уровня) сигналов RAS и CAS. Время предварительного заряда RAS и CAS - tRP и tCP (Precharge Time). Время задержки между импульсами RAS# и CAS# - tRCD. Задержка данных относительно импульса CAS#.

54
RAS only refresh (ROR CAS before RAS (CBR) RAS CAS MA 2 способа регенерации : burst refresh, distributed refresh. t RF t RF = T RF /n 15,6 мкс T RF
 RAS CAS MA 2 способа регенерации : burst refresh, distributed refresh. t RF t RF = T RF /n 15,6 мкс T RF")
55
Счет-чик регене- рации Буфер адреса строки Буфер адреса столбца 4 Матрицы ЗЭ 2048 Усилители чтения и вентили ввода- вывода Дешифратор адреса столбцов Входной буфер данных Выходной буфер данных A0 A1 A10 RАS CAS W/R Mуль- ти- плек- сор Дешиф ратор адреса строк УУ RAS CAS D i/o 0 D i/o 3 Структура микросхемы динамической памяти

56
Структура модуля динамической памяти Адрес ОП Write Read РА Матрица микросхем памяти РД WR RAS CAS CS Контрол- лер Таймер регене- рации Запрос регенерации Декодер ст.разр. адреса Мультиплексор адреса

57
Контроллер DRAM Блок управления (контроллер) динамической памяти вырабатывает последовательность управляющих сигналов, обеспечивающих выполнение операций чтения, записи и регенерации. В общем случае на каждую операцию обращения к динамической памяти требуются как минимум следующие 5 тактов: Указание типа операции (Write или Read) и установка адреса строки. Формирование сигнала RAS. Установка адреса столбца (переключение мультиплексора). Формирование сигнала CAS. Возврат сигналов RAS и CAS в неактивное состояние.
 динамической памяти вырабатывает последовательность управляющих сигналов, обеспечивающих выполнение операций чтения, записи и регенерации. В общем случае на каждую операцию обращения к динамической памяти")
58
Comparison SRAM with DRAM SRAM is faster than DRAM: 1/4 - 1/8 access time of DRAM. The density SRAM is lower than DRAM 1/4 density of DRAM. Static: bit is not erased on a read. SRAM does not need to refresh. Unlike DRAM, there is no difference between access time and cycle time. Access time: time to read Cycle time: time between reads > access time (DRAM) Cycle time = access time (SRAM) SRAM address lines are not multiplexed. SRAM is more expensive than DRAM: about 8-16 times.

59
DRAM: Dynamic Random Access Memory – Highest densities – Optimized for cost/bit main memory SRAM: Static Random Access Memory – Densities ¼ to 1/8 of DRAM – Speeds 8-16x faster than DRAM – Cost 8-16x more per bit – Optimized for speed caches

61
YearCapacity Access time Cycle time Kb150 ns300 ns Mb80 ns160 ns Mb60 ns120 ns Mb50 ns100ns Gb45 ns70 ns Gb40 ns50 ns DRAM Improvement DDR2: Module Bandwidth – up 10,6 GB/s

63
DRAM Optimizations Faster to read data from the same row – Called page mode (fast page mode, EDO are variations) – Multiple CAS accesses Bandwidth determined by cycle time – Example Row: 100ns + – Example Column: 30ns +, usually more like 50ns due to external components Add a clock to the interface - synchronous DRAMs – Enable split transactions Use both edges of the clock - Double data rate In practice – There are multiple banks on chip – Arrays are 1-4 Mbits
 – Multiple CAS accesses Bandwidth determined by cycle time – Example Row: 100ns + – Example Column: 30ns +, usually more like 50ns due to")
64
Синхронные DRAM (SDRAM) A0 A1 A2 DQ 0 DQ 1 A11 DQ 2 DQ 3 CLK DQ 4 CKE DQ 5 DQM DQ 6 DQ 7 CS WE RAS CAS CLK - Clock Input CKE – Clock Enable CS - разрешение декодирования команд; А0-А11- address - мультиплексированная шина адреса. DQx – Data Input/Output – двунаправленные линии данных. DQM – Маскирование данных. A11 – выбор банка
 A0 A1 A2 DQ 0 DQ 1 A11 DQ 2 DQ 3 CLK DQ 4 CKE DQ 5 DQM DQ 6 DQ 7 CS WE RAS CAS CLK - Clock Input CKE – Clock Enable CS - разрешение декодирования команд; А0-А11- address - мультиплексированная шина адреса. DQx – Data Input/Out")
65
В памяти на традиционных DRAM-модулях процессор выставляет на шину адрес и управляющий сигнал, что в совокупности означает, что либо из указанной ячейки должны быть считаны данные, либо в эту ячейку данные должны быть записаны. Спустя некоторое время – время доступа к памяти – DRAM-модуль либо выдает считанные данные, либо записывает их в запоминающие элементы по указанному адресу. В течение этого интервала времени модуль памяти выполняет определенные операции, заданные алгоритмом его работы, а процессор просто должен ждать их завершения, что отрицательно сказывается на производительности всей системы. При синхронном доступе DRAM-память передает данные под управлением внешних тактирующих сигналов. Процессор или другое устройство-задатчик (master) выставляет на шины (линии магистрали) нужную информацию (команду и адрес при чтении, а при записи также и данные), которые фиксируются во внутренних регистрах- защелках по фронту синхросигнала. (SDRAM)

66
Структура SDRAM Устройство управления CKE CLK CS DQM WE RAS CAS A11 Регистр режима Буфер адреса столбца Буфер адреса строки Счетчик регенерации MUX выбора строк Счетчик пакета Декодер столбцов Банк А DRAM (2Mx8) Усилители считывания и вентили вв/выв Ре- гистр Ре- гистр Усилители считывания и вентили вв/выв Банк B DRAM (2M(8) Выходной буфер данных Входной буфер данных Дек. строк Дек. строк A0…A10 D0…D7
 Усилители считывания и вентили вв/выв")
67
Результат предоставляется процессору (задатчику) через определенное количество тактов. Процессор в это время может заниматься другими задачами. В цикле чтения высокий уровень DQM переводит шину данных в высокоимпедансное состояние. В цикле записи высокий уровень DQM запрещает запись текущих данных, низкий – рaзрешает. Все сигналы стробируются положительным фронтом CLK. Комбинация управляющих сигналов в каждом такте кодирует определенную команду. Объем микросхемы 4Мбайт. Микросхема содержит два банка запоминающих элементов. Это позволяет реализовать параллелизм операций. Активизировать строку в банке можно во время операции с другим банком. Выбор банка осуществляется старшим разрядом адреса А11. Микросхемы SDRAM оптимально используются для пакетной передачи. Длина пакета программируется при инициализации микросхем (burst length=1, 2, 4, 8).
 через определенное количество тактов. Процессор в это время может заниматься другими задачами. В цикле чтения высокий уровень DQM переводит шину данных в высокоимпедансное состояние. В цикле записи выс")
68
Счетчик пакета работает по модулю, равному длине пакета и не позволяет перейти границу пакетного цикла. Регистр режима позволяет задавать длину пакета, а также программировать интервал между получением запроса на чтение/запись и началом передачи данных. Последнее дает возможность регулировки запаздывания первого доступа с целью приспособления памяти к частотным требованиям системы и длине пакета, в котором слова читаются или записываются в каждом такте после всего одной команды. При выполнении команды Write имеется возможность блокирования записи данных любого элемента пакета – для этого достаточно в его такте установить высокий уровень сигнала DQM. Этот же сигнал используется и для перевода в высокоимпедансное состояние буферов данных при выполнении операции чтения.

