Скачать презентацию
1
Об одном методе решения задачи периодического тематического поиска информации в Web Алексей Максаков

2
Периодическая доставка информации Периодический тематический поиск в Web Подписка на тематические издания Высокое качество информации Низкая оперативность Низкая полнота информации Высокая оперативность поиска Высокая полнота информации Низкое качество результатов поиска WEB

3
Области применения При наличии потребности в периодическом поиске специализированной информации: В системах непрерывного обучения Для тематического мониторинга в рамках профессиональной деятельности: Наблюдение за развитием области отзывами потребителей состоянием рынка В научных исследованиях

4
Особенности задачи Свойства пространства поиска (Web): Динамичность Большой объем доступной информации Следствие: наличие ограничений на вычислительную сложность используемых алгоритмов Свойства информационной потребности: Информационная потребность пользователя имеет определенную тематическую направленность и слабо изменяется со временем Поиск носит периодический характер Следствие: с практической точки зрения оправдано подробное описание информационной потребности
: Динамичность Большой объем доступной информации Следствие: наличие ограничений на вычислительную сложность используемых алгоритмов Свойства информационной потребности: Информационная потребность")
5
Возможные способы решения задачи периодического ИП в Web (?) Периодическое выполнение запросов к СПКС [Google Alerts, NorthernLight Search Alerts] –высокая полнота –относительно низкая точность поиска Периодический обход подмножества Web –Низкая полнота поиска –Высокая оперативность –Качество поиска зависит от выбора способа фильтрации Отслеживание обновлений в тематических каталогах –высокая релевантность документов теме –низкая полнота и оперативность –в тематических каталогах используется жесткая иерархия каталогов, которая может не содержать интересующей пользователя темы
![Возможные способы решения задачи периодического ИП в Web (?) Периодическое выполнение запросов к СПКС [Google Alerts, NorthernLight Search Alerts] –высокая полнота –относительно низкая точность поиска Периодический обход подмножества Web –Низкая полн](http://images.myshared.ru/17/1036478/slide_5.jpg "Возможные способы решения задачи периодического ИП в Web (?) Периодическое выполнение запросов к СПКС [Google Alerts, NorthernLight Search Alerts] –высокая полнота –относительно низкая точность поиска Периодический обход подмножества Web –Низкая полн")
6
Предложенный подход решения задачи Запрос пользователя представляется в виде обучающей выборки и запроса по ключевым словам Процесс поиска состоит из двух этапов: I. Отбор документов из Web с помощью СПКС II. Уточнение результатов поиска с помощью классификатора, обученного на предоставленной пользователем выборке Данный подход сочетает преимущества поиска с помощью СПКС и классификации текстов следующим образом: Отбор документов с помощью запросов к СПКС обеспечивает высокую полноту поиска и сокращает объем анализируемой информации Использование классификатора обеспечивает высокую релевантность полученных пользователем документов

7
Схема работы предложенного подхода Система периодического тематического поиска Задает обучающую выборку Обучающая выборка Генератор запросов по КС Классификатор Возвращает ссылки на релевантные документы - запрос по КС - обучающая выборка - гиперссылки на документы - набор документов Возвращает сгенерированный запрос по КС Запрос по КС множество анализируемых документов таймер Web СПКС Отбор документов Web

8
Показатели качества поисковой системы

9
Алгоритмы классификации Требования к алгоритмам классификации в рамках предложенного подхода: высокая точность и полнота результатов классификации низкая вычислительная сложность классификации (необходимость обработки большого объема данных) низкая вычислительная сложность обучения (для обеспечения обратной связи в многопользовательской системе) Типы задач классификации: Бинарная (С=2) Используется для уточнения результатов поиска Мультиклассовая (С>2) Используется для внутренней рубрикации
 низкая в")
10
Модификация наивного алгоритма Байеса Недостатки наивного алгоритма Байеса: –Предпочтение классов с большим количеством примеров –Предпочтение классов с большим количеством устойчивых словосочетаний Предлагаемые решения: –Реверсирование –Нормализация весов признаков

11
Алгоритм ModFisher. Обучение Идея алгоритма заключается в построении нескольких гиперплоскостей, вдоль нормалей к каждой из которой документы разных классов максимально разнесены Описание алгоритма обучения: 1. Методом градиентного подъема находим локальный максимум индекса Фишера. 2. Сортируем все документы по значению их проекции на полученное направление (вектор) 3. Отбрасываем область только положительных (отрицательных) документов с краев направления. 4. Запоминаем направление, точки отсечения положительных и отрицательных документов, а также оптимальную точку их разделения (по F- мере) 5. Если осталось более 2 документов, повторяем процесс от шага 1 с оставшимися документами D2D2 D1D1 E2E2 E1E1