69
DDR SDRAM Тактируется обоими фронтами синхроимпульсов (это удваивает пропускную способность интерфейса памяти) Во внутренних блоках микросхемы тактирование ведется обычным способом.
 Во внутренних блоках микросхемы тактирование ведется обычным способом.")
70
CK,~CK Регистр и преобразователь входных данных Банк Усилители Декодер строк Управление в/в Схема изменения разрядности Выходной буфер DLL CK ~CK Генера- тор строба Буер столбцов Декодер столбцов Латентность и длина пакета Регистр програм- мирования Timing Register CK ~CK~CKE ~CS ~RAS ~CAS~WEDM WE DM Буфер строк и счетчик регенерации LRAS LCBR LCKE Регистр адреса CK,~CK Add LCAS LWELCBR Строб данны х

71
Микросхемы SDRAM имеют средства энергосбережения, для управления ими используется вход разрешения синхронизации CKE. В режиме саморегенерации (Self Refresh) микросхемы периодически выполняют циклы регенерации по внутреннему таймеру. В этом режиме они не реагируют на внешние сигналы и внешняя синхронизация может быть остановлена. При переводе CKE в низкий уровень устанавливаются режимы пониженного энергопотребления. Все современные типы динамической памяти имеют ядро DRAM. SDRAM DDR SDRAM DDR2 SDRAM DDR3 SDRAM
 микросхемы периодически выполняют циклы регенерации по внутреннему таймеру. В этом режиме они")
72
DDR3 SDRAM DDR3 SDRAM (от англ. double-data-rate three synchronous dynamic random access memory удвоенная скорость передачи данных синхронной памяти с произвольным доступом) это тип оперативной памяти используемой в компьютерах, разработанный как последователь DDR2 SDRAM. DDR3 обещает сокращение потребления энергии на 40% по сравнению с модулями DDR2, благодаря применению 90-нм технологии производства, что позволяет снизить эксплуатационные токи и напряжения (1,5 В, по сравнению с 1,8 В для DDR2 и 2,5 В для DDR). "Dual-gate" транзисторы будут использоваться для сокращения утечки тока. Разница в технологическом процессе и напряжении питания
 это тип оперативной памяти используемой в компьютерах, разработанный как пос")
73
Модуль – это печатная плата, на которой размещаются чипы памяти. У модулей есть объем (измеряемый в мегабайтах или гигабайтах), тип (SDRAM и поколение), частота, на которой он работает и ширина шины данных (также называемая разрядностью). Объем модуля определяется как суммарный объем используемых в нем чипов памяти. Чипы памяти обладают различным объемом, называемым «плотностью чипа». Так, существуют чипы на 256 Мбит, 512 Мбит, 1 Гбит и более плотные. Модуль, состоящий из восьми чипов по 512 Мбит, будет иметь объем, равный 4096 Мбит или 512 Мбайт. Ширина шины современных модулей памяти 64 бита.
, тип (SDRAM и поколение), частота, на которой он работает и ширина шины данных (также называемая разрядностью). Объем модул")
74
Кэш-память Мотивация: Большая память DRAM - медленная; Маленькая память (SRAM) – быстрая. Необходимо уменьшить среднее время обращения к ОП. Принцип локальности: локальность в пространстве локальность во времени Способы реализации кэш-памяти: 1. С прямым отображением 2. Полностью ассоциативная 3. Частично-ассоциативная Способы записи в кэш: Write Through Write Back.
 – быстрая. Необходимо уменьшить среднее время обращения к ОП. Принцип локальности: локальность в пространстве локальность во времени Способы реализации кэш-памяти: 1. С пр")
75
Кэш-память CPU Блок обработки команд Массив данных (SRAM) Справочник (каталог) Основная память ( DRAM ) Контрол -лер Адрес Данные Hit Miss Среднее время обращения tср = p t b (1 p) t m
 Справочник (каталог) Основная память ( DRAM ) Контрол -лер Адрес Данные Hit Miss Среднее время обращения tср = p t b (1 p) t m")
76
Four Memory Hierarchy Questions (4 вопроса иерархии памяти) Q1: Where can a block be placed in a cache? (block placement) Q2: How is a block found if it is in a cache? (block identification) Q3: Which block should be replaced on a miss? (block replacement) Q4: What happens on a write? (write strategy). If each block has only one place it can appear in the cache, the cache is said to be direct mapped. If a block can be placed anywhere in the cache, the cache is said to be fully associative. If a block can be placed in a restricted set in the cache, the cache is said to be set associative. If ther are n blocks in a set – is called n-way associative.
 Q1: Where can a block be placed in a cache? (block placement) Q2: How is a block found if it is in a cache? (block identification) Q3: Which block should be replaced on a miss? (block replac")
77
Hit: data appears in some block in the cache. Miss: data needs to be retrieve from a block in the DRAM. Hit time: RAM access time +time to determine hit/miss. Miss Rate = 1- Hit Rate; Miss Penalty: Time to replace a block in the cache + Time to deliver the block the processor. Hit time << Miss Penalty. Понятия

78
Кэш-память с прямым отображением (Direct Mapped Cache) Block 0 Block 1 Block511 Block 0 Block 1 Block511 Block 0 Block 1 Block 511 Page 0 Page 1 Page Block 0 Block 1 Block 511 Объем кэш- памяти равен странице ОП i = j mod m, j – номер блока ОП i – номер строки кэша, m – число строк в кэше Вся память разделена на страницы или фреймы (pages or frames)
 Block 0 Block 1 Block511 Block 0 Block 1 Block511 Block 0 Block 1 Block 511 Page 0 Page 1 Page 65535 Block 0 Block 1 Block 511 Объем кэш- памяти равен странице ОП i = j mod m, j – номер блока ОП")
79
Tag Data Буфер Данные Компа- ратор Tag (Номер страницы) Index (номер блока) Смещение 18 бит 9 бит 5 бит Структура кэш-памяти с прямым отображением
 Index (номер блока) Смещение 18 бит 9 бит 5 бит Структура кэш-памяти с прямым отображением")
80
Direct Mapped Cache (cont.) For a cache of 2 M bytes with block size of 2 L bytes: Tag Index Block Offset 32-M bits M-L bits L bits 31 0 Address Tag Index Block Offset 17 bits 9 bits 6 bits 31 0 Address Example: For a cache of 32K bytes with block size of 64 bytes:
 For a cache of 2 M bytes with block size of 2 L bytes: Tag Index Block Offset 32-M bits M-L bits L bits 31 0 Address Tag Index Block Offset 17 bits 9 bits 6 bits 31 0 Address Example: For a cache of 32K bytes with block si")
81
Direct Mapped Cache h b Block Offset 17 bits 9 bits 6 bits 31 0 Block Address Byte 63 Byte 0 == 1111 Valid MUX Cache TagsCache Data Hit