12
Алгоритм ModFisher. Классификация Вариант 1: Проверка по областям отсечения для каждого направления. - Если тестовый документ попадает в область отсечения, то выдаем ему соответствующую метку и выходим из алгоритма. - Если документ не попал в область отсечения до последнего направления, используем оптимальную точку разделения для определения класса Вариант 2: Использование другого алгоритма классификации на новом векторном пространстве. В ходе экспериментов вариант 1 показал лучшие результаты (более 8% для набора ROMIP-Legal для алгоритма C4.5)

13
Нахождение дискриминанта Фишера. где

14
Алгоритм ModSimpl. Анализ Эффективно решает задачу бинарной классификации (сравнимо с SVM, превосходит алгоритм Байеса) Более высокая скорость обучения алгоритма по сравнению с SVM O(m*n + n*log(n)) против O(m*n a ) операций, где a ~ Алгоритм является масштабируемым по оперативной памяти: требуется O(n+m) ячеек При обучении на большом количестве классов точность классификации ниже, чем у модифицированного алгоритма Байеса.
 Более высокая скорость обучения алгоритма по сравнению с SVM O(m*n + n*log(n)) против O(m*n a ) операций, где a ~ 1.7-1.9 Алгоритм")
15
Методика оценки качества работы алгоритмов классификации Тестовые наборы данных для оценки качества алгоритмов Коллекция ОписаниеКоличество классов Количество документов Newsgroup-20Группы обсуждений в Usenet ROMIP-Legal Коллекция нормативно- правовых документов Reuters-21578Новостные сообщения Reuters 90(10)12902 OHSUMEDАннотации медицинских статей

16
Сравнение алгоритмов

17
Качество решения задачи бинарной классификации

18
Выводы(?) За критерий оптимальности алгоритма принимается отношение точности классификации к вычислительной сложности обучения В случае малого объема обучающей выборки предпочтительно использование алгоритма SVM Модифицированный алгоритм наивного алгоритма Байеса предпочтительнее для решения задачи классификации в случае наличия в обучающей выборке большого количества не равно мощных классов Алгоритм ModSimpl предпочтительнее для решения задачи бинарной классификации при большом объеме обучающей выборки Алгоритм ModSimpl слабо устойчив к наличию ошибок в обучающей выборке
 За критерий оптимальности алгоритма принимается отношение точности классификации к вычислительной сложности обучения В случае малого объема обучающей выборки предпочтительно использование алгоритма SVM Модифицированный алгоритм наивного алг")
19
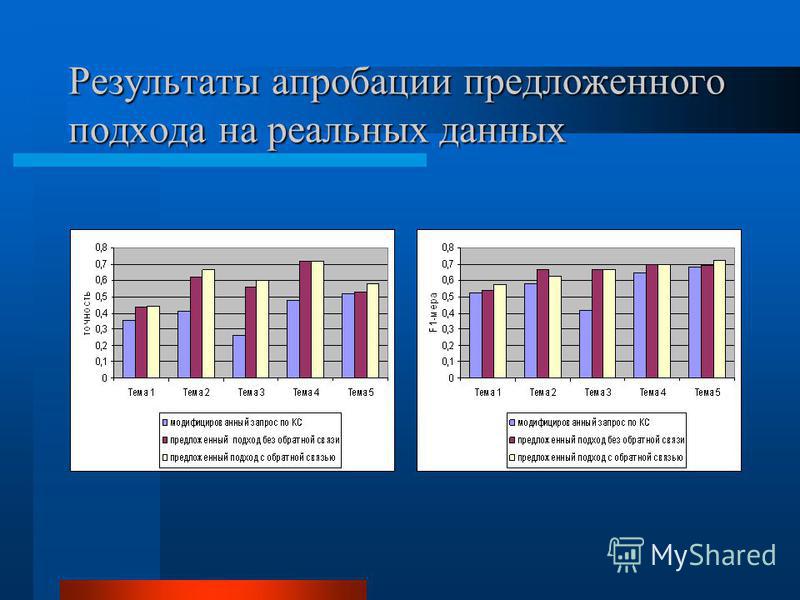
Апробация предложенного подхода. Методология Анализируемое множество документов: –Реальные данные Web, проиндексированные СПКС Google –Обновления в индексе СПКС AllTheWeb за 2 недели Оцениваемые показатели: –точность, мера F1 Характеристики обучающей выборки: –30 примеров релевантных документов –Общая для всех тем коллекция нерелевантных документов + 15 примеров нерелевантных документов Темы поиска: –Локальные поисковые системы –Способы сопоставления признаков документам –Анализ рынка недвижимости Москвы –Настройка подвески велосипеда –Имитационное моделирование распределенных систем

20
Результаты апробации предложенного подхода на реальных данных

22
Спасибо за внимание