82
00x Block Offset 19 bits 7 bits 6 bits 31 0 Block Address 00x00650 Byte 63 Byte 0 == 1111 Valid MUX Cache TagsCache Data Miss

83
Преимущества Direct Mapped Cache – схема достаточно простая (небольшое число транзисторов), содержит всего 1 компаратор. Cache block is available before Hit/Miss. Недостаток – частые Cache-промахи Block Size Tradeoff: Larger block size takes advantage of spatial locality, but: Larger block size means larger miss penalty.
, содержит всего 1 компаратор. Cache block is available before Hit/Miss. Недостаток – частые Cache-промахи Block Size Tradeoff: Larger block size takes advantag")
84
Полностью ассоциативная кэш-память (Fully Associative Cache) Tag (номер блока)Смещение (Offset) == Tags Data Hit/Miss Each block can be placed anywhere in the cache.
 Tag (номер блока)Смещение (Offset) == Tags Data Hit/Miss Each block can be placed anywhere in the cache.")
85
Disadvanteges of fully associative cache: The number of comparators (number of entries) is very large. Достоинство – блок удаляется только тогда, когда заполнена вся память.
 is very large. Достоинство – блок удаляется только тогда, когда заполнена вся память.")
86
Частично-ассоциативная кэш-память Наибольшее распространение получил данный способ организации кэш-памяти. Комбинирует оба подхода – direct mapped и fully associative : кэш-память состоит из набора ассоциативных блоков памяти. При этом ОП и кэш условно делятся на несколько наборов блоков (строк для кэша). Зависимость между номером набора i и номером блока j ОП следующая i = j mod v. v – число наборов. Размещение блоков по строкам набора - произвольное, и для поиска нужной строки в пределах набора используется ассоциативный принцип. Как и в случае кэша с прямым отображением, адрес ОП состоит из трех компонент, но средняя компонента адреса определяет не номер строки, а номер набора. Каждый набор блоков кэша является ассоциативной памятью.

87
ОП Cache directory Comparators == == == == Tag Номер набора Смещение 4-way set-associative Cache

88
Disadvanteges of set-associative cache: N-way set-associative cache contains N comparators. Data comes after Hit/Miss decision and set selection. Advantages: each memory block has choice of N cache lines. Для каждого блока есть выбор из N позиций. Зависимость между объемом кэш-памяти V (Cache size), размером блока Z(block size), числом каналов w (associativity) и числом наборов S выражается следующей формулой: V = w S Z.

89
Set-Associative Cache Tag Index Offset MUX = S0 S1 S0 S1 DC Data Hit? Direct-mapped cache (1-way) The number of sets S=2
 The number of sets S=2")
90
4-way Set-Associative Cache (example) Hit? Tag Index Offset MUX = MUX w0 w1 w2 w3 S0 S1 S0 S1 Data DC CD Why SA is slow The number of sets S=2
 Hit? Tag Index Offset MUX = MUX w0 w1 w2 w3 S0 S1 S0 S1 Data DC CD Why SA is slow The number of sets S=2")
91
Cache Block Replacement Policy Random Replacement: Hardware Randomly Selects a cache item and throw it out. Least Recently Used: -Hardware keeps track of the access history. Replace the entry that has not been used for the longest time.

92
Cache Write Policy Write Through: Write to cache and memory at the same time. Write Back: Write only Cache. Write Buffer for the Write Through. Victim Cache.

93
Multi-Level Cache L1I L2 L3 L1D GPRs L1: 32K + 32K, 8-way - Intel (Conroe) 64K + 64K, 2-way - AMD K8 Block size – 64byte. L2 – P4-E(Prescott), 2Mbyte, Conroe – 4M Itanium Montecito L2 – 512Kbyte, L3 – 24 Mbyte Sandy Bridge L2 – 512K Byte, L3 – 8 M Byte
 64K + 64K, 2-way - AMD K8 Block size – 64byte. L2 – P4-E(Prescott), 2Mbyte, Conroe – 4M Itanium Montecito L2 – 512Kbyte, L3 – 24 Mbyte Sandy Bridge L2 – 512K Byte, L3 – 8 M By")
94
Среднее время обращения к памяти для системы с 2-уровневым кэшем Tср = t 1 + (1-p 1 ) (t 2 + (1-p 2 ) t Mem ) = = t 1 +(1-p 1 )t 2 + (1-p 1 )(1-p 2 ) t Mem
 (t 2 + (1-p 2 ) t Mem ) = = t 1 +(1-p 1 )t 2 + (1-p 1 )(1-p 2 ) t Mem")
95
Average Memory Access Time (AMAT)
")
96
Эксклюзивный и не эксклюзивный кэш Не эксклюзивный кэш: информация на всех уровнях кэширования может дублироваться. Таким образом, L2 может содержать в себе данные, которые уже находятся в L1, а L3 (если он есть) может содержать в себе полную копию всего содержимого L2 (и, соответственно, L1). Эксклюзивный кэш: предусматривает чёткое разграничение: если информация содержится на каком-то уровне кэша то на всех остальных она отсутствует. Плюс эксклюзивного кэша - общий размер кэшируемой информации в данном случае равен суммарному объёму кэшей всех уровней в отличие от не эксклюзивного кэша, где размер кэшируемой информации (в худшем случае) равен объёму самого большого уровня кэша. Минус эксклюзивного кэша менее очевиден, но он есть: необходим специальный механизм, который следит за собственно «эксклюзивностью» (так, например, при удалении информации из L1- кэша, перед этим автоматически инициируется процесс её копирования в L2).
 может содержать в себе полную копию в")
97
Схема выполнения запроса на чтение в системе с 2-уровневым кэшем (1) Поиск в L1 Запрос на чтение Miss? Да Нет Да Чтение из L1 Запрос выполнен Поиск в L2 Miss? Чтение из ОП Запись в L2 Запрос выполнен Нет Чтение из L2 Запись в L1 Неэксклюзивный кэш
 Поиск в L1 Запрос на чтение Miss? Да Нет Да Чтение из L1 Запрос выполнен Поиск в L2 Miss? Чтение из ОП Запись в L2 Запрос выполнен Нет Чтение из L2 Запись в L1 Неэксклюзивный кэш")
98
Схема выполнения запроса на чтение в системе с 2- уровневым кэшем (2) Эксклюзивный кэш Поиск в L1 Запрос на чтение Miss? Да Нет Да Чтение из L1 Запрос выполнен Поиск в L2 Miss? Чтение из ОП Процедура записи удаляемого блока в L2 (если нужно, удаление из L2 блока и запись в ОП) Запрос выполнен Нет Чтение из L2 Запись в L1 Удаление из L2 Да Есть свободный блок в L1? Запись в L1 Нет
 Эксклюзивный кэш Поиск в L1 Запрос на чтение Miss? Да Нет Да Чтение из L1 Запрос выполнен Поиск в L2 Miss? Чтение из ОП Процедура записи удаляемого блока в L2 (если нужно, удаление")
99
Дисковые ЗУ Взаимодействие магнитной головки с движущимся магнитным носителем. Обмотка записи Воздушный зазор Диск Механизм доступа Вращающийся шпиндель Головка чтения/записи

100
Информация записывается на жёсткие (алюминиевые или стеклянные) пластины, покрытые слоем ферромагнитного материала, чаще всего двуокиси хрома. Используется одна или несколько пластин на одной оси. Головки чтения в рабочем режиме не касаются поверхности пластин благодаря прослойке набегающего потока воздуха, образующейся у поверхности при быстром вращении. Расстояние между головкой и диском составляет несколько нанометров (в современных дисках около 10 нм. При отсутствии вращения дисков головки находятся у шпинделя или за пределами диска в безопасной зоне, где исключён их контакт с поверхностью дисков.
 пластины, покрытые слоем ферромагнитного материала, чаще всего двуокиси хрома. Используется одна или несколько пластин на одной оси. Головки чтения в рабочем режиме не касаются поверхнос")
101
Disk Parameters

102
Magnetic Disks Емкость ( Capacity) до 3 Терабайт Ширина – 3,5 или 2,5 дюйма
 до 3 Терабайт Ширина – 3,5 или 2,5 дюйма")
103
Magnetic Disks

104
Disk Performance

105
Магнитные диски При работе с магнитными дисками используются следующие понятия. Дорожка – концентрическая окружность на магнитном диске, которая является основой для записи информации. Цилиндр – это совокупность магнитных дорожек, расположенных друг над другом на всех рабочих поверхностях дисков винчестера. Сектор – участок магнитной дорожки, который является одной из основных единиц записи информации. Каждый сектор имеет свой собственный номер. Кластер - минимальный элемент магнитного диска, которым оперирует операционная система при работе с дисками. Каждый кластер состоит из нескольких секторов. Любой магнитный диск имеет логическую структуру, которая включает в себя следующие элементы: загрузочный сектор; таблицы размещения файлов; область данных.

106
Методы записи Метод продольной записи При этом вектор намагниченности домена расположен продольно, то есть параллельно поверхности диска. Максимально достижимая при использовании данного метода плотность записи составляет около 23 Гбит/см². К 2010 году этот метод был практически вытеснен методом перпендикулярной записи. Метод перпендикулярной записи Метод перпендикулярной записи это технология, при которой биты информации сохраняются в вертикальных доменах. Это позволяет использовать более сильные магнитные поля и снизить площадь материала, необходимую для записи 1 бита. Плотность записи у современных (на 2009 год) образцов 400 Гбит на кв/дюйм. Жёсткие диски с перпендикулярной записью доступны на рынке с 2005 года.

107
Термоассистируемая магнитная запись Метод тепловой магнитной записи (Heat-assisted magnetic recording, HAMR) на данный момент самый перспективный из существующих, сейчас он активно разрабатывается. При использовании этого метода используется точечный подогрев диска, который позволяет головке намагничивать очень мелкие области его поверхности. После того, как диск охлаждается, намагниченность «закрепляется». Есть экспериментальные образцы, плотность записи которых 150 Гбит/см². Разработка HAMR-технологий ведется уже довольно давно, однако эксперты до сих пор расходятся в оценках максимальной плотности записи. Так, компания Hitachi называет предел в 2,33,1 Тбит/см², а представители Seagate Technology предполагают, что они смогут довести плотность записи HAMR- носителей до 7,75 Тбит/см².
 на данный момент самый перспективный из существующих, сейчас он активно разрабатывается. При использовании этого метода используется точечный")
108
Информация на диске Загрузочный сектор (Boot Record) занимает сектор с номером 0. Содержит Небольшую программу IPL2 (Initial Program Loading 2), с помощью которой компьютер определяет возможность загрузить ОS с данного диска. Кроме загрузочного сектора имеется главного загрузочный сектор (Master Boot Record). Жесткий диск может быть разбит на несколько логических дисков. Для Master Boot Record всегда выделяется физический сектор 1. Этот сектор содержит программу IPL1 (Initial Program Loading 1), которая при своем выполнении определяет загрузочный диск.
 занимает сектор с номером 0. Содержит Небольшую программу IPL2 (Initial Program Loading 2), с помощью которой компьютер определяет возможность загрузить ОS с данного диска. Кроме загрузочного секто")
109
Информация на диске Таблица размещения файлов (FAT) используется для хранения сведений о размещении файлов на диске. Oбычно используются две копии таблиц, которые следует одна за другой, и содержимое их полностью совпадает. Это делается на тот случай, если на диске произошли какие либо сбои, то диск всегда можно "отремонтировать", используя вторую копию таблицы. Если будут испорчены обе копии, то вся информация на диске будет потеряна. Область данных (Data Area) занимает основную часть дискового пространства и служит непосредственно для хранения данных.
 используется для хранения сведений о размещении файлов на диске. Oбычно используются две копии таблиц, которые следует одна за другой, и содержимое их полностью совпадает. Это делается на тот случай")
110
Формат дорожки диска GAP1 ID GAP2 DATA GAP3 Sector 0Sector Synch Data CRC

111
Постоянные ЗУ (рабочий режим только для чтения – ROM) 1. Масочные ЗУ. Информация записывается с помощью шаблона (маски) на завершающем этапе технологического процесса. В качестве элементов связи (ЗЭ) используют диоды или МОП- транзисторы
 1. Масочные ЗУ. Информация записывается с помощью шаблона (маски) на завершающем этапе технологического процесса. В качестве элементов связи (ЗЭ) используют диоды или МОП- транзисторы. 11010001 10")
112
Programmable ROM DC A PROM chip is manufactured with all of its diodes or transistors connected. The customer may program the ROM using PROM programmer. Fuse A link is vaporized by selecting it using PROM address and data lines and then applying a high voltage pulse (10-30V) to the device through a special input pin (for programming). OR Matrix

113
Programmable ROM Programmed by removing or creating special links WL BL

114
PROM (однократно программируемые ROM) Программируются удалением или созданием специальных перемычек. Элементы с плавкими перемычками
 Программируются удалением или созданием специальных перемычек. Элементы с плавкими перемычками")
115
Общая структура PROM Декодер n -1 Адрес n бит Горизонтальные линии – линии выборки слов, вертикальные – линии выборки разрядов. ROM является энергонезависимой памятью.

116
ROM cells BL WL GND BL WL VDD Word Line Bit Line 1 0

117
Application of MOS Transistors as Memory Cells DC V DD A 0 A 1 A n-1 ~ D 0 ~D 1 ~D 7 Active high word line Active low bit lines

118
Erasable PROM Erasing of old information and its replacement with the new one is possible. Erasing is carried out by ultraviolet rays in EPROM (erasable PROM), In EEPROM (electrically PROM) – by electrical signals. Floating gate MOS transistors are used as connection links. G S D Floating gate Source Substrate Gate Drain n + p Device cross-section n + Polysilicon SiO 2 Si
, In EEPROM (electrically PROM) – by electrical signals. Floating gate MOS transistors are u")
119
Репрограммируемые ЗУ Возможно стирание старой информации и замена ее новой. Стирание – в EPROM производится ультрафиолетовыми лучами, в EEPROM – электрическими сигналами. В качестве ЗЭ используются МОП-транзисторы с плавающим затвором. FAMOS - Floating-gate Avalanche-Injection MOS. Исток Затвор Сток Металл или поликремний Канал n+n+ n+n+ p Si SiO 2

120
FAMOS (Floating-gate Avalanche- Injection MOS). D n+n+ n+n+ 20 V D S n+n+ n+n+ D 0 V D S Перепрограммирование: Стирание запрограммированных значений Запись новых значений Запись информации (процесс программирования) выполняется намного медленнее (на порядок), чем чтение. Свойство данного устройства - программируемое пороговое напряжением. Запись Хранение
. D n+n+ n+n+ 20 V - - - - - - - - - - D S n+n+ n+n+ D 0 V - - - - - - D S - - - - Перепрограммирование: Стирание запрограммированных значений Запись новых значений Запись информации (процесс программиров")
121
FAMOS При приложении высокого напряжения между истоком и затвором-стоком электроны получают достаточно энергии, чтобы пройти через слой окисла (лавинная инжекция). Часть из них захватываются плавающим затвором. n+n+ n+n+ D 5 V D S Этот процесс является самосинхронизирующимся: отрицательный заряд на плавающем затворе уменьшает электрическое поле на оксиде, которое в конце концов не сможет ускорять горячие электроны. После снятия напряжения отрицательный заряд на плавающем затворе остается. Это обстоятельство увеличивает пороговое напряжение транзистора (как правило, результирующее пороговое напряжение будет порядка 7V). Рабочий режим
. Часть из них захватываются плавающим затвором. n+n+ n+n+ D 5 V - - - - - - D S - - - -")
122
Стирание информации в EPROM В EPROM информация стирается при облучении ячеек ультрафиолетом через прозрачное окошко в корпусе микросхемы (SiO2 и поликремний прозраны для ультрафиолетовых лучей. При облучении в областях транзистора возникают фототоки и тепловые токи, что делает области транзистора проводящими и позволяет заряду покинуть плавающий затвор. Достоинство – саморегулируемость заряда. Недостатки: Ограниченное число циклов стирания информации: несколько тысяч. Необходимость использования специального устройства для стирания С увеличением числа циклов стирания надежность падает (изменяются пороги запоминающих устройств) Процесс стирания происходит медленно – от нескольких секунд до нескольких минут. Скорость программирования – 5 – 10 мс/слово. В процессе программирования воникает высокая рассеиваемая мощность

123
Запись информации. При подаче на управляющий затвор и сток достаточно высокого напряжения в обратно смещенных p-n переходах возникает пробой и область канала насыщается свободными электронами. Часть электронов, имеющих достаточную энергию, преодолевает потенциальный барьер и проникает в область плавающего затвора. Снятие высокого программирующего напряжения восстанавливает непроводящее состояние диэлектрических областей транзистора и запирает электроны в плавающем затворе. Захваченный заряд может храниться долгое время (десятки лет). Процесс ввода зарядов в плавающий затвор саморегулирующийся. Заряженный электронами плавающий затвор экранирует действие управляющего затвора и в диапазоне рабочих напряжений проводящий канал в транзисторе не образуется. Стирание информации: ультрафиолетовым облучением или электрическими сигналами. В первом случае число циклов пере- программирования существенно ограниченно – Свойства материалов под действием ультрафиолетовых лучей изменяются. EPROM

124
Storage Matrix in EPROM

125
Электрическое стирание информации стало применяться в транзисторах типа FLOTOX (Floating-gate Tunneling Oxide), затем в транзисторах типа ETOX. Конструктивно отличаются более тонким слоем диэлектрика (под затвором). При приложении к тонкому слою диэлектрика напряжения порядка 10В электроны проходят через диэлектрик в одном из двух направлений в зависимости от знака напряжения. Саморегулируемость процесса заряда была потеряна. Выход – построение ЗЭ на двух транзисторах – один с плавающим затвором, другой – обычный. Площадь ЗЭ EEPROM больше, чем у памяти EPROM, a стоимость выше. Преимущество электрического стирания – можно стирать информацию не со всего кристалла, а выборочно (в EEPROM индивидуально для каждого адреса). Длительность процесса стирание – запись значительно меньше. Число циклов перепрограммирования – Степень интеграции ниже, а стоимость выше, чем у EPROM. EEPROM
, затем в транзисторах типа ETOX. Конструктивно отличаются более тонким слоем диэлектрика (под затвором). При приложении к тонкому слою диэл")
126
EEPROM (Electrically Erasable Programmable Read-Only Memory) n+n+ n+n+ Source Gate Drain Floating Gate SiO 2 Поликремний FLOTOX-транзистор (Floating-Gate Tunneling Oxide Transistor) Диэлектрическая прослойка, отделяющая плавающий затвор от канала уменьшена до толщины 10 нм и меньше. При подаче на этот тонкий слой диэлектрика напряжения, примерно равного 10 V, электроны проходят через плавающий затвор в обе стороны благодаря механизму туннелирования Фаулера-Нордхейма
 n+n+ n+n+ Source Gate Drain Floating Gate SiO 2 Поликремний FLOTOX-транзистор (Floating-Gate Tunneling Oxide Transistor) Диэлектрическая прослойка, отделяющая плавающий затвор от канала уме")
127
FLOTOX-транзистор Стирание выполняется путем подачи напряжения обратной полярности по отношению к напряжению, подаваемому при записи (обратимость процесса программирования). Инжекция электронов в плавающий затвор при записи увеличивает порог. Подача напряжения обратной полярности при стирании, наоборот, уменьшает порог. При снятии с плавающего затвора слишком большого заряда, может получиться обедненное устройство, которое нельзя будет запереть с помощью стандартных сигналов числовой шины. Получаемое пороговое напряжение зависит от исходного заряда затвора и приложенного программирующего напряжения. Кроме этого, оно зависит от толщины окисла, которая существенно колеблется в пределах кристалла. Теряется возможность саморегулируемости заряда, т.к. требуется контроль получаемого порогового напряжения. Эта проблема решена с помощью построения запоминающего элемента на двух транзисторах – одном с плавающим затвором, и другом – ключевом (обычном).
. Инжекция электронов в плавающий затвор при записи увеличивает порог. Подача")
128
Двухтранзисторная ячейка V DD Word line Bit line Схемы с двумя транзисторами занимают больше места на кристалле. Устройство FLOTOX само по себе также больше, чем FAMOS из-за дополнительного объема туннелирующего оксида. Достоинство – большое количество циклов стирания до Многократное программирование вызывает смещение порогового напряжения из-за необратимого захвата электронов в SiO 2. При программировании порог транзистора FLOTOX выше, чем V DD, в результате чего ячейка отключается. Ключевой транзистор действует, как устройство доступа для операции чтения. Хранение информации осуществляется на FLOTOX- транзисторе.

129
EEPROM A0 A1 A14 CS OE Q0 Q1 Q2 Q3 Q4 Q5 Q6 Q7

130
Organization of IC size 32Kx8 DC Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 Mat- rix 512x 64 D7D7 D6D6 D5D5 D4D4 D3D3 D2D2 D1D1 D0D0 A6A6 A 14 A0A0 A5A MUX

131
Using ROM for Realization of Integer Multiplication A0 A1 A2 A3 A4 A5 A6 A7 CS A0 A1 A2 A3 B0 B1 B2 B3 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 Q0 Q1 Q2 Q3 Q4 Q5 Q6 Q7 A7A6A5A4A3A2A1A0Q7Q6Q5Q4Q3Q2Q1Q0 B3B2B1B0A3A2A1A0P7 P6 P5P4P3P2 P1 P A,B – 4-bit integer unsigned A= (a3a2a1a0) B=(b3b2b1b0) A×B = P

132
Using ROM for Realization of logic Functions (LUT) x1x2x3x4x5x6x7x8y1y2y3y4y5y6y7y A0 A1 A2 A3 A4 A5 A6 A7 CS X8 X7 X6 X5 X4 X3 X2 X1 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 Q0 Q1 Q2 Q3 Q4 Q5 Q6 Q7
 x1x2x3x4x5x6x7x8y1y2y3y4y5y6y7y8 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 11 1 1 0 1 0 0 0 0 0 0 0 0 0 1 00 1 0 0 1 0 0 0 0 0 0 0 0 0 1 11 0 0 0 0 0 1 0 0 0 0 0 0 1 0 00 1 1 0 0 1 0 0 0 0 0 0 0 1 0 11 0")
133
Структура ЗУ типа EPROM D CP 1 Данные D0-D7 R ESES E Деко- дер адреса Матри- ца ЗЭ Муль- типлек- соры Регистр Адрес А0-А8 Микросхема фирмы Cypress Semiconductor. Емкость – 4К бит при организации

134
Ядром схемы является структура 2DM. Регистр принимает данные по фронту сигнала CP. Применение регистра повышает быстродействие схемы, т.к. сразу после записи предыдущего слова в регистр можно переходить к чтению следующего. Управление микросхемой осуществляется двумя сигналами – E и E S. Время доступа – 25 нс. A0 A1. A8 R E E S CP D0 D1 D2 D3 D4 D5 D6 D7

135
Использование ROM для реализации логических функций (LUT) X1 X2 X3 X4 X5 X6 X7 X8 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y A3 A2 A1 A0 B3 B2 B1 B0 P7 P6 P5 P4 P3 P2 P1 P0
 0123456701234567 X1 X2 X3 X4 X5 X6 X7 X8 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 0123456701234567 A3 A2 A1 A0 B3 B2 B1 B0 P7 P6 P5 P4 P3 P2 P1 P0")
136
Flash-Memory По типу ЗЭ подобна EPROM. Особенности – не предусмотрено стирание отдельных слов, стирание осуществлятся либо для всей памяти одновременно, либо для достаточно больших блоков. Это способствует упрощению схемных решений, снижению стоимости микросхем, достижению высокого уровня интеграции и быстродействия. Объединение в схемотехнике flash-памяти достоинств ее предшественников. EPROM EEPROM Flash + = 2 источника питания Стирание УФ 1-транзисторная ячейка 1 источник питания Стирание ЭС 2-транзисторная ячейка 1 или 2 источника питания Стирание ЭС 1-транзисторная ячейка

137
Структуры с ячейками NOR и NAND Основой flash-памяти являтся накопитель (матрица ЗЭ). Используются два направления: на основе ячеек NOR; на основе ячеек NAND. Схема на основе ячеек NOR X1X1 X2X2 XmXm R Vcc F
. Используются два направления: на основе ячеек NOR; на основе ячеек NAND. Схема на основе ячеек NOR X1X1 X2X2 XmXm R Vcc F")
138
В ячейке NOR транзисторы соединены параллельно и для получения нуля на выходе достаточно, чтобы хотя бы один транзистор был открыт. В матрице ЗУ все транзисторы, кроме адресованного, находятся в закрытом состоянии. Поэтому, если в плавающем затворе выбранного транзистора будет заряд, то транзистор не откроется, и на выходе будет 1. При отсутствии заряда сигнал выборки откроет опрашиваемый транзистор и на выходе будет 0. Накопители на основе ячеек NOR обеспечивают быстрый доступ к словам при произвольной выборке. Используются фирмой Intel.

139
XmXm X1X1 X2X2 Vcc F В ячейке NAND транзисторы соединены последовательно и для формирования высокого уровня выходного напряжения достаточно наличие в цепочке хотя бы одного запертого. При работе таких ячеек в составе ЗУ все транзисторы, кроме адресуемого, должны быть открыты. Поэтому состояние выхода будет зависеть только от выбранного транзистора. При заряженном плавающем затворе опрашиваемый транзистор не откроется и на выходе F будет 1. При разряженном затворе транзистор открывается и на выходе схемы будет 0. Структуры с ячейками NAND более компактны, но не обеспечивают режим произвольного доступа.

140
Структура матрицы накопителя Flash-памяти на основе ячеек NOR Линии выборки слова Линии выборки разрядов Линии считывания разрядов

141
A 18-0 DQ 15/A1 DQ 14-0 CE OE WE DATA RP Reset Vcc Vpp GND Boot-Block Flash- Memory В главных блоках хранятся основные управляющие программы

142
Файловая Flash-память Файловая flash-память ориентирована на замену hard-дисков. Преимущества: сокращается потребляемая мощность; увеличивается механическая прочность и надежность; уменьшаются размеры и вес; на несколько порядков повышается быстродействие при чтении данных; сохраняется совместимость со средствами управления памятью. Преимущества дисков – информационная емкость и стоимость. Основной фактор развития файловой flash-памяти – использование в портативных компьютерах.

143
Организация ФФП Накопитель ФФП делится на блоки, которые служат аналогами секторов магнитных дисков (как в MS-DOS). Блоки идентичны и имеют одинаковую информационную емкость (симметричная блочная архитектура). Для записи введены страничные буферы, позволяющие накапливать некоторый объем данных, подлежащих записи, для их последующей передачи в накопитель с меньшей скоростью.
. Блоки идентичны и имеют одинаковую информационную емкость (симметричная блочная архитектура). Для записи введены страничные буферы, по")
144
A 20-0 DQ 15-0 CE 0 CE 1 OE WE WP BYTE RY/B Reset Vpp 3/5 GND Flash-File Memory 28F016S 32 блока по 64К Организация – 2М×16 или 4М × 8. Vcc – 3,3 или 5В. Vpp – 12В. 64 независимых блока по 64Кбайт или 32 блока по 32Кслов. Размер корпуса – 1,2×14 ×20 мм Технология – 0,6 мкм. Время доступа при чтении - 70 нс при Vcc=5В и 150 нс при Vcc= 3,5В. Время записи слова/байта не более 9 мкс. Время записи блока не более 2,1 с (байтовый режим) и 1 мс при словарном режиме. Время стирания блока – 10 с и стирания кристалла – 25,6 с.

145
Виртуальная память Виртуальная память представляет собой единое адресное пространство, в котором физическая ограниченность емкости ОП скрыта от программиста. В основе концепции виртуальной памяти лежит идея о разделении понятий адресного пространства и адресов памяти. Реально существующую ОП называют физической памятью, а ее адреса – физическими. Все адресное пространство программиста называют логической или виртуальной памятью, а ее адреса – логическими или виртуальными (Virtual – кажущийся). Максимальный размер виртуального адресного пространства ограничивается только разрядностью адреса процессора и, как правило, не совпадает с объемом физической памяти, имеющейся в компьютере. Virtual Memory > Physical memory.

146
Виртуальная память. Мотивация. 1. Возможность эффективного и безопасного использования памяти сразу несколькими программами 2. Устранение программных трудностей, связанных с ограниченностью оперативной памяти 3. Управление двумя уровнями памяти: физической памятью (ОП) и внешней памятью (диск) - функция виртуальной памяти Концепции работы виртуальной памяти и кэш-памяти одинаковы В основе - принцип локальности

147
Виртуальная память Processor Cache MMU Main Memory Magnetic Disk Storage Virtual Address Physical Address Swapping, Replacement Data MMU – memory management unit

148
Страничная организация памяти Page 0 Page 1 Page 2 Page 3 Page 4 Page 5 Page 2047 Block 0 Block 1 Block 2 Block 3 Block 63 P Номер блока Virtual Memory Physical Memory Disk

149
Translation of VA to PA (VPN to PFN) Virtual Address Frame Number Page Offset Page Number Page Offset Page Table Physical Address
 Virtual Address Frame Number Page Offset Page Number Page Offset 31... 21 20... 0 0 1 2 2047 1 11130121113012 Page Table Physical Address 28... 21 20... 0")
150
Virtual Memory: The Four Question Page placement: fully (or very highly) associative Page identification: address translation Page replacement: sophisticated (LRU + working set) Write Strategy: Write – back. Write back reduces a disk traffic. Disk is the backing store for the main memory. Memory is 50 to 100 times slower than processor. Disk is 200 to 1000 times slower than memory. Disk is 1 to 10 million times slower than processor. VA miss (VPN has no PFN) is called page fault. Page penalty is very large – to clock cycles. Page size is usually large: 4KB – 16KB, 2MB
 associative Page identification: address translation Page replacement: sophisticated (LRU + working set) Write Strategy: Write – back. Write back reduces a disk traffic. Disk is")
151
Flow Chart for Virtual Memory system with Cache Memory Processor forms VA Translation VA to PA Is the page in a memory? Cache hit? Yes No Yes No Update Cache Send data to address Page Fault MMU The next stage of instruction execution

152
Flow Chart (2) Is main memory full? Read the page from disk to memory No Yes Page table update Return to instruction that was halted Exercise memory replacement algorithm Was the page updated? No Yes Write the page from memory to disk Page table update Entry of Page Fault routine
 Is main memory full? Read the page from disk to memory No Yes Page table update Return to instruction that was halted Exercise memory replacement algorithm Was the page updated? No Yes Write the page from memory to disk Page table upda")
153
Page Tables (PT) Page tables are usually so large that are stored in main memory (OS forms page tables for each process). A page table is an array of PTEs (Page Table Entries). PT Root PVN PTE Page Table P PFN D R/W A PTE format P – Present D – Dirty R/W – Write protection A – Accessed
 Page tables are usually so large that are stored in main memory (OS forms page tables for each process). A page table is an array of PTEs (Page Table Entries). PT Root PVN PTE Page Table P PFN D R/W A PTE format P – Present D – Dirty")
154
Структура таблицы страниц и карты файла PDR/WAНомер блока Номер цилиндра, дорожки и сектора Таблица страниц Карта файла Номер страницы N-1 Подкачка страниц по обращению (Demand Paging). Стратегии замещения страниц – FIFO, LRU. Размер страницы?
. Стратегии замещения страниц – FIFO, LRU. Размер страницы?")
155
Virtual Memory for Different Processes VP1 VP2 0 N-1 VP1 VP2 0 N-1 Process i Process j Virtual address space Physical memory Common page frame 0 M-1

156
Page Table Size The page size is inversely proportional to the page table size. Example 1: 32-bit VA, 4 KB pages, 4-byte PTE. 1M pages (4Gbyte/4Kbyte = 2 20 pages) 1M*4bytes = 4Mbyte – page table size (it is very large, but can be more). Example 2: 64-bit VA, 4KB pages, 4-byte PTE. 4 P pages (2 64 /2 12 =2 52 pages) 16 P bytes – page table size (it is impossible to realize). The methods to reduce page size: multi-level page tables inverted page tables
 1M*4bytes = 4Mbyte – page table size (it is very large, but can be more). Example 2: 6")
157
1. Применение лимитирующего регистра Лимитирующий регистр ограничивает размер таблицы страниц. Если номер страницы становится больше, чем содержимое лимит. регистра, то добавляют новые записи. Таблица страниц будет большой только в случае, если процесс использует много страниц. Недостаток: рост таблицы страниц только в одном направлении. 2. Применение двух сегментов: один для программы, другой для стека. Сегменты пользователю не видны. Плохо работает, когда адресное пространство используется вразброс. Сокращение объема памяти для хранения таблиц страниц (1)

158
Сокращение объема памяти для хранения таблиц страниц (2) 3. Обработка виртуального адреса хэш-функцией. В этом случае размер таблицы страниц равен размеру физической памяти (Inverted Page Table) 4. Многоуровневые таблицы страниц. Метод позволяет использовать адресное пространство вразброс. Используется для очень больших адресных пространств. Недостаток – сложность трансляции адреса. 5. Страничная организация таблиц страниц. Часть таблиц размещается на диске. Часть страниц – в области OS. Некоторые – в опративной памяти.
 3. Обработка виртуального адреса хэш-функцией. В этом случае размер таблицы страниц равен размеру физической памяти (Inverted Page Table) 4. Многоуровневые таблицы страниц. Метод позволяет испо")
159
Multi-level Page Tables Use tree of page tables. Example: two-level organization in Intel processors. Directory Table Offset data PTE PDE PDBR PA 1 st level table 2 nd level table 1 st level table (PDEs) points the 2-level table. 2 nd level table (PTEs) points data. + - save memory space. - - slow (multi-hop chain of translations). Alpha has three level of page tables.
 points the 2-level tabl")
160
Inverted Page Tables Alternative approach: PVN maps by hash function on hash table, that contains pointer to inverted page frame. Advantages: Dont need more PTEs that physical memory pages. Can appear collisions (more than one PVN use the same element of hash table). In this case chained list is used. PVN Offset PVN 2 PTE Pointer PVN 1 PTE Pointer Hash Function PFN Offset

161
Translation Look-Aside Buffer (1) Page Number (PVN) Offset Virtual Address Page Number Block Number Control (PFN) bits =?=? Hit Miss No Yes Block Number (PFN) Offset TLB Physical Address
 Page Number (PVN) Offset Virtual Address Page Number Block Number Control (PFN) bits =?=? Hit Miss No Yes Block Number (PFN) Offset TLB Physical Address")
162
TLB (2) Page Number (PVN) Offset Virtual Address Block Number (PFN) Offset TLB Physical Address = Tag PVN1 PVN2 PVN3 PVN K V D R/W A Block Number (PFN)
 Page Number (PVN) Offset Virtual Address Block Number (PFN) Offset TLB Physical Address = Tag PVN1 PVN2 PVN3 PVN K V D R/W A Block Number (PFN)")
163
Translation Look-Aside Buffer (3) Paging means, that every memory access logical takes at least twice as long, with one memory access to obtain the physical address and second access to get the data. Fast address translation: solution – to again rely on the principle of locality. The usage of TLB is allowed to decide this problem. TLB – usually fully associative cache for PTE. TLB miss: entry not in TLB, but in page table (soft miss) Not quite a page fault (no disk access necessary). Page fault: entry not in TLB and not in page table.
 Paging means, that every memory access logical takes at least twice as long, with one memory access to obtain the physical address and second access to get the data. Fast address translation: solution – to again rely")
164
TLB (4) Control bits Tag Page Frame Number V VPN Physical Memory Page Table TLB Disks TLB Hit TLB Miss
 Control bits Tag Page Frame Number V VPN 1 1 0 0 1 1 1 0 1 1 0 0 1 2 3 4 5 6 7 8 0 5 1 4 8 9 10 11 12 13 14 15 8 8 0 12 5 0 10 11 1 14 4 2 1 7 9 Physical Memory Page Table TLB Disks TLB Hit TLB Miss")
165
Обработка промахов при обращении к TLB и Page Table Промах при обращении к TLB: 1. Страница присутствует в оперативной памяти 2. Страницы нет в памяти Промах при обращении к TLB может быть обработан как аппаратно, так и программно (через прерывание) При отсутствии страницы в памяти OS выполняет следующее: По виртуальному адресу обращается к ТС и определяет адрес страницы на диске Если нет места в ОП, выбирает, какую страницу удалить. Использует алгоритм LRU (LRU использует бит A - accessed) Если страница подвергалась изменениям, то она записывается на диск Требуемая страница читается с диска Обновляется таблица страниц
")
166
1.L1 Cache 2.L2 Cache 3. Main Memory 4. TLB 1. Кэш для кэш-памяти 2. Кэш для дисков 3. Кэш для оперативной памяти 4. Кэш для таблицы страниц

167
1.L1 Cache 2.L2 Cache 3. Main Memory 4. TLB 1. Кэш для кэш-памяти 2. Кэш для дисков 3. Кэш для оперативной памяти 4. Кэш для таблицы страниц

168
Оптимизация программ 1. Оптимизация программ под кэш-память Основная идея – повторное использование всех данных в блоке до того, как он будет заменен при кэш-промахе 2. Производительность при страничной организации Если программа регулярно обращается к объему виртуальной памяти, превышающему объем ОП, она будет работать очень медленно (постоянный свопинг – пробуксовка). Простое решение – увеличить память. Более сложно пересматривать алгоритм. Промахи при обращении к TLB также сильно снижают производительность программы. Большинство современных архитектур поддерживают страницы разного размера. Это дает возможность сократить рабочий набор страниц.

169
Взаимодействие аппаратных средств и ОС Процессор формирует адрес ОП Формирование физического адреса Страница в ОП? Адресуемый блок в Cache? да нет да нет Обращение к ОП, занесение в Cache Обращение к Cache Прерывание (Page Fault) MMU Переход к след. этапу
 MMU Переход к след.")
170
Обработка страничного прерывания Есть свободный блок в ОП? Занесение в ОП требуемой страницы с диска да нет Коррекция таблицы страниц Возврат в прерванную программу Определение удаляемой страницы Были ли записи в удаляемую страницу? нет да Перенесение страницы на диск Коррекция таблицы страниц

171
Размер страницы. Стратегия замещения страниц Выбор размера страницы. Размер страницы обратно пропорционален размеру таблицы страниц. В TLB будет содержаться информация о бOльшем объеме виртуальной памяти. Но увеличивается внутренняя фрагментация. Стратегии замещения страниц в ОП: FIFO, LRU – критерий выбора – число обращений к странице за последний период времени. ОС ведет счетчик для каждой страницы. Иногда используют случайный выбор. Увеличение интенсивости страничного обмена компенсируется снижением вычислительных затрат на поддержание и анализ критерия выбора.

172
Сегментная организация памяти Сегментацией называется разделение адресного пространства на части (сегменты) по логическим признакам, устанавливаемым программистом. Сегмент – это блок пространства памяти определенного назначения. Сегмент может соответствовать программе, подпрограмме,стеку, данным и, в отличие от страницы, имеет переменную длину. Каждый сегмент представляет собой линейное адресное пространство, максимальный адрес которого ограничивается длиной сегмента. Различные сегменты могут иметь разную длину. Информация разных типов, как правило, в сегмент не включается. Виртуальный адрес состоит из номера сегмента и относительного адреса в пределах сегмента. Виртуальное адресное пространство становится двумерным. Преобразование виртуального адреса в физический осуществляется с помошью таблицы сегментов.
 по логическим признакам, устанавливаемым программистом. Сегмент – это блок пространства памяти определенного назначения. Сегмент может соответ")
173
S0 S1 S2... S k S2 S1 S k 0 Базовый адрес Длина Механизм сегментации не является прозрачным для программиста. С учетом того, что сегмент является самостоятельной логической единицей, можно организовывать защиту информации на уровне сегментов. Сегментация упрощает совместное использование данных несколькими процессорами.

174
Схема преобразования виртуального адреса в физический Номер сегмента Смещение 0 1 Базовый адрес Длина + Виртуальный адрес Физический адрес (Адрес ОП) Трудности управления сегментированной памятью – из-за разной длины сегментов возникает проблема внешней фрагментации. Производят уплотнение информации в ОП. Применение сегментно-страничной организации позволяет преодолеть недостатки обоих способов.
 Трудности управления сегментированной памятью – из-за разной длины сегментов возникает проблема внеш")
175
Intel Pentium Segmentation Virtual Address Seg SelectorOffset Segment Descriptor Segments Main Memory

176
Сегментно-страничная организация SegmentOffset Directory Page Offset ОП Виртуальный адрес Линейный адрес Физический адрес Механизм сегментации Механизм страничного преобразования

177
FIFO-буфер FIFO-память представляет собой ЗУ для хранения очередей данных, с порядком выборки таким же, что и порядок их поступления. Обычно используется как буферная память. Запись в буфер и чтение из него осуществляются внешними независимыми сигналами управления. Возможность иметь разный темп приема и выдачи информации необходима в очень многих ситуациях. В частности, ядро суперскалярных процессоров содержит переупорядочивающий циклический FIFO-буфер (ROB), в который помещаются декодированные команды, затем команды исполняются неупорядоченным ядром процессора по мере готовности операндов и результаты помещаются обратно в буфер; выполненные команды извлекаются из ROB в порядке их поступления устройством завершения выполнения комaнд.

178
A WR WR RD A RD +1 R +1 R SRSR = & & DI DO Сброс WR RD Буфер пуст Буфер полон CT W CT R

179
Перед началом работы оба счетчика CT W и CT R сбрасываются. После записи очередного слова содержимое CT W увеличивается на единицу. После чтения содержимое CT R увеличивается на единицу. То есть при каждом обращении адреса возрастают, начиная с нулевого. Адрес чтения всегда стремится догнать адрес записи. Если адреса сравняются при записи, значит буфер полон. Если адреса сравняются при чтении – буфер пуст. Если буфер полон, то нужно прекратить прием данных, если буфер пуст, то нужно прекратить чтение. Буфер является циклическим, так как переходе через нуль адреса повторяются с нуля.

Еще похожие презентации в нашем архиве:



 – микросхема, которая обрабатывает информацию и управляет всеми устройствами.")
 Пластина 1 Пластина 2 Цилиндр 0 сторона Диск – одна или несколько.")






 организации памяти заключается в использовании на одном компьютере нескольких.")
 организации памяти заключает- ся в использовании на одном компьютере.")




")
. Постоянное запоминающее устройство ПЗУ, не.")


 Составил учитель ИКТ Фоломкин А.И.")